前言:
1.1
数据库
存储和管理数据的仓库,数据是有组织的进行存储。
数据库英文名是
DataBase
,简称
DB
。
数据库就是将数据存储在硬盘上,可以达到持久化存储的效果。那又是如何解决上述问题的?使用数据库管理系统。
1.2
数据库管理系统
管理数据库的大型软件
英文:
DataBase Management System
,简称
DBMS
在电脑上安装了数据库管理系统后,就可以通过数据库管理系统创建数据库来存储数据,也可以通过该系统对数据库中的数 据进行数据的增删改查相关的操作。
注意:我们平时说的MySQL
数据库其实是
MySQL
数据库管理系统。
一、MySQL数据模型
关系型数据库是建立在关系模型基础上的数据库,简单说,关系型数据库是由多张能互相连接的二维表组成的数据库。
数据模型:
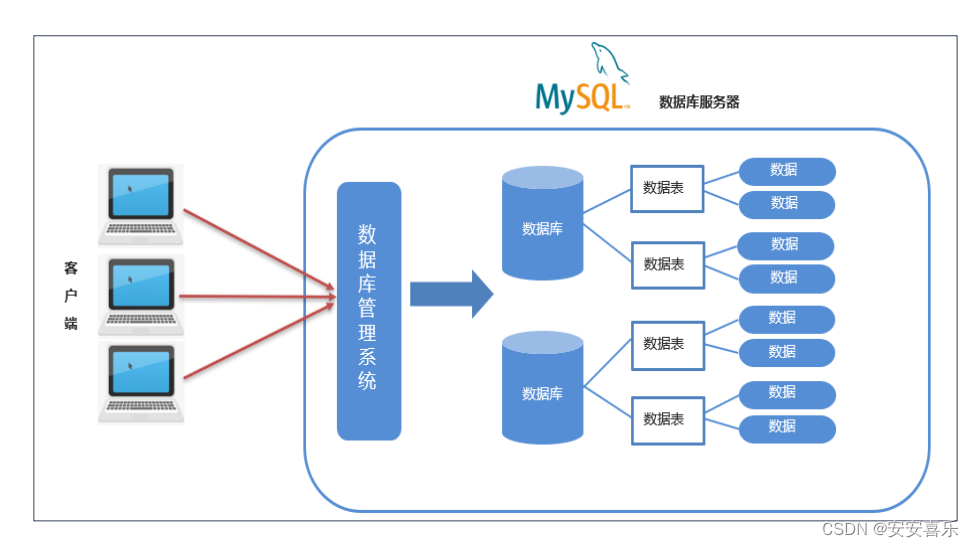
如上图,我们通过客户端可以通过数据库管理系统创建数据库,在数据库中创建表,在表中添加数据。创建的每一个数据库对应到磁盘上都是一个文件夹。
比如可以通过SQL
语句创建一个数据库(数据库名称为
db1),语句如下。
create database db1;
我们可以在数据库安装目录下的
data
目录下看到多了一个
db1
的文件夹。所以,
在MySQL中一个数据库对应到磁盘上的一 个文件夹
。 而一个数据库下可以创建多张表,我们到MySQL
中自带的
mysql
数据库的文件夹目录下:

而上图中右边的
db.frm 是表文件,db.MYD 是数据文件
,通过这两个文件就可以查询到数据展示成二维表的效果。
总结:
- MySQL中可以创建多个数据库,每个数据库对应到磁盘上的一个文件夹
- 在每个数据库中可以创建多个表,每张都对应到磁盘上一个 frm 文件
- 每张表可以存储多条数据,数据会被存储到磁盘中 MYD 文件中
二、SQL概述
1.SQL简介
- 英文:Structured Query Language,简称 SQL
- 结构化查询语言,一门操作关系型数据库的编程语言
- 定义操作所有关系型数据库的统一标准
2.通用语法
- SQL 语句可以单行或多行书写,以分号结尾。
- MySQL 数据库的 SQL 语句不区分大小写,关键字建议使用大写。
- 单行注释: -- 注释内容 或 #注释内容(MySQL 特有)。
3.SQL分类
- DDL(Data Definition Language)数据定义语言,用来定义数据库对象:数据库,表,列等,
- DML(Data Manipulation Language) 数据操作语言,用来对数据库中表的数据进行增删改,
- DQL(Data Query Language) 数据查询语言,用来查询数据库中表的记录(数据),
- DCL(Data Control Language) 数据控制语言,用来定义数据库的访问权限和安全级别,及创建用户。

