一、xpath
xpath的使用:
先安装xpath插件
在浏览器的扩展里进行安装
安装后,先关闭浏览器,再打开,按住ctrl+shift+x
 会显示出这个框框(说明xpath安装成功)
会显示出这个框框(说明xpath安装成功)
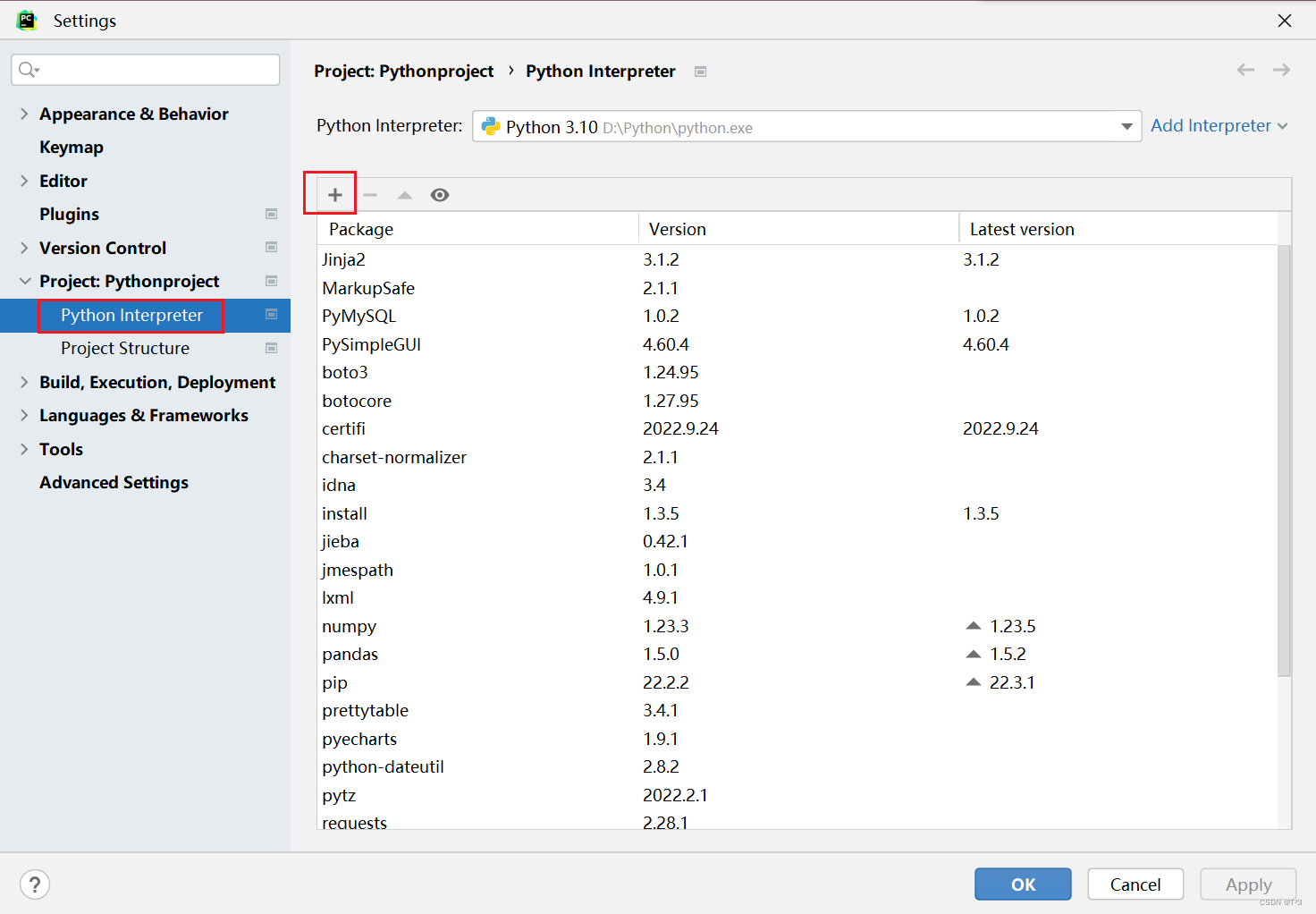
- 安装lxml库
pip install lxml
镜像安装;pip install -i http://pypi.douban.com/simple/ --trusted-host=pypi.douban.com/simple lxml
- 导入lxml.etree
from lxml import etree
- etree.parse() — 解析本地文件
html_tree = etree.parse(‘xx.html’)
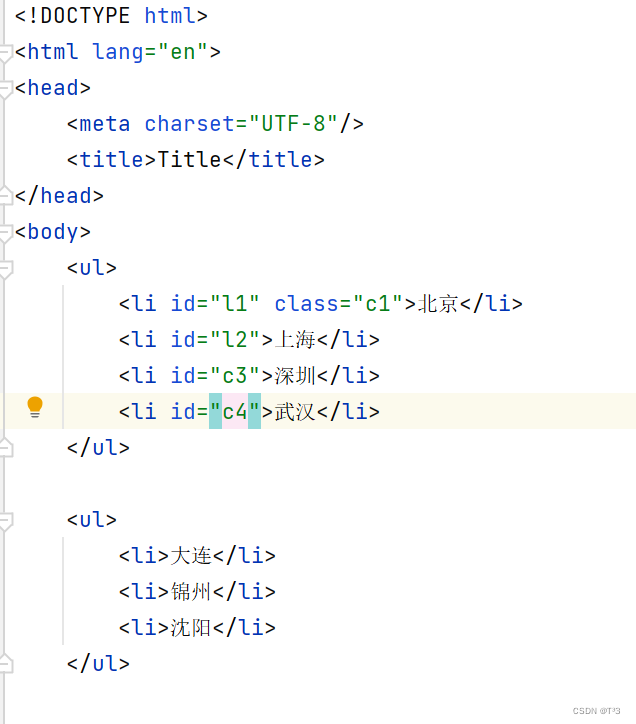
先创建一个html文件
随便写入一点数据
在html 文件中加入一个斜杠(/),表示没有结束标签

xpath解析本地文件
打印tree
打印结果:

xpath基本语法
(1) 路径查询
//:查找所有子孙节点,不考虑层级关系
/:之间找子节点
(2) 谓词查询
//div[@id]
//div[@id=“maincontent”]
(3)属性查询
@class
(4)模糊查询
div[contains(@id,“he”)]
div[starts-with(@id,“he”)]
(5)内容查询
//div/h1/text()
具体使用代码块:
from lxml import etree
tree = etree.parse('解析_xpath的基本使用.html')
