以情感分析的例子来进行剖析transformers里的AutoTokenizer和AutoModel:
通过ipython进行查看sentiment-analynise依赖的Hugging Face – The AI community building the future.We’re on a journey to advance and democratize artificial intelligence through open source and open science.![]() https://huggingface.co/
https://huggingface.co/
里的库:
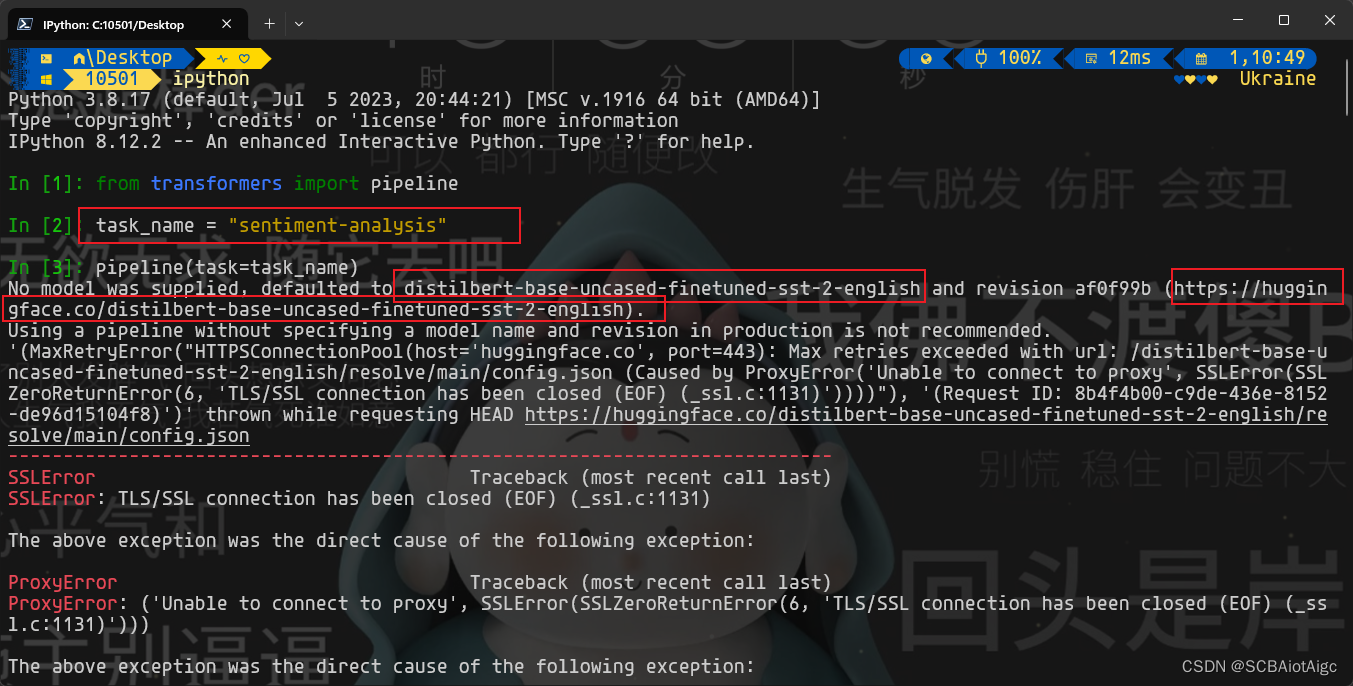
从上面的输出得到了pipeline模式进行预训练所用到的库:
distilbert-base-uncased-finetuned-sst-2-english

AutoTokenizer的原理解释:
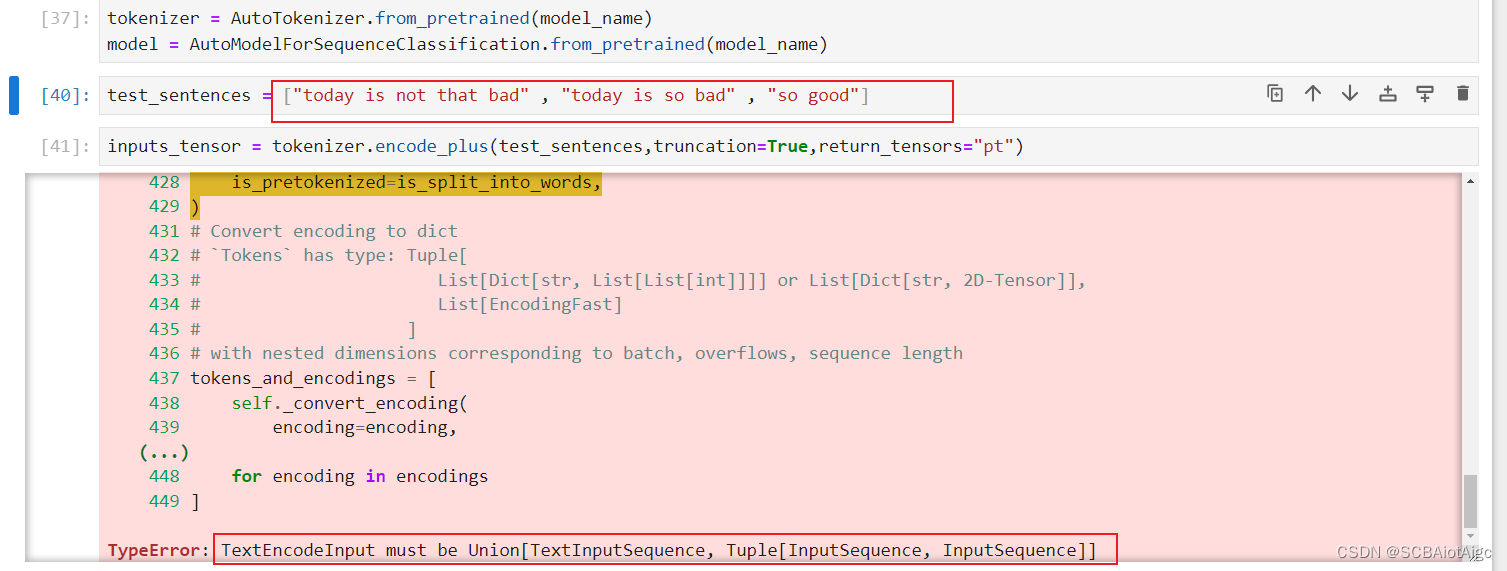
如果
test_sentences = ("today is not that bad", "today is so bad" , "so good")里面有三个元素,则会报错。
因为
inputs_tensor = tokenizer.encode_plus(test_sentences, padding=True, truncation=True, return_tensors="pt")
里的句子必须是一个或者Tuple()里面两个元素!!!

而

使用tokenizer()则不会报错!!!
