torch.nn.Unfold
直观理解
torhc.nn.Unfold的功能: 从一个batch的样本中,提取出滑动的局部区域块patch(也就是卷积操作中的提取kernel filter对应的滑动窗口)把它按照顺序展开,得到的特征数就是通道数*卷积核的宽*卷积核的高, 下图中的L就是滑动完成后总的patch的个数。
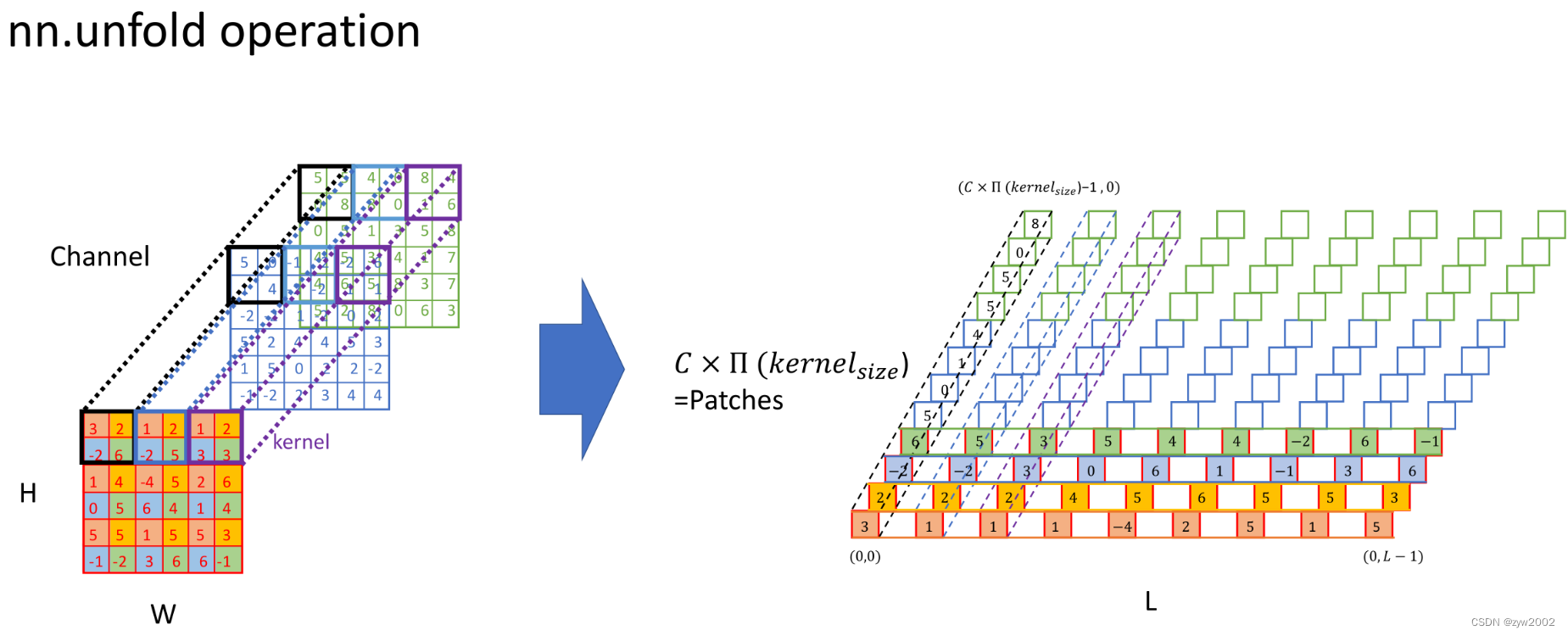
举个例子:
import torch
input1=torch.randn(1,3,4,6)
print(input1)
unfold1=torch.nn.Unfold(kernel_size=(2,3),stride=(2,3))
patches1=unfold1(input1)
print(patches1.shape)
print(patches1)
下图中的红框、蓝框、黄框、绿框分别是2x3的窗口按照步幅2x3滑动时得到的4个patch。每个patch的特征总数是2*3*3=18 ( 滑动窗口的高 ∗ 滑动窗口的宽 ∗ 通道数 滑动窗口的高*滑动窗口的宽*通道数 滑动窗口的高∗滑动窗口的宽∗通道数)
得到的输出patches1就是把每个patch的特征按照顺序展开,输出的大小就是(1,18,4)

官方文档
CLASS
torch.nn.Unfold(kernel_size, dilation=1, padding=0, stride=1)
-
功能: 从批量输入张量中提取滑动局部块。
假设一个batch的输入张量大小为 ( N , C , ∗ ) (N,C,*) (N,C,∗),其中 N N N表示batch的维度, C C C表示通道维度, ∗ * ∗ 表示任意的空间维度。该操作将输入空间维度内的每个kernel_size大小的滑动块展平到一列中, 输出的大小为 ( N , C × ∏ ( k e r n e l _ s i z e ) , L ) \left(N, C \times \prod( kernel\_size ), L\right) (N,C×∏(kernel_size),L), 其中 C × ∏ ( k e r n e l _ s i z e ) C \times \prod( kernel\_size) C×∏(kernel_size)表示每个block中包含的所有值的个数,一个block是kernel_size的面积和通道数的乘积, L L L是这样的block的个数。
L = ∏ d ⌊ spatial_size [ d ] + 2 × padding [ d ] − dilation [ d ] × ( kernel _ size [ d ] − 1 ) − 1 stride [ d ] + 1 ] , L=\prod_d\left\lfloor\frac{\text { spatial\_size }[d]+2 \times \operatorname{padding}[d]-\operatorname{dilation}[d] \times\left(\operatorname{kernel} \_ \text {size }[d]-1\right)-1}{\operatorname{stride}[d]}+1\right] \text {, } L=d∏⌊stride[d] spatial_size [d]+2×padding[d]−dilation[d]×(kernel_size [d]−1)−1+1],
