常用的数据无量纲方法
常用的数据无量纲方法都有什么?
1.min-max归一化
该方法是对原始数据进行线性变换,将其映射到[0,1]之间([-1,1]之间也行)。
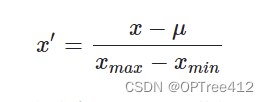
def Min_Max_Scaler(X,feature_range=(0,1),axis=0):
'''
最大最小归一化
:param X: data
:param feature_range: 选择的特征区间[0,1],其他值也行
:param axis: 数据方向, axis=0 为列,axis=1 为行
:return:
'''
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (feature_range[1] - feature_range[0]) + feature_range[0]
return X_scaled
优点:
- 可以去除量纲
- 如果某特征的方差很小,数据之间的差异不明显,通过归一化可以把数据之间的差异放大。
- 维持稀疏矩阵中为0的条目。
- 如果想保留原始数据中由标准差所反映的潜在权重关系应该选择min-max归一化
缺点:
- 由于最大值与最小值可能是动态变化的,同时也非常容易受噪声(异常点、离群点)影响,因此一般适合小数据的场景。
2.z-score标准化
z-score标准化也叫标准差标准化,代表的是分值偏离均值的程度,经过处理的数据符合标准正态分布,即均值为0,标准差为1。是重新创建一个新的数据分布的方法。
其中,x是原始数据,u是样本均值,σ是样本标准差。
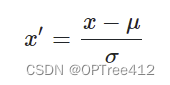
该方法假设数据是正态分布,但这个要求并不十分严格,如果数据是正态分布或者数据量很大的时候,则该技术会更有效。
优点:
- z-score标准化更加注重数据集中样本的分布状况。由于具有一定的样本个数,所以出现少量的异常点对于平均值和标准差的影响较小,因此标准化的结果也不会具有很大的偏差。
- 不仅能够去除量纲,还能够把所有维度的变量一视同仁(因为每个维度都服从均值为0、方差1的正态分布)
缺点:
- Z-Score方法是一种中心化方法,会改变原有数据的分布结构,不适合用于对稀疏数据做处理。
- 一旦原始数据的分布不接近于一般正态分布,则标准化的效果会不好。