- 2022.1.28
- Songxiang Liu, Dan Su,Dong Yu
- CUHK & Tencent AI Lab
- keonlee9420:DiffGAN-TTS
abstract
- 使用降噪diffusion模型完成TTS任务,引入GAN训练进一步增强生成质量。
- 只需要4步就可以生成高质量语音,方法分为两个阶段 :(1)训练一个TTS声学模型提供先验知识,(2)训练DDPM。也可以进通过一步denoising生成语音。
- 论文写的还是挺清楚的,包括公式推导,可以看一下细节
intro
diffusion模型的前向(diffusion process)可以看作是一个T步无参数的加噪过程,反向(denoising process)可以看作一个T步有参数的去噪过程。diffusion的假设是待去噪的分布可以用用高斯分布表示,如果想要从高斯分布中采样得到真实的分布,通常需要<小的denoising step size,大的diffusion steps>,多次少量添加噪声。这样会使得diffusion在实时任务场景不可用。
如果想要大的denoising step size,采用conditional GAN 作为非高斯多峰函数来模拟去噪分布,不仅能够提升降噪效率,还可以增加生成样本多样性和高保真度。
DiffGAN-TTS
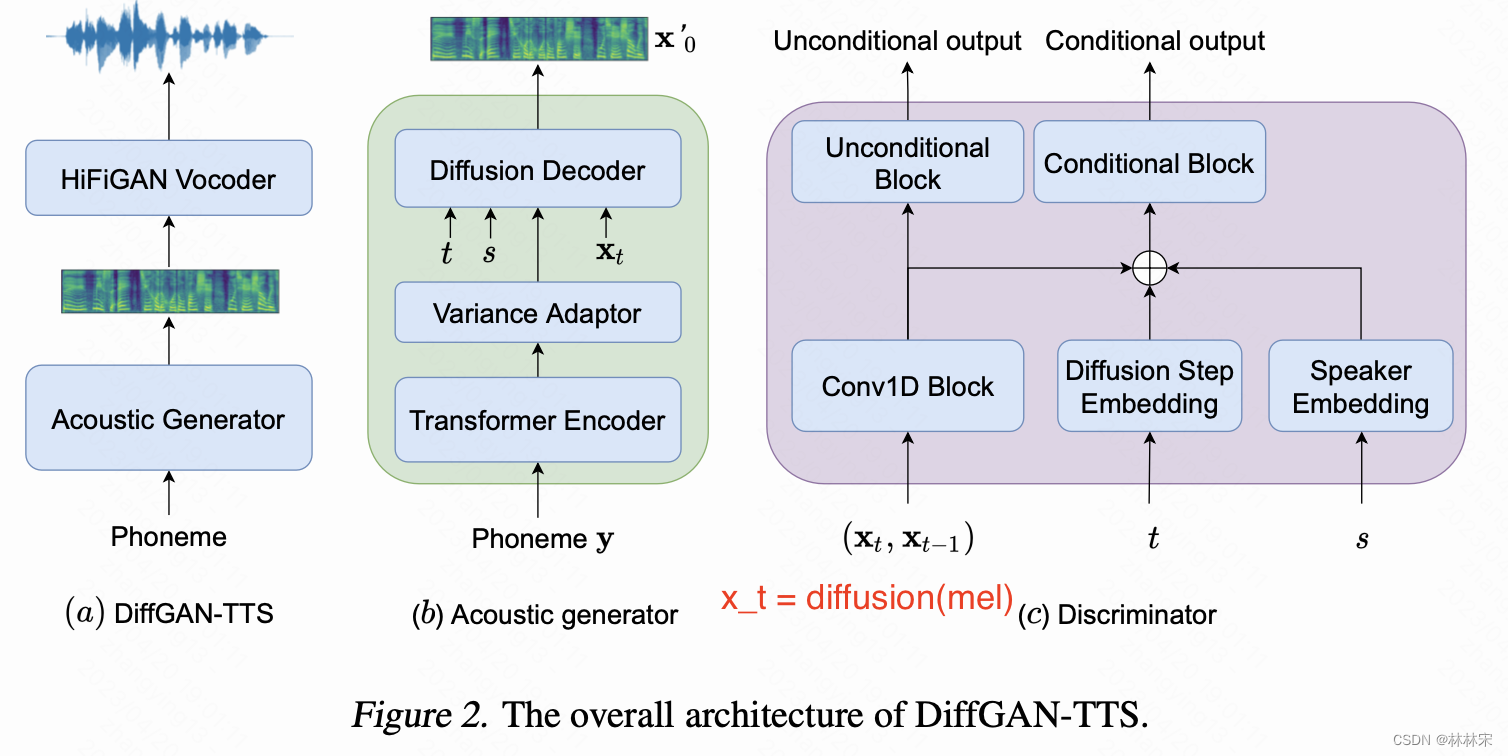
- 前向训练伪代码
def forward():
x_t = diffusion(mel, t