( I , M ) (I,M) (I,M)是构造的pair data,其中 I I I是image, M M M是其他任意模态,经过不同的encoder–f/g, q i = f ( I i ) q_i=f(I_i) qi=f(Ii), k i = g ( M i ) k_i=g(M_i) ki=g(Mi),使用对比学习InfoNCE loss进行优化;实践中,使用对称loss, L I , M + L M , I L_{I,M}+L_{M,I} LI,M+LM,I;
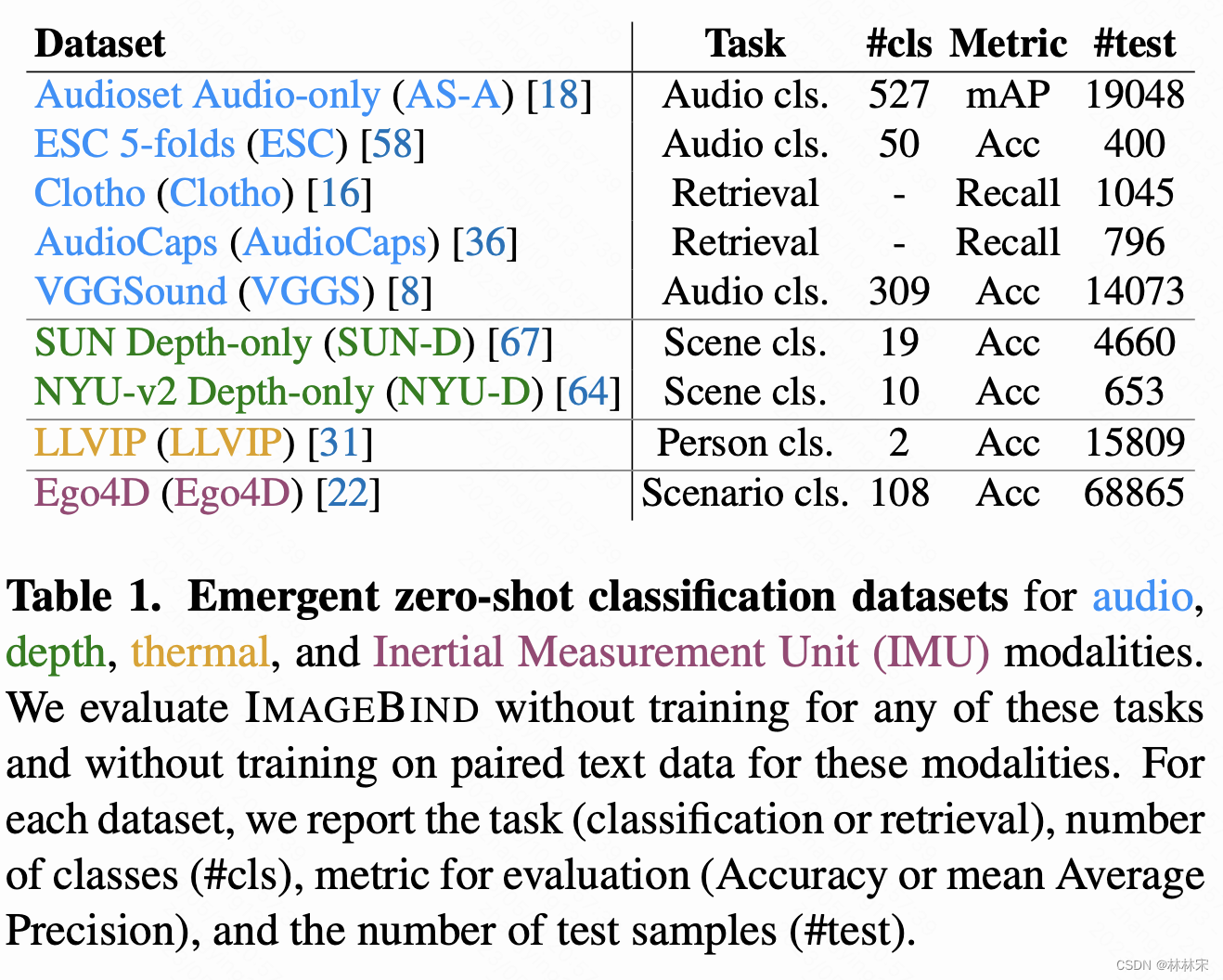
训练中发现,在进行 ( I , M 1 ) (I, M_1) (I,M1)和 ( I , M 2 ) (I, M_2) (I,M2)的对齐学习时, ( M 1 , M 2 ) (M_1,M_2) (M1,M2)之间也存在对齐,说明ImageBind可以做zero-shot 的跨模态检索任务。实验结果表明,不需要audio-text数据,使用text prompt,可以达到SOTA的text-audio classification results。