
进NLP群—>加入NLP交流群
为了促进开源LLMs的工具使用能力,作者引入了 ToolLLM,这是一个数据构建、模型训练和评估的通用工具使用框架。

论文:ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
地址:https://arxiv.org/abs/2307.16789
项目:https://github.com/OpenBMB/ToolBench
单位:清华、人大、耶鲁、微信、腾讯、知乎
尽管开源大语言模型 (LLM) 及其变体(例如 LLaMA 和 Vicuna)取得了进步,但它们在执行更高级别的任务方面仍然受到很大限制,例如遵循人类指令使用外部工具 (API)。
这是因为当前的指令调优主要集中在基本语言任务而不是工具使用领域。
这与最先进 (SOTA) 的LLMs(例如 ChatGPT)形成鲜明对比,后者展示了出色的工具使用能力,但不幸的是闭源的。
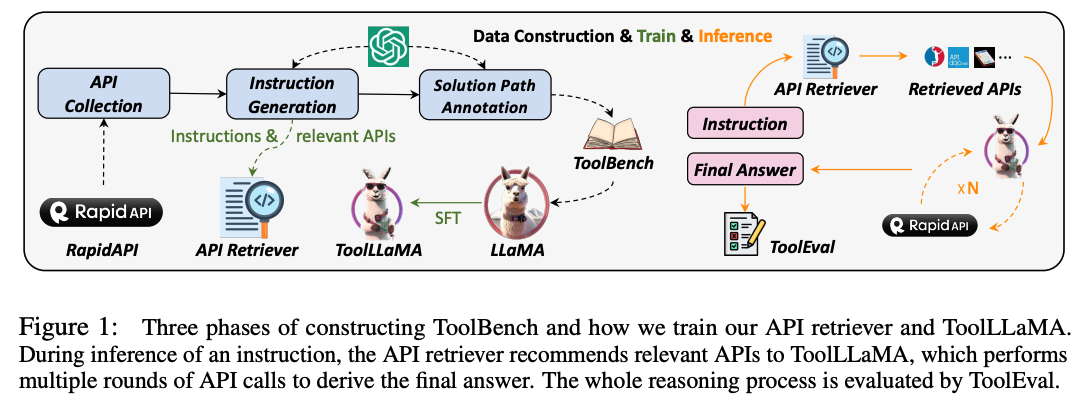
为了促进开源LLMs的工具使用能力,我们引入了 ToolLLM,这是一个数据构建、模型训练和评估的通用工具使用框架。
我们首先介绍 ToolBench,这是一个供工具使用的指令调整数据集,它是使用 ChatGPT 自动创建的。
具体来说,我们从 RapidAPI Hub 收集了 16,464 个真实世界的 RESTful API,涵盖 49 个类别,然后提示 ChatGPT 生成涉及这些 API 的各种人工指令,涵盖单工具和多工具场景。
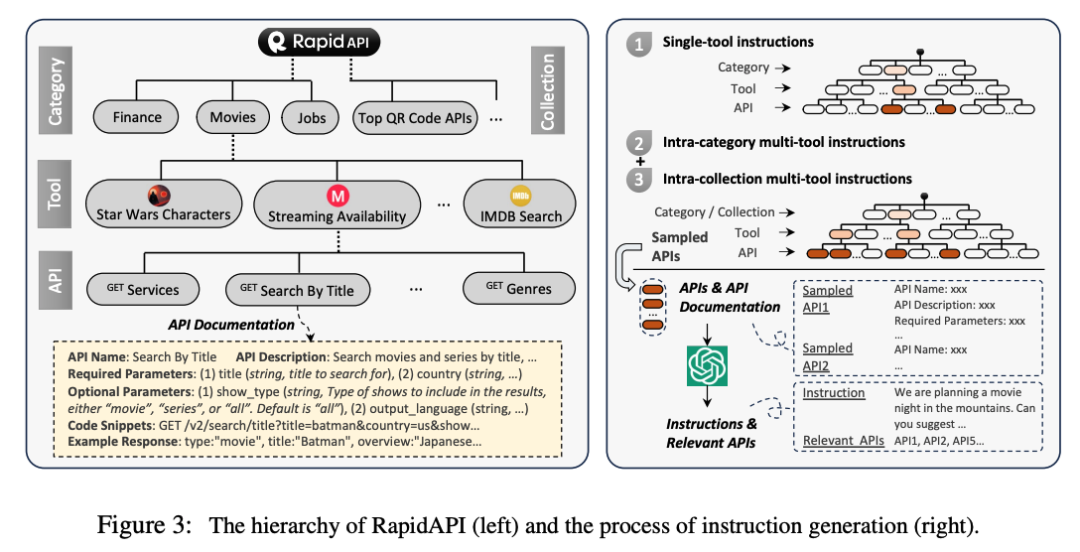
最后,我们使用 ChatGPT 为每条指令搜索有效的解决方案路径(API 调用链)。
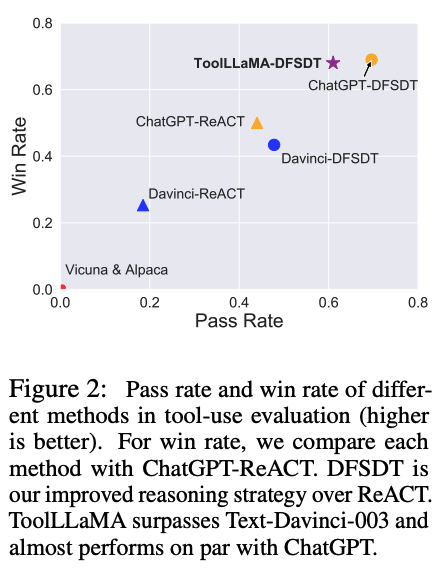
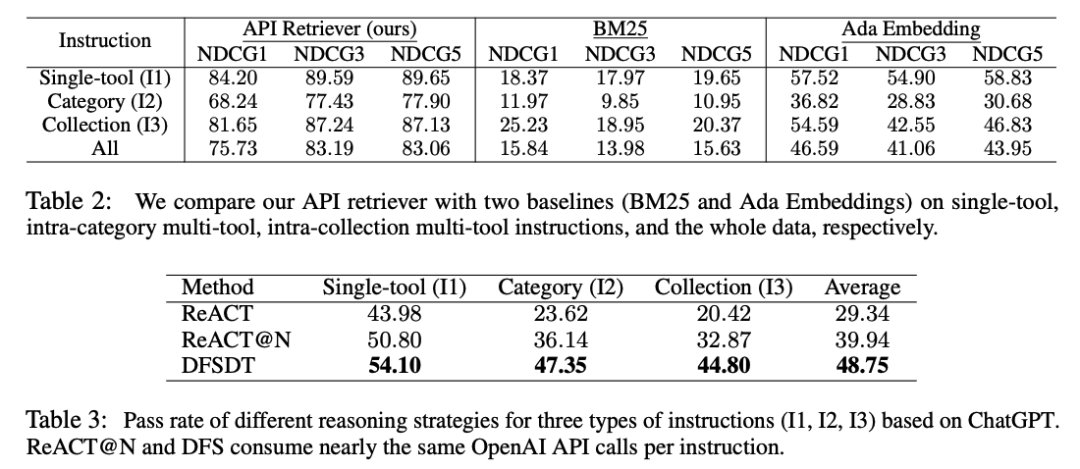
为了使搜索过程更加高效,我们开发了一种新颖的基于深度优先搜索的决策树(DFSDT),使LLMs能够评估多个推理轨迹并扩展搜索空间。我们证明 DFSDT 显着增强了LLMs的规划和推理能力。