# tree.xpath('xpath路径')
# 查找ul下面的li
# li_list = tree.xpath('//body/ul/li')
# 查找所有有id属性的li标签
# text()获取标签中的内容
# li_list = tree.xpath('//ul/li[@id]/text()')
# 查找id为1的li标签
# li_list = tree.xpath('//ul/li[@id="l1"]/text()')
# 查找到id为l1的li标签的class的属性值
# li = tree.xpath('//ul/li[@id="l1"]/@class')
# 查询id中包含l的li标签(模糊查询)
# li_list = tree.xpath('//ul/li[contains(@id,"l")]/text()')
# 查询id的值以l开头的li标签
# li_list = tree.xpath('//ul/li[starts-with(@id,"c")]/text()')
解析_xpath的基本使用.html
- 服务器响应文件 — etree.HTML()
html_tree = etree.HTML(response.read().decode(‘utf-8’))
二、获取百度网站的“百度一下”
- 获取网页的源码
- 解析
- 打印
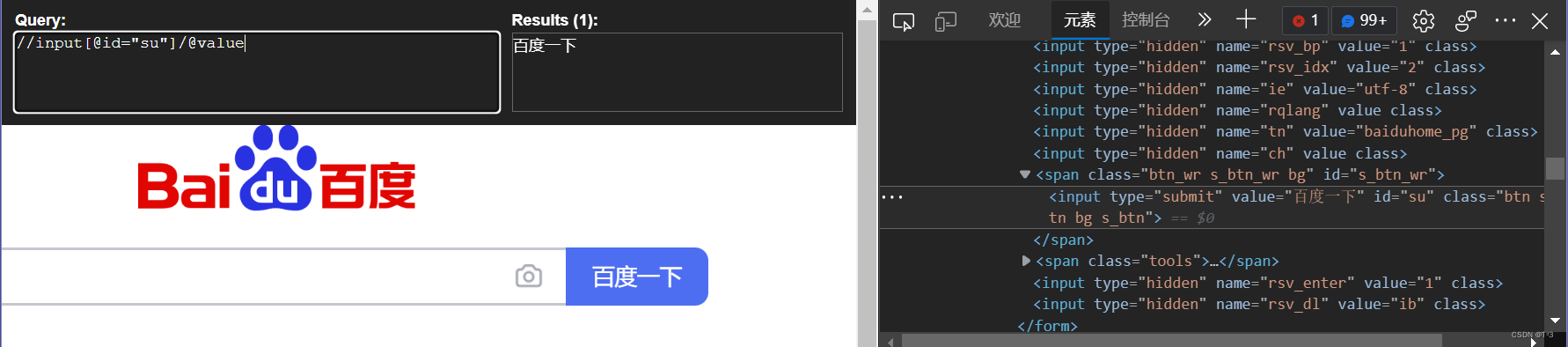
获取xpath:
import urllib.request
url = 'https://www.baidu.com/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'
}
