目录
一、问题来由
最近参与了CSDN的问答模块的开发,有一个任务是扩展停用词,主要用在改善问答的质量,即问题的标题尽量用来描述所遇到的问题,避免一些无意义的词汇,例如:“小白”,“大佬”,“求救”等等。这样的词汇对提问题没有任何帮助,这里暂且称之为虚词。
目前虚词表由运营整理提供,只有几十个,现在要对词表进行扩充,这里参考SOPMI情感词典的扩充方案。
二、算法思想
其核心思想主要有:
1、利用词的共现来拓展候选停用词;
2、利用点互信息(PMI)来计算词的相关性。PMI用来衡量两个两个事物之间的相关性,值越大越相关。
PMI(x, y)=log(p(xy)/p(x)p(y))
三、扩展步骤
1、训练语料
问答标签数据集,每个标签最多取10000条数据。每条数据含有标题和内容以及解答,这里只取问题标题。
{
"question_id": 1674,
"question_title": "手机社交应用的图片上传下载功能分别使用ftp和http的优缺点是什么? ",
"question_created_at": 1363039735,
"question_content": "手机上流行的社交应用,可以查看好友的拍照相册,也可以自己拍照上传和好友分享等,分别使用ftp和http技术实现上传下载的优缺点是什么? ",
"tag_id": 2,
"tag_name": "http",
"tags": [
{
"tag_id": 502,
"tag_name": "社交"
},
{
"tag_id": 503,
"tag_name": "图片"
},
{
"tag_id": 504,
"tag_name": "ftp"
},
{
"tag_id": 2,
"tag_name": "http"
}]}
2、种子停用词
这里采用运营收集的停用词invalid_stopwords.txt,作为种子停用词。
3、对语料分词
采用jieba分词器,先把种子停用词加入用户自定义词典,对语料进行分词(语料目前取了question_title),根据词性去掉标点符号。
4、统计停用词的共现词
遍历语料中每个词,取其前后各window_size长度的词,统计停用词的共现词作为候选停用词,以及共现词对的词频。
统计候选停用词的词频。
5、计算PMI
对于每一个候选停用词,计算其与所有种子停用词的PMI之和,作为候选停用词的最终PMI得分。
6、保存结果
按照候选词的PMI得分逆序排列,保存到词典文件中。
四、结果分析
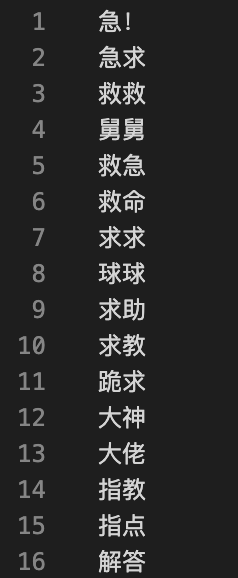
由于是根据词的共现以及词频来计算的,所以算法的确可以拓展出一些虚词,但是也会有很多非虚词,还需要对结果进行人工挑选,挑选之后的词如下:

从结果可以看出,算法因为没有语义上的支撑,扩展的词还需要人工进行校对,可以辅助用于无效标题的判断。或许结合word2vec来进行扩展效果要好一些。