为了有效评估工具使用情况,我们开发了一个自动评估器:ToolEval。

我们在ToolBench上微调LLaMA并获得ToolLLaMA。
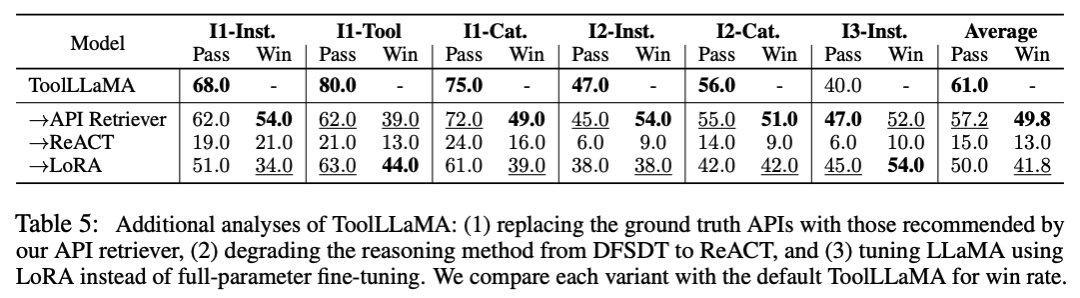
我们的 ToolEval 表明 ToolLLaMA 表现出执行复杂指令和泛化到未见过的 API 的卓越能力,并且表现出与 ChatGPT 相当的性能。

为了使管道更加实用,我们设计了一个神经 API 检索器来为每条指令推荐合适的 API,从而无需手动选择 API。

进NLP群—>加入NLP交流群