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
# 模拟浏览器访问服务器
response = urllib.request.urlopen(request)
# 获取网页源码
content = response.read().decode('utf-8')
# 解析网页源码 来获取我们想要的数据
from lxml import etree
# 解析服务器响应的文件
tree = etree.HTML(content)
# 获取想要的数据
result = tree.xpath('//input[@id="su"]/@value')[0]
print(result)
三、站长素材
需求:下载前十页图片
先找到第一页
 在检查中的预览结合响应,查看是否是第一页
在检查中的预览结合响应,查看是否是第一页
如果是就复制url:https://sc.chinaz.com/tupian/qinglvtupian.html
同样的方法找到第二页的url:https://sc.chinaz.com/tupian/qinglvtupian_2.html
可以发现第一页的页码和其他页的页码不一样
具体实现完整代码:
最后将图片都存入到loveImg文件夹中
import urllib.request
from lxml import etree
def create_request(page):
if(page == 1):
url = 'https://sc.chinaz.com/tupian/qinglvtupian.html'
else:
url = 'https://sc.chinaz.com/tupian/qinglvtupian_' + str(page) + '.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:106.0) Gecko/20100101 Firefox/106.0'
}
request = urllib.request.Request(url=url, headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
def down_load(content):
tree = etree.HTML(content)
name_list = tree.xpath('//div[@class="container"]//img/@alt')
data_list = tree.xpath('//div[@class="container"]//img/@data-original')
for i in range(len(name_list)):
name = name_list[i]
src = data_list[i]
url = 'https:' + src
urllib.request.urlretrieve(url=url, filename='./loveImg/' + name + '.jpg')
if __name__ == '__main__':
start_page = int(input('请输入起始页码:'))
end_page = int(input('请输入结束页码:'))
for page in range(start_page, end_page+1):
# 请求对象的定制
request = create_request(page)