4.DDL--操作数据库
(1)查询 代码:show databases;
show databases;
下述查询到的是这些数据库是mysql安装好自带的数据库

(2)创建数据库 代码:create database 数据库名称;
CREATE DATABASE 数据库名称; 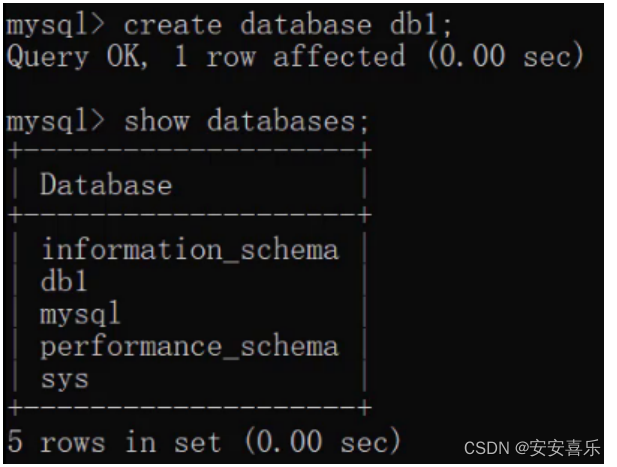
而在创建数据库的时候,我并不知道db1数据库有没有创建,直接再次创建名为db1的数据库就会出现错误:
![]()
为了避免上面的错误,在创建数据库的时候先做判断,如果不存在再创建。
CREATE DATABASE IF NOT EXISTS 数据库名称; 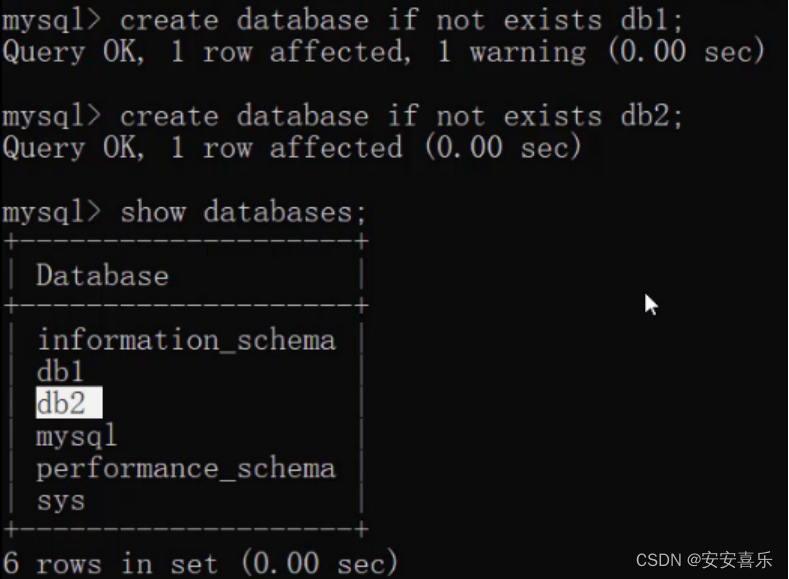
从上面的效果可以看到虽然db1数据库已经存在,再创建db1也没有报错,而创建db2数据库则创建成功。
(3)删除数据库
- 删除数据库: drop database 数据库;
- 删除数据库(判断是否存在,存在则删除):drop database if exists 数据库;
DROP DATABASE 数据库名称;
DROP DATABASE IF EXISTS 数据库名称; 
(4) 使用数据库
- 使用数据库:use 数据库名称;
- 查看当前使用的数据库: select database();
USE 数据库名称;
SELECT DATABASE(); 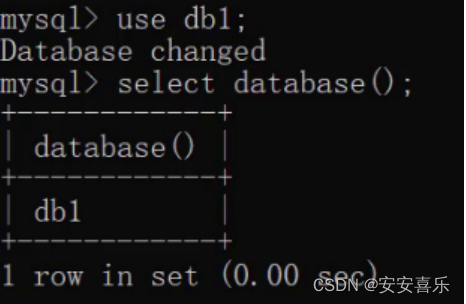
5.DDL-操作表
(1)查询表
- 查询当前数据库下所有表名称: show tables;
- 查询表的结构 :desc 表名称;
show tables;
desc 表名称;