其中 s p a t i a l _ s i z e spatial\_size spatial_size 是输入的空间维度(对应上述的*), d d d是所有的空间维度。
因此,最后一个维度(列维度)的索引输出给出了某个块内的所有值。
padding、stride和dilation参数指定如何检索滑动块。
Stride控制滑块的步幅; Padding控制重塑前每个维度的点的填充数两边隐式零填充的数量。
dilation 控制kenel 点之间的间距;也被称为à trous算法。
-
参数
kernel_size(int or tuple): 滑块的尺寸dilation(int or tuple,optional): 控制邻域内元素步幅的参数。默认值:1padding(int or tuple, optional): 在输入的两侧添加隐式零填充。默认值:0stride(int or tuple, optional): 滑动块在输入空间维度中的步长。默认值:1
如果kernel_size、dilation、padding或stride是int或长度为1的元组,它们的值将在所有空间维度上复制。
-
形状:
- 输入: ( N , C , ∗ ) (N,C,*) (N,C,∗)
- 输出: ( N , C × ∏ ( k e r n e l _ s i z e ) , L ) \left(N, C \times \prod( kernel\_size ), L\right) (N,C×∏(kernel_size),L)
-
例子
unfold = nn.Unfold(kernel_size=(2, 3))
input = torch.randn(2, 5, 3, 4)
output = unfold(input)
# each patch contains 30 values (2x3=6 vectors, each of 5 channels)
# 4 blocks (2x3 kernels) in total in the 3x4 input
output.size()
# Convolution is equivalent with Unfold + Matrix Multiplication + Fold (or view to output shape)
inp = torch.randn(1, 3, 10, 12)
w = torch.randn(2, 3, 4, 5)
inp_unf = torch.nn.functional.unfold(inp, (4, 5))
out_unf = inp_unf.transpose(1, 2).matmul(w.view(w.size(0), -1).t()).transpose(1, 2)
out = torch.nn.functional.fold(out_unf, (7, 8), (1, 1))
# or equivalently (and avoiding a copy),
# out = out_unf.view(1, 2, 7, 8)
(torch.nn.functional.conv2d(inp, w) - out).abs().max()
toch.nn.Fold
直观理解
toch.nn.Fold 就是torch.nn.Unfold的逆操作,将提取出的滑动局部区域块还原成batch的张量形式。