# 获取网页的源码
content = get_content(request)
# 下载
down_load(content)
四、Jsonpath
适用于解析json数据
打开淘票票官网:
我们做一个小案例进行演示
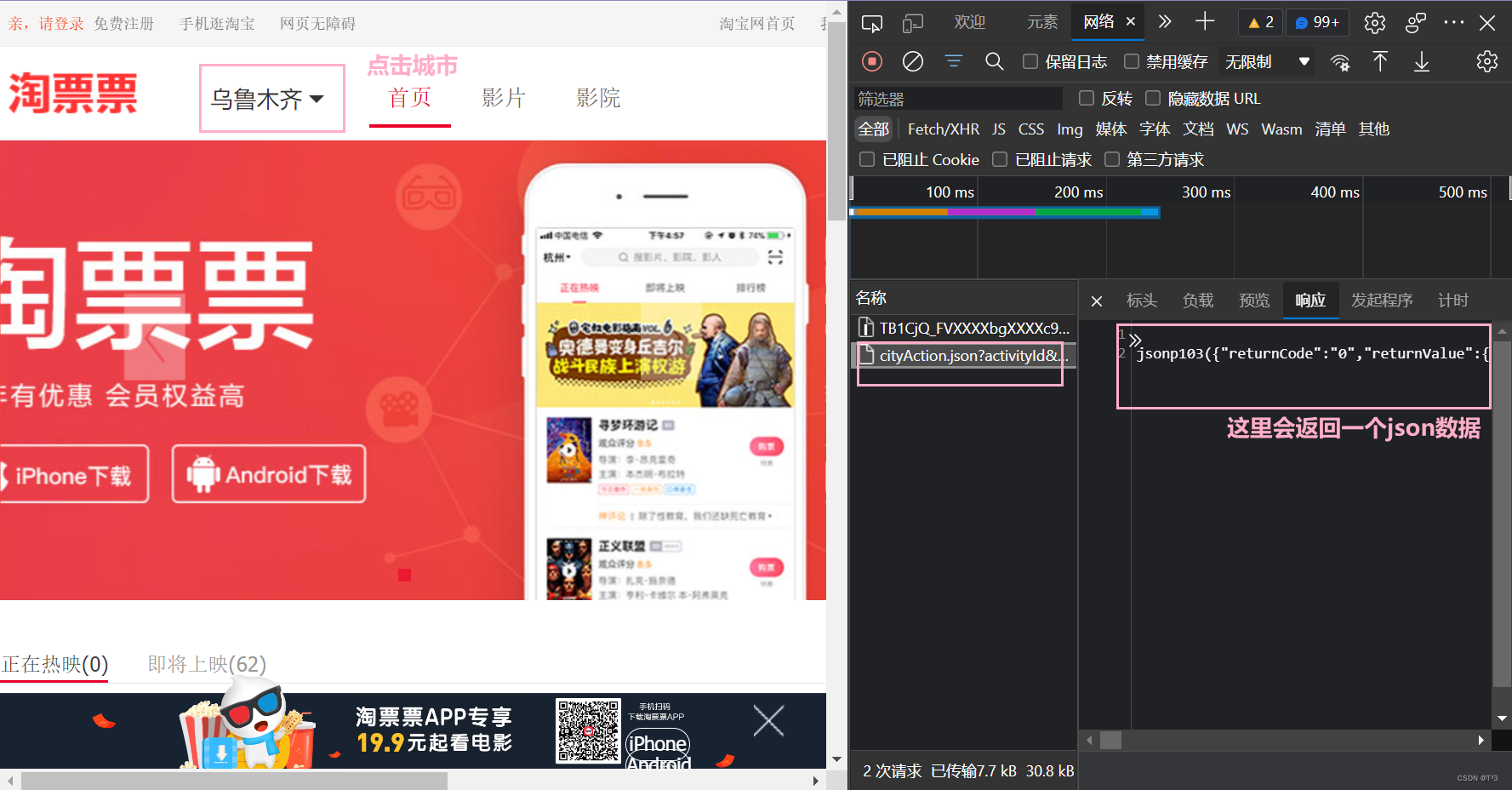
需要注意的是:jsonpath只能解析本地文件,不能解析服务器响应的文件,和xpath不一样
在开始之前要先下载jsonpath模块
import urllib.request
url = 'https://dianying.taobao.com/cityAction.json?activityId&_ksTS=1669306447473_102&jsoncallback=jsonp103&action=cityAction&n_s=new&event_submit_doGetAllRegion=true'
headers = {
# 填入请求标头
# 其中 # ':authority': 'dianying.taobao.com',
# ':method': 'GET',
# ':path': '/cityAction.json?activityId&_ksTS=1669306447473_102&jsoncallback=jsonp103&action=cityAction&n_s=new&event_submit_doGetAllRegion=true',
# ':scheme': 'https',
# 'accept-encoding': 'gzip, deflate, br',
# 需要注释
}
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