(2)创建表
CREATE TABLE 表名 ( 字段名1 数据类型1,
字段名2 数据类型2, …
字段名n 数据类型n );注意:最后一行不能加逗号。

(3)数据类型
MySQL支持多种类型,可以分为3类:
数值
- tinyint : 小整数型,占一个字节
- int :大整数类型,占四个字节 (例如:age int)
- double:浮点类型 使用格式: 字段名 double(总长度,小数点后保留的位数)
日期
- date : 日期值。只包含年月日 birthday date :
- datetime : 混合日期和时间值。包含年月日时分秒
字符串
- char : 定长字符串。 优点:存储性能高;缺点:浪费空间。例子:name char(10) 如果存储的数据字符个数不足10个,也会占10个的空间
- varchar : 变长字符串。优点:节约空间;缺点:存储性能低。例如:name varchar(10) 如果存储的数据字符个数不足10个,那就数据字符个数是几就占几个的空间
需求:设计一张学生表,请注重数据类型、长度的合理性1. 编号2. 姓名,姓名最长不超过 10 个汉字3. 性别,因为取值只有两种可能,因此最多一个汉字4. 生日,取值为年月日5. 入学成绩,小数点后保留两位6. 邮件地址,最大长度不超过 647. 家庭联系电话,不一定是手机号码,可能会出现 - 等字符8. 学生状态(用数字表示,正常、休学、毕业 ... )
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);(4)删除表
- 删除表:drop table 表名;
- 删除表判断是否存在:drop table if exists 表名;(
drop table 表名;
drop table if exists 表名;(5)修改表
- 修改表名: alter table 表名 rename to 新的表名;
- 添加一列:alter table 表名 add 列名 数据类型;
- 修改数据类型:alter table 表名 modify 列名 新数据类型;
- 修改列名和数据类型:alter table 表名 change 列名 新列名 新数据类型;
- 删除列:alter table 表名 drop 列名
1.修改表名
alter table 表名 rename to 新的表名;
2.添加一列
alter table 表名 add 列名 数据类型;
3.修改数据类型
alter table 表名 modify 列名 新数据类型;
4.修改列名和数据类型
alter table 表名 change 列名 新列名 新数据类型;
5.删除列
alter table 表名 drop 列名;6.DML:对数据进行增(insert)删(delete)改(update)操作
(1)添加数据
1.给指定列添加数据
insert into 表名(列名1,列名2,...)values(值1,值2,...);
2.给全部列添加数据
insert into 表名 values(值1,值2,...);
3.批量添加数据
insert into 表名(列名1,列名2,...) values(值1,值2,...),(值1,值2,...),(值1,值2,...)....;
insert into 表名 values(值1,值2,...),(值1,值2,...),(值1,值2,...)...;#给指定列添加数据
insert into student(id,name) values(1,"张三");
#给全部列添加数据
insert into student(id,name,gender,birthday,score,email,tel,status) values(2,"李四","男","1999-11-11",88.88,"[email protected]","12388888",1);
#上面的简化形式,列名的列表是可以省略的,但是不建议这样使用
insert into student values(2,"李四","男","1999-11-11",88.88,"[email protected]","12388888",1);
(2)修改数据
注意:update语句如果没有加上where条件,则会将表中所有数据全部修改!!!
1.修改表数据
update 表名 set 列名1=值1,列名2=值2,...[where 条件];
2.练习
将张三的性别改为女:
update stu set sex = '女' where name = '张三';
将张三的生日改为 1999-12-12 分数改为99.99
update stu set birthday = '1999-12-12', score = 99.99 where name = '张三';
注意:如果update语句没有加where条件,则会将表中所有数据全部修改!
(3)删除数据
1.删除数据
delete from 表名 [where 条件];
2.练习
---删除张三的记录
delete from stu where name ="张三";
---删除student表中所有的记录
delete from stu;7.DQL-查询操作
查询的完整语法
1.select 字段列表-------(基础查询)
2.from 表名列表
3.where 条件列表-------(条件查询)
4.group by分组字段-----(分组查询)
5.having 分组后条件
6.order by 排序字段----(排序查询)
7.limit 分页限定-------(分页查询)(1)基础查询
1.查询多个字段
select 字段列表 from 表名
select *from 表名--查询所有记录
2.去除重复记录
select distinct 字段列表 from 表名;
3.起别名
as: --as也可以省略
练习
1.查询name,age两列
select name,age from student;
查询所有列的数据,列名的列表可以用*代替
select *from student;
2.去除重复记录
select distinct address from student;
3.查询数学成绩、英语成绩,并通过as给math、english起别名(as关键字可以省略)
select name,math as 数学成绩,english as 英文成绩 from stu;
select name,math 数学成绩,english 英文成绩 from stu; (2)条件查询
select 字段列表 from 表名 where 条件列表;
条件列表可以使用下列的运算符:

注意:null值的比较不能使用= 或者 !=,需要使用is或者is not;
练习
1.查询年龄大于20岁的学员信息
select *from student where age>20;
2.查询年龄大于等于20岁的学员信息
select *from student where age>=20;
3.查询年龄大于等于20岁 并且年龄小于等于30岁的学员信息
select *from student where age>=20 && age <=30;
select *from student where age>=20 and age<=30;
select * from stu where age BETWEEN 20 and 30;
4.查询年龄等于18岁的学员信息
select *from student age = 18;
5.查询年龄不等于18岁的学员信息
select * from stu where age != 18;
select * from stu where age <> 18;
6.查询年龄等于18岁或者年龄等于20岁或者年龄等于22岁的学员信息
select * from stu where age = 18 or age = 20 or age = 22;
select * from stu where age in (18,20 ,22);
7.查询英语成绩为 null的学员信息
null值的比较不能使用 = 或者 != 。需要使用 is 或者 is not
select * from stu where english = null; -- 这个语句是不行的
select * from stu where english is null;
select * from stu where english is not null;模糊查询 使用 like 关键字,可以使用通配符进行占位 :_ : 代表单个任意字符% : 代表 任意个数字符
练习
1.查询姓'马'的学员信息
select *from student where name like '马%'
2.查询第二个字是'花'的学员信息
select *from student where name like '_花%'
3.查询名字中包含 '德' 的学员信息
select *from student where name like '%德%'(3)排序查询
select 字段列表 from 表名 order by 排序字段名1[排序方式1],排序字段名2[排序方式2]...;
上述语句的排序方式有两种
- ASC:升序排序(默认值)
- DESC:降序排序
注意:如果是多个排序条件,当前边的条件值一致时,才会根据第二条件进行排序;
练习
1.查询学生信息,按照年龄升序进行排序
select *from student order by age;
2.查询学生信息,按照数学成绩降序排列
select *from student order by math desc;
3.查询学生信息,按照数学成绩降序排列,当数学成绩一致时,再按照英语成绩升序排列
select *from student order by math desc,english asc;
(4)聚合函数
将一列数据作为一个整体,进行纵向计算。
聚合函数语法:
注意:null值不参与所有聚合函数的运算
select 聚合函数(列名)from 表名;
聚合函数分类:

练习
1.统计班级一共有多少个学生
select count(id) from student;
select count(englis) from student;
上面语句根据某个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。
所以可以在count(*) 来实现。* 表示所有字段数据,一行中也不可能所有的数据都为null,
所以建议使用 count(*),例如下面这样:
select count(*) from student;
3.查询数学成绩的最高分
select max(math) from student;
4.查询数学成绩的最低分s
select min(math) from student;
5.查询数学成绩的总分
select sum(math) from student;
6.查询数学成绩的平均分
select avg(math) from student;(5)分组查询
select 字段列表 from 表名 [where 分组条件限定] group by 分组字段名 [having 分组后条件过滤]注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
1.查询男同学和女同学各自的数学平均分
select sex, avg(math) from stu group by sex;
注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
select name,sex, avg(math) from stu group by sex;---这里查询name字段就没有意义;
2.查询男同学和女同学各自的数学平均分,以及各自人数
select sex, avg(math),count(*) from stu group by sex;
3.查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组
select sex, avg(math),count(*) from stu where math > 70 group by sex;
4.查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2个的
select sex, avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having 区别:where和having的区别:
- 执行时机不一样:where 是分组之前进行限定,不满足where条件,则不参与分组,而having是分组之后对结果进行过滤。
- 可判断的条件不一样:where 不能对聚合函数进行判断,having 可以。
(6)分页查询
select 字段列表 from 表名 limt 起始索引,查询条目注意: 上述语句中的起始索引是从0开始
1.从0开始查询,查询3条数据
select *from stu limit 0,3;
2.每页显示3条数据,查询第1页数据
select * from stu limit 0 , 3; 1
3.每页显示3条数据,查询第2页数据
select * from stu limit 3 , 3; 1
4.每页显示3条数据,查询第3页数据
select * from stu limit 6 , 3;
从上面的练习推导出起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数