混淆矩阵(Confusion Matrix)
混淆矩阵是根据分类模型在某个特定阈值下的预测结果得出的统计结果。
二分类任务
混淆矩阵的每个元素表示了模型在某个特定阈值下对不同类别的样本进行分类的结果数量。混淆矩阵的构成如下所示:
预测为负例 预测为正例
实际为负例 True Negative (TN) False Positive (FP)
实际为正例 False Negative (FN) True Positive (TP)
其中,TN表示真负例的数量,FP表示假正例的数量,FN表示假负例的数量,TP表示真正例的数量。
TP(True Positive)表示模型正确地将正例(Positive)预测为正例的数量,真实值是positive,模型认为是positive的数量(True Positive=TP)
FN(False Negative)表示模型将正例预测为反例(Negative)的数量,真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
FP(False Positive)表示模型将反例预测为正例的数量,真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
TN(True Negative)表示模型正确地将反例预测为反例的数量,真实值是negative,模型认为是negative的数量(True Negative=TN)
基于混淆矩阵,我们可以计算出多种评估指标来衡量模型的性能,例如准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)等。
准确率(Accuracy)

精确率(Precision)
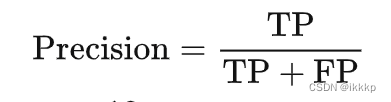
召回率(Recall)
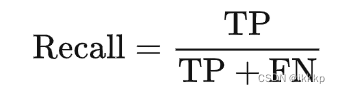
F1 Score的计算公式
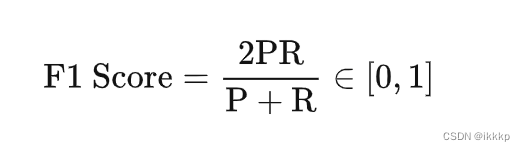
多分类任务
混淆矩阵(Confusion Matrix)是用于评估分类模型性能的一种常用工具。混淆矩阵展示了模型对多个类别样本的分类结果统计信息。
对于一个K类别的多分类任务,混淆矩阵的大小为K x K,其中每一行代表真实类别,每一列代表预测类别。矩阵的每个元素(i, j)表示模型将真实类别i的样本预测为类别j的数量。
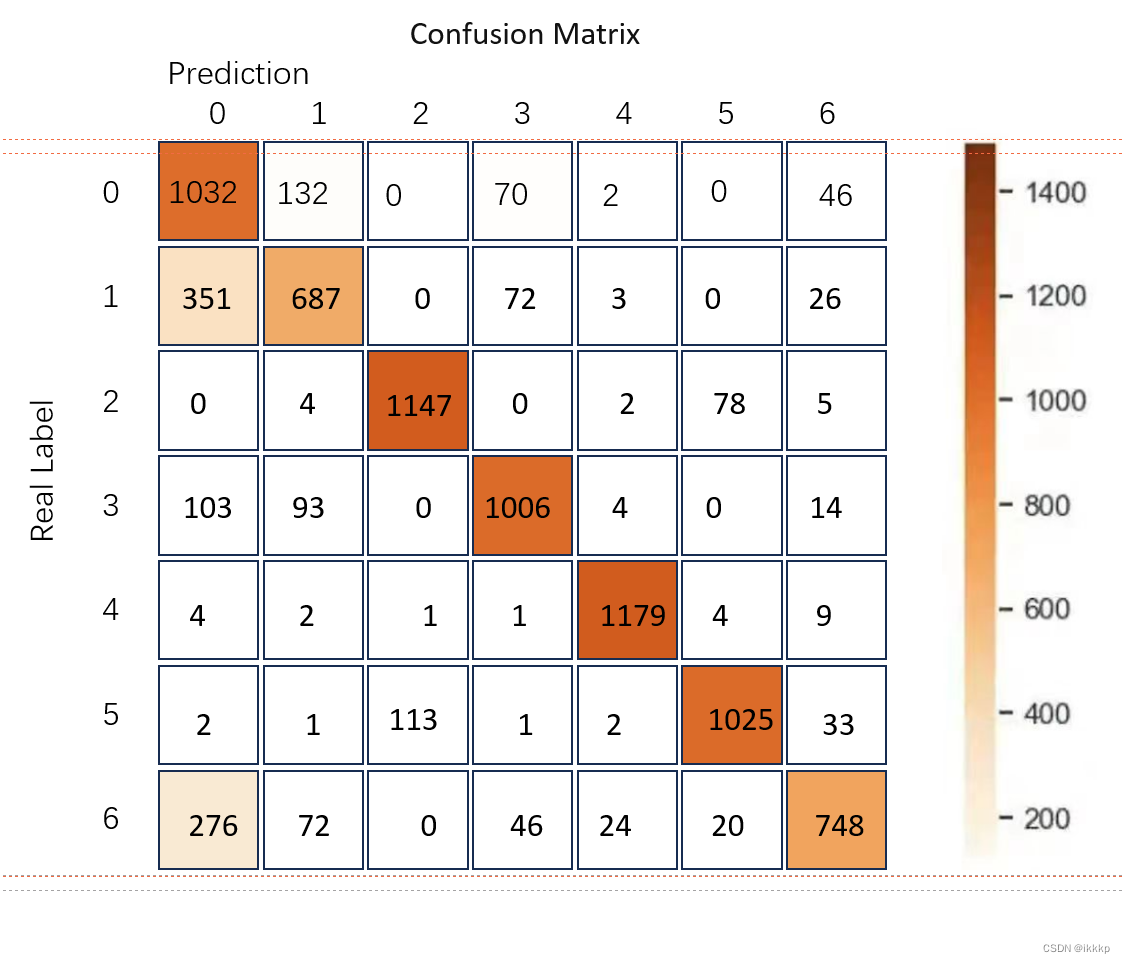
对于这个混淆矩阵,横坐标是真实标签(Ground Truth),纵坐标是模型预测的类别。对角线是我们最关注的信息,对角线代表预测正确的样本的个数。
而对于多分类准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1 Score)等值的计算常将多分类转为二分类来计算。
二分类和多分类的ROC曲线
接收者操作特征(receiveroperating characteristic),ROC曲线上每个点反映着对同一信号刺激的感受性。
二分类的ROC曲线:
在二分类任务中,ROC曲线以真正例率(True Positive Rate,TPR)为纵轴,假正例率(False Positive Rate,FPR)为横轴绘制。
ROC曲线展示了在不同阈值下,模型的性能变化。
通常情况下,二分类任务中的ROC曲线是通过在不同的阈值下计算模型的TPR和FPR得到的。根据模型的预测概率或得分,可以选择不同的阈值,计算出相应的TPR和FPR,并绘制出ROC曲线。曲线下面积(Area Under the Curve,AUC)是衡量ROC曲线性能的常用指标,AUC值越大表示模型性能越好。
多分类的ROC曲线:
多分类任务中的ROC曲线也是以TPR和FPR为坐标绘制,但在多分类情况下,通常使用微观平均(Micro-average)和宏观平均(Macro-average)两种方式计算多个类别的TPR和FPR。
-
微观平均:将所有类别的真正例和假正例数量进行累加,然后计算总体的TPR和FPR。然后可以绘制微观平均的ROC曲线。
-
宏观平均:分别计算每个类别的TPR和FPR,然后计算平均值得到宏观平均的TPR和FPR。然后可以绘制宏观平均的ROC曲线。
多分类任务中的ROC曲线可以使用类似于二分类任务中的方法来绘制,但需要根据具体的计算方法来计算多个类别的TPR和FPR,并考虑使用微观平均或宏观平均来绘制相应的ROC曲线。