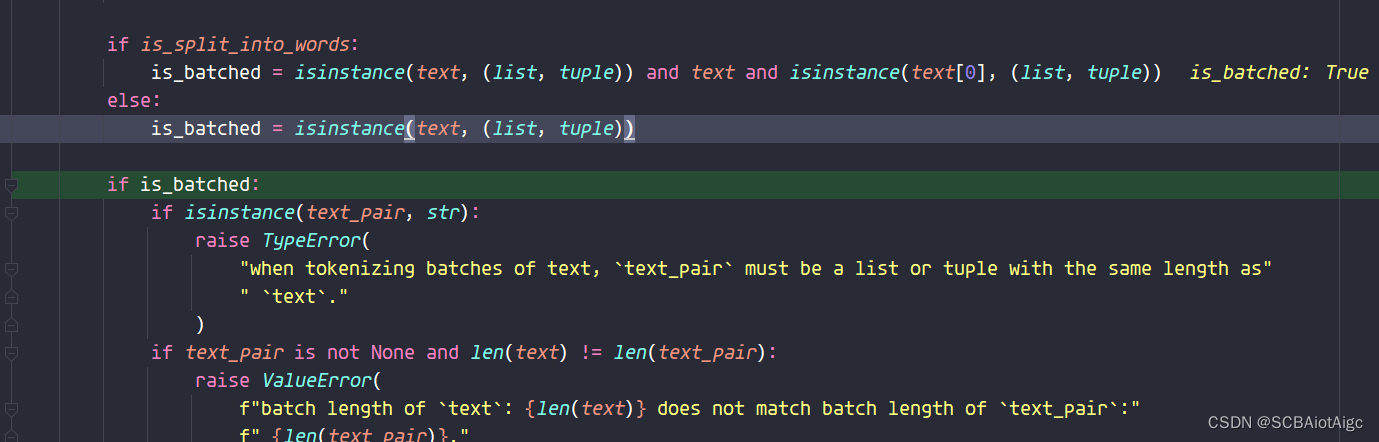
底层代码分析后,发现:
当输入为一个字符串,则tokenizer() == tokenizer.encode_plus();
当输入的是list或者tuple,则tokenizer() == tokenizer.batch_encode_plus()

这里解释一下padding=True和padding="max_length"的区别:
padding=True:
test_sentences = ("today is not that bad", "today is so bad", "so good")表示当
test_sentences里面的所有句子长度不同时,padding会以最长的句子长度作为max_length进行填充[PAD],即补零。
padding="max_length":
test_sentences = ("today is not that bad", "today is so bad", "so good")padding="max_length"一般配合max_length=XXXX 参数使用,以max_length长度进行补零。
