默认安装路径:/var/lib/clickhouse/
目录结构:
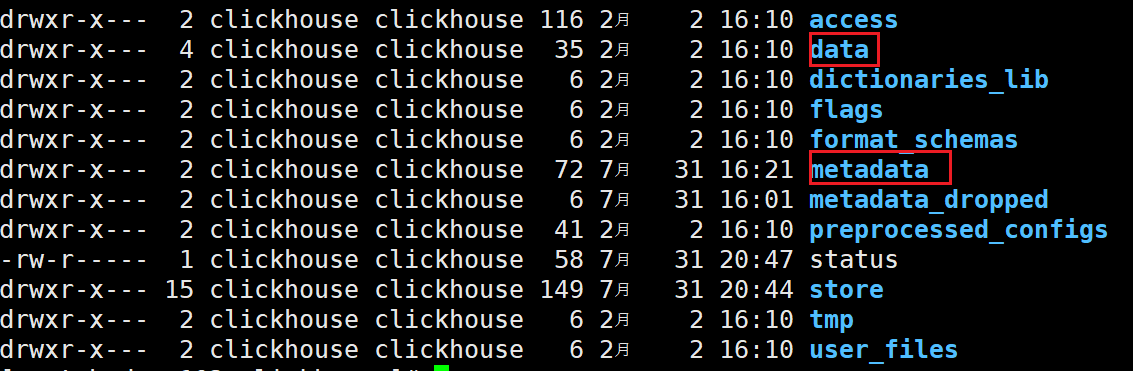
主要介绍metadata和data
metadata

其中的default、system及相应的数据库,.sql文件即数据库创建相关sql语句
进入default数据库(默认数据库):
可以看到数据库中已有表所对应的sql语句:

查看t_order_mt.sql:
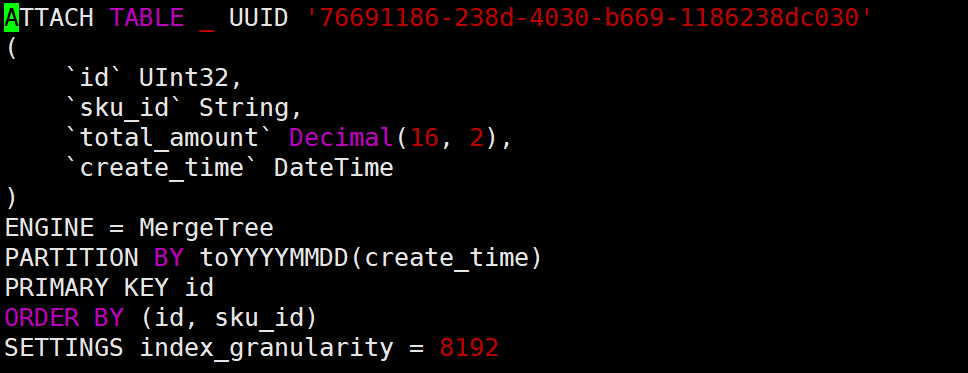
其中ATTACH即“装载”,使该sql语句生效;
index_granlarity即索引粒度(因为clickhouse是稀疏索引)
data
data文件夹中存储着具体的数据
进入后首先看到的是数据库:

进入默认数据库:
可以看到创建的两张表:

进入t_order_mt:

其中detached即“卸载”,与attach对应;
20200601_1_1_0和20200602_2_2_0即分区数据
以20200601_1_1_0为例,其中20200601是分区字段,而后面的_1_1_0分别是最小编号,最大编号和合并等级
分区文件命名规则
以t_order_mt为例:

命名规则如下:
PartitionId_MinBlockNum_MaxBlockNum_Level
分区值_最小分区块编号_最大分区块编号_合并层级
详细含义如下:
-
PartitionId(数据分区ID)生成规则:
数据分区规则由分区ID决定,分区ID由PARTITION BY分区键决定。根据分区键字段类型,ID生成规则可分为:
未定义分区键
没有定义PARTITION BY,默认生成一个目录名为all的数据分区,所有数据均存放在all目录下
整型分区键
分区键为整型,那么直接用该整型值的字符串形式做为分区ID
日期类分区键
分区键为日期类型,或者可以转化成日期类型
其他类型分区键
String、Float类型等,通过128位的Hash算法取其Hash值作为分区ID
- MinBlockNum:最小分区块编号,自增类型,从1开始向上递增。每产生一个新的目录分区就向上递增一个数字。
- MaxBlockNum:最大分区块编号,新创建的分区MinBlockNum等于MaxBlockNum的编号。
- Level:合并的层级,被合并的次数。合并次数越多,层级值越大
分区目录介绍
进入20200601_1_1_0目录,有以下文件:
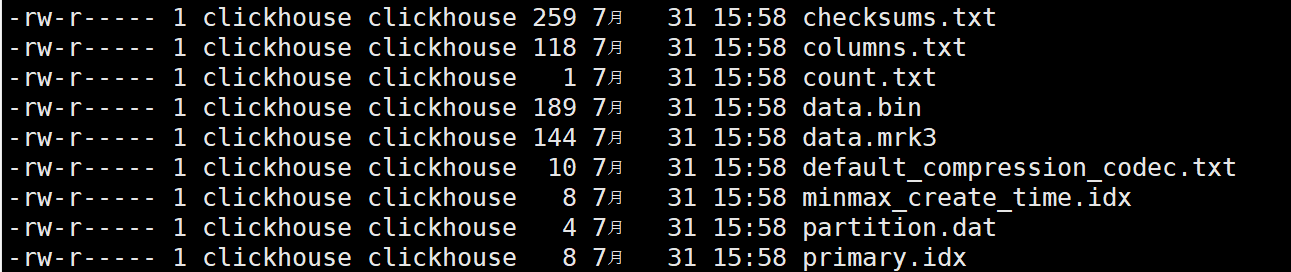
checksums.txt:校验文件,用于校验各个文件的正确性。存放各个文件的size以及hash值
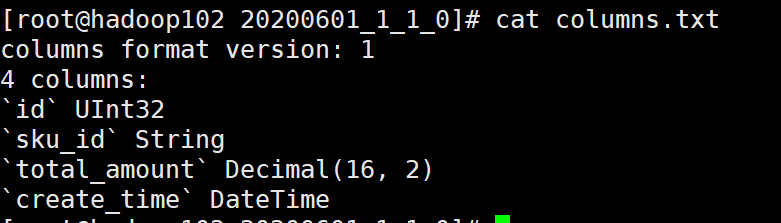
columns.txt:列信息,可以查看列名以及列属性:
count.txt:列数;
![]()
data.bin:数据文件
data.mrk3:标记文件(标记文件在 idx索引文件 和 bin数据文件 之间起到了桥梁作用,一般是记录了列的偏移量)
default_compression_codec.txt:默认数据压缩格式
![]()
primary.idx:主键索引,用于加快查询效率
partition.dat:分区信息
minmax_create_time.idx:分区键的最大最小值