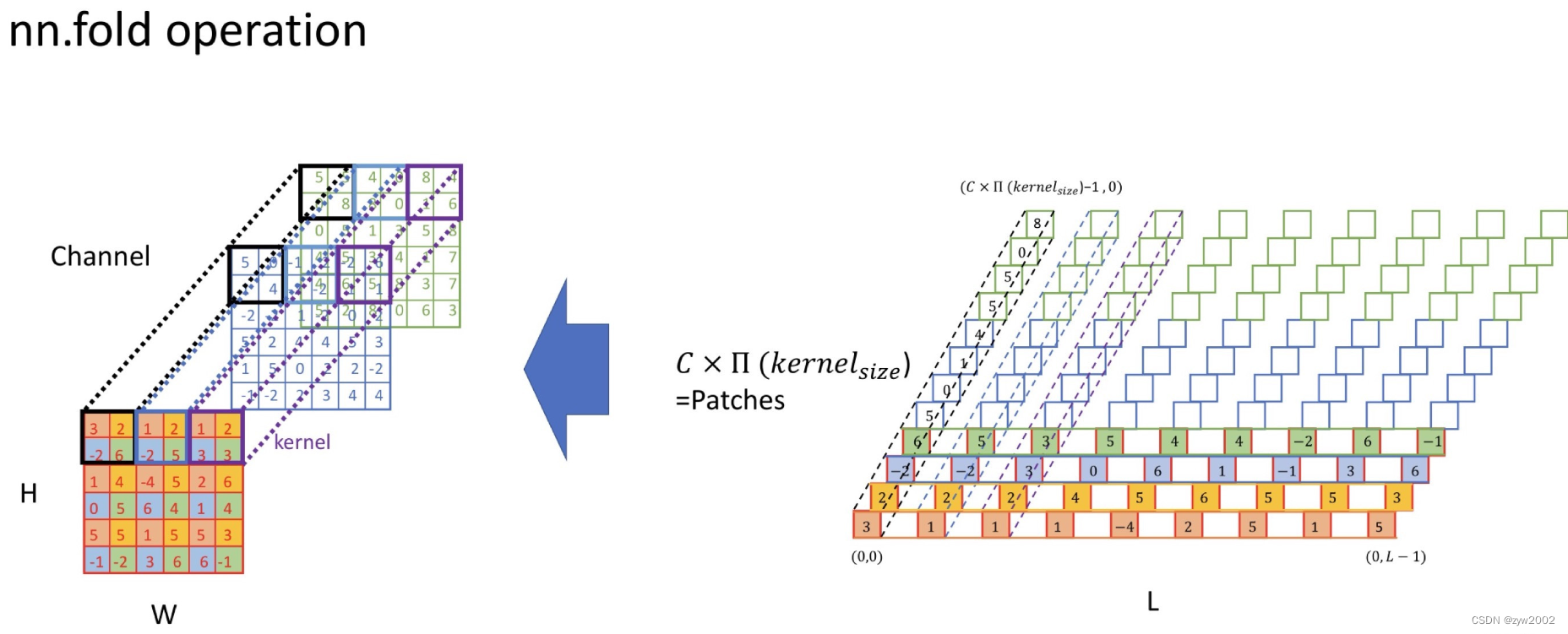
举个例子:我们把上面输出的patches 通过具有相同大小的卷积核以及步幅进行Flod操作,得到的input_restore 和 input1 相同,说明Fold和UnFold互为逆操作。
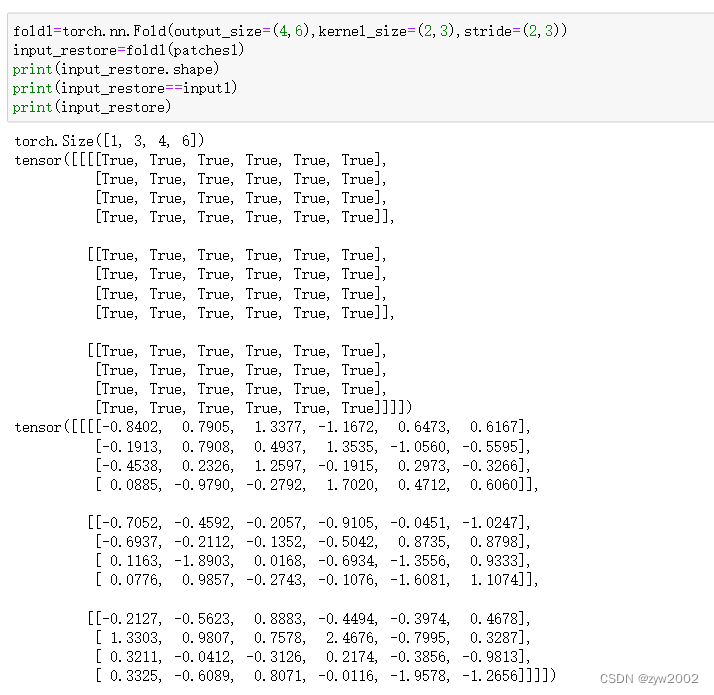
fold1=torch.nn.Fold(output_size=(4,6),kernel_size=(2,3),stride=(2,3))
input_restore=fold1(patches1)
print(input_restore.shape)
print(input_restore==input1)
print(input_restore)
官方文档
CLASS
torch.nn.Fold(output_size, kernel_size, dilation=1, padding=0, stride=1)
- 功能:
和Unfold相反,将提取出的滑动局部区域块还原成batch的张量形式。
- 参数
output_size(int or tuple): 输出的空间维度的形状kernel_size(int or tuple): 滑块的尺寸dilation(int or tuple,optional): 控制邻域内元素步幅的参数。默认值:1padding(int or tuple, optional): 在输入的两侧添加隐式零填充。默认值:0stride(int or tuple, optional): 滑动块在输入空间维度中的步长。默认值:1
- 形状
- 输入: ( N , C × ∏ ( kernel_size ) , L ) \left(N, C \times \prod(\text { kernel\_size }), L\right) (N,C×∏( kernel_size ),L) 或者 ( C × ∏ ( kernel_size ) , L ) \left( C \times \prod(\text { kernel\_size }), L\right) (C×∏( kernel_size ),L)
- 输出: ( N , C , output_size [ 0 ] , output_size [ 1 ] , … ) (N, C, \text { output\_size }[0], \text { output\_size }[1], \ldots) (N,C, output_size [0], output_size [1],…)或 ( N , C , output_size [ 0 ] , output_size [ 1 ] , … ) (N, C, \text { output\_size }[0], \text { output\_size }[1], \ldots) (N,C, output_size [0], output_size [1],…)
- 例子
>>> fold = nn.Fold(output_size=(4, 5), kernel_size=(2, 2))
>>> input = torch.randn(1, 3 * 2 * 2, 12)
>>> output = fold(input)
>>> output.size()
torch.Size([1, 3, 4, 5])