解释一下tokenizer.batch_encode_plus() 或者 tokenizer.encode_plus()的返回值:
input_ids:表示tokenizer编码后的vocab对应的id
attention_mask:其中的1表示未被padding的词,0表示被padding的词。
与tokenizer.batch_encode_plus() 或者 tokenizer.encode_plus()的底层语句:
tokenizer.convert_tokens_to_ids(tokenizer.tokenize(test_sentences[0]))
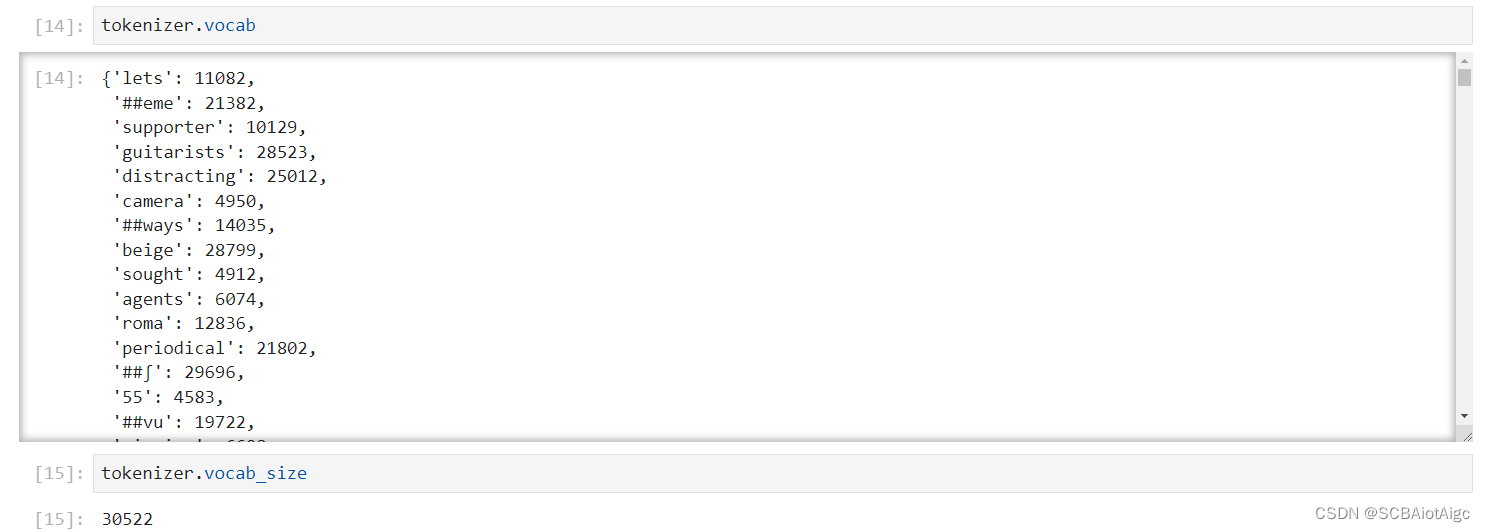
查看tokenizer里的词库:
AutoModel的原理解释:
这里使用的是:AutoModelForSequenceClassification

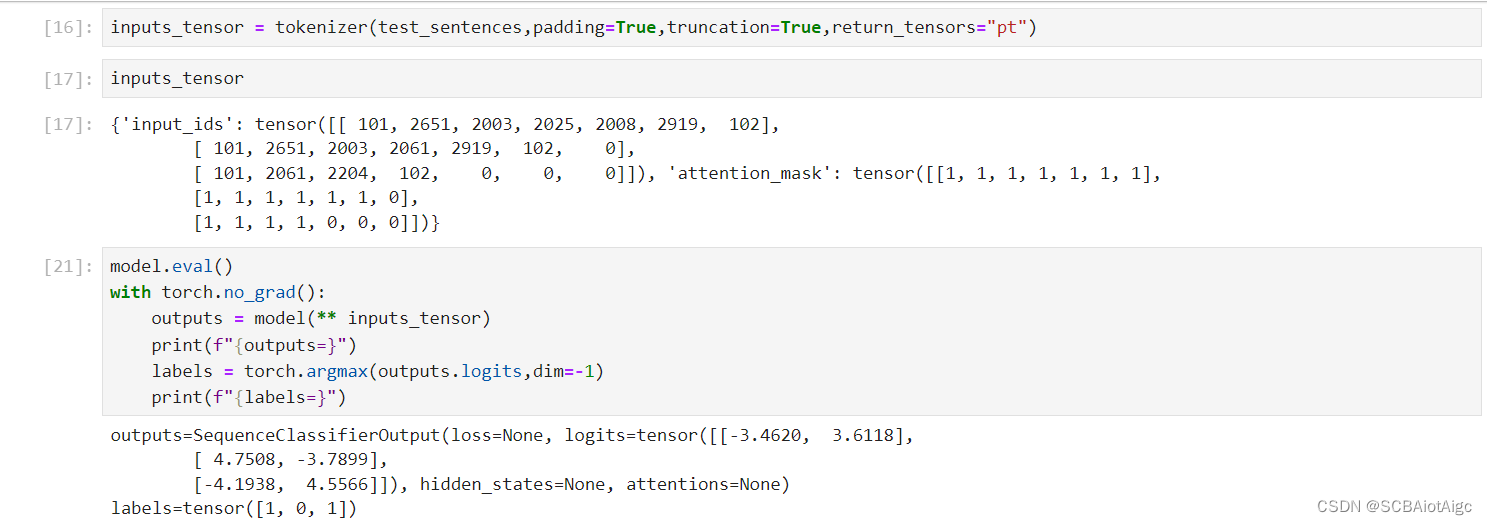
返回值logits是维度为(3,2)的tensor,我们处理一下就得到了[1,0,1],
[1,0,1]代表什么呢?