content = content.split('(')[1].split(')')[0]
with open('解析_jsonpath解析淘票票.json', 'w', encoding='utf-8')as fp:
fp.write(content)
import json
import jsonpath
obj = json.load(open('解析_jsonpath解析淘票票.json', 'r', encoding='utf-8'))
city_list = jsonpath.jsonpath(obj, '$..regionName')
print(city_list)
五、bs4的基本使用
BeautifulSoup简称bs4,和lxml一样,是一个html的解析器,主要功能也是解析和提取数据
先安装bs4模块

bs4爬取星巴克数据
打开星巴克官网,选择菜单
需求:爬取菜单中的数据:文字
找到菜单界面的接口
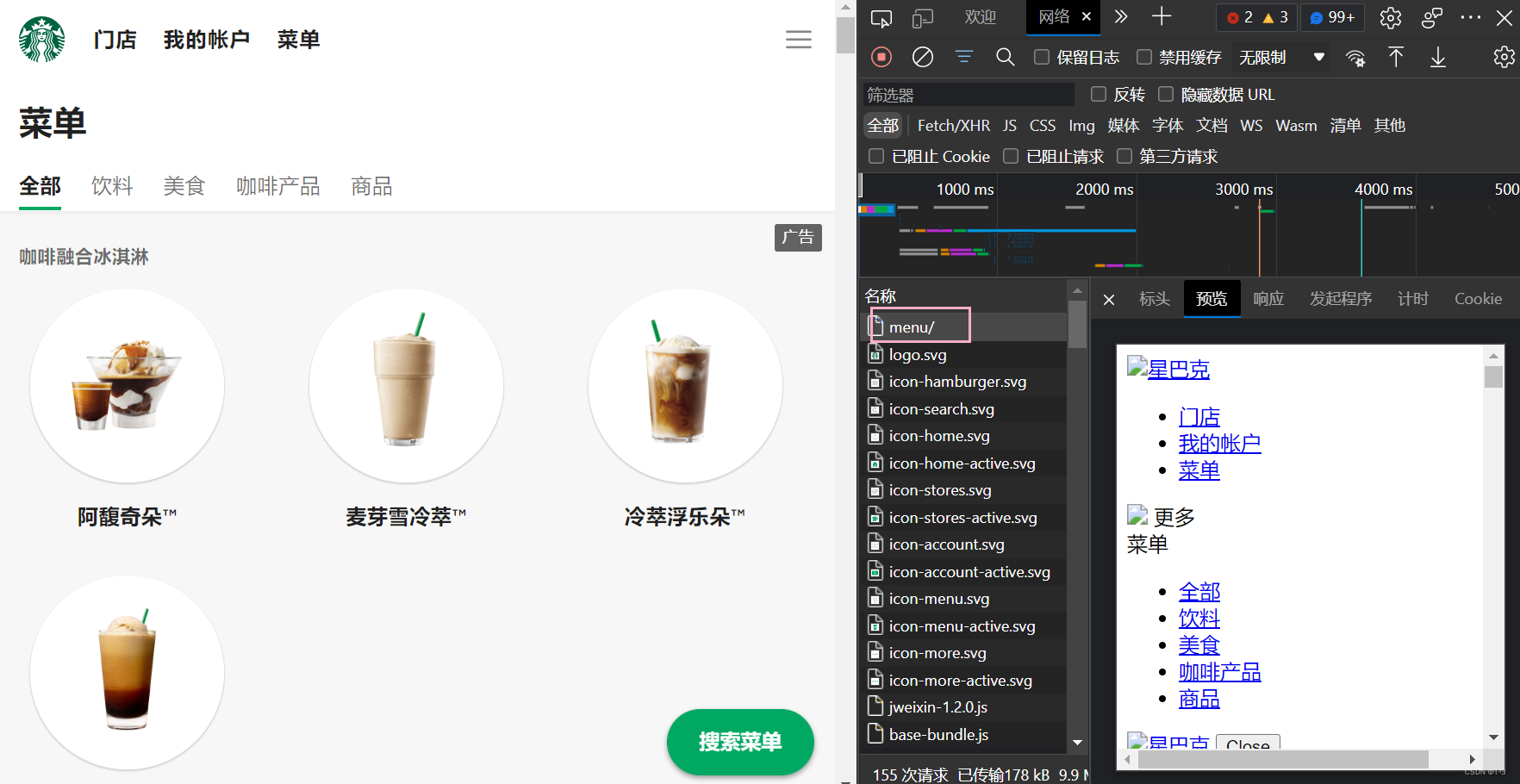
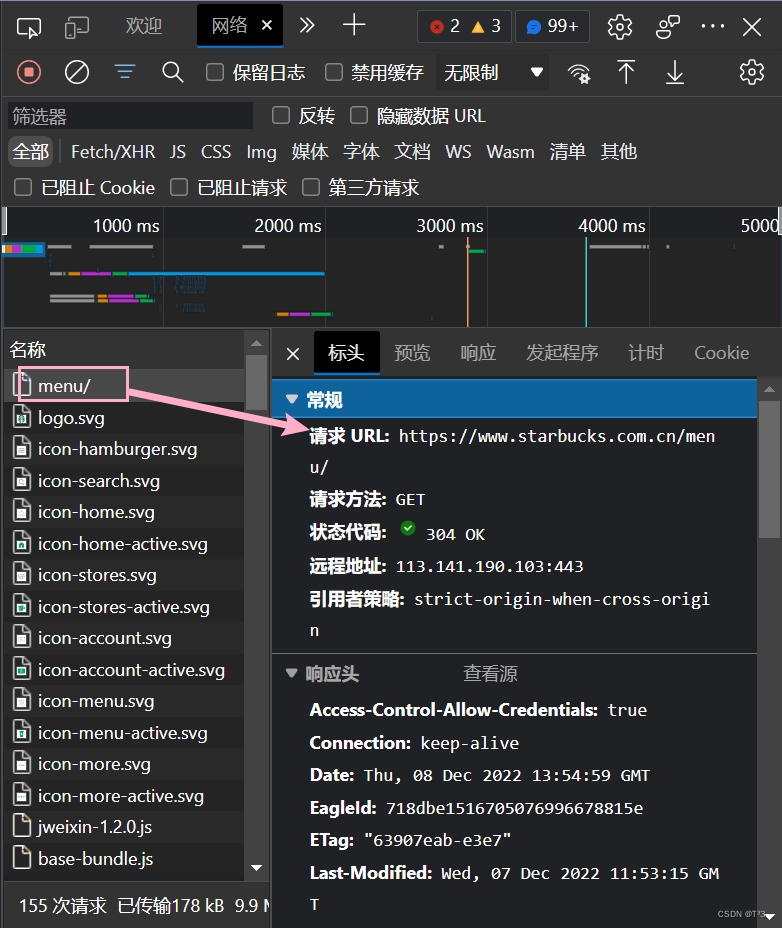
这里使用xpath转bs4的方法
import urllib.request
url = 'https://www.starbucks.com.cn/menu/'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'lxml')
name_list = soup.select('ul[class="grid padded-3 product"] strong')
for name in name_list:
print(name.string)
运行结果部分截图