我们看它的config:
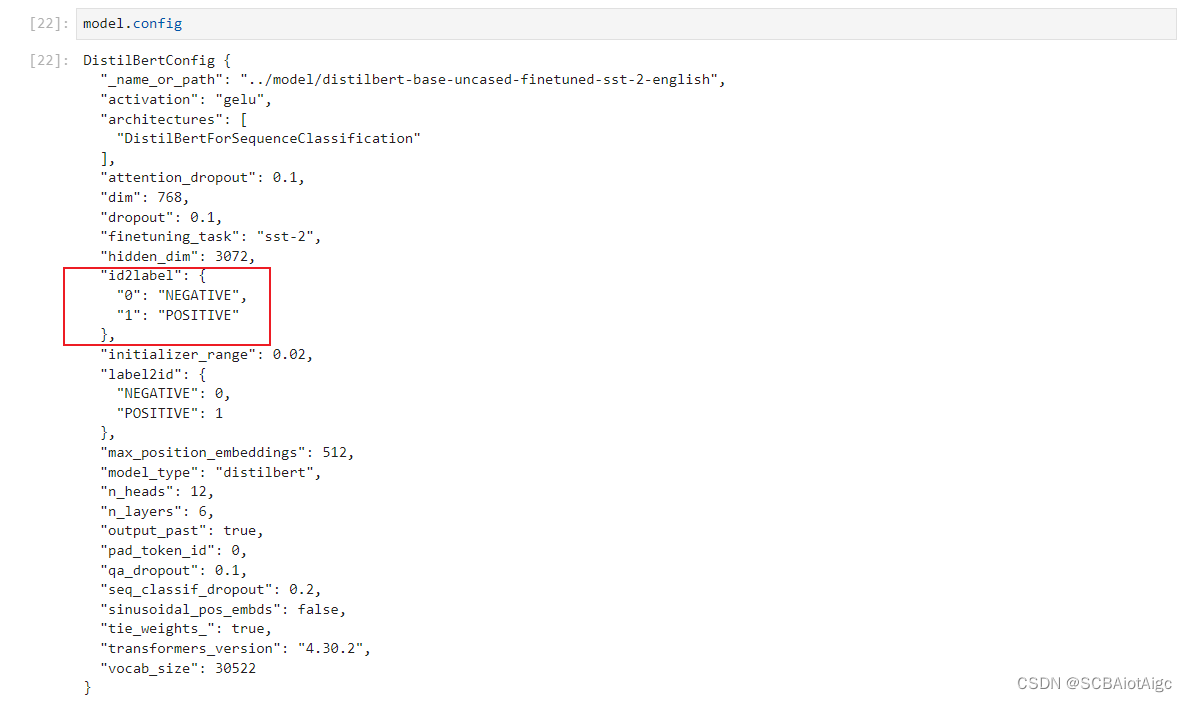
由上得出,1代表positive,0代表negative。
完整的代码:
# ---encoding:utf-8---
# @Time : 2023/8/1 10:54
# @Author : CBAiotAigc
# @Email :[email protected]
# @Site :
# @File : tokenizer_sentiment_analysis.py
# @Project : AI_Review
# @Software: PyCharm
from transformers import AutoTokenizer, AutoModel, AutoModelForSequenceClassification
import torch
import torch.nn as nn
model_name = "../model/distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
test_sentences = ["today is not that bad", "today is so bad", "so good"]
# inputs_tensor = tokenizer.encode_plus(test_sentences, padding=True, truncation=True, return_tensors="pt")
# print(inputs_tensor)
inputs_tensor = tokenizer(test_sentences, padding=True, truncation=True, return_tensors="pt")
print(inputs_tensor)
inputs_tensor = tokenizer.batch_encode_plus(test_sentences, padding=True, truncation=True, return_tensors="pt")
print(inputs_tensor)
outputs = model(**inputs_tensor)
print(outputs)
model.eval()
with torch.no_grad():
labels = torch.argmax(outputs.logits, dim=-1)
print(labels)
print(model.config.id2label)
print([model.config.id2label[id] for id in labels.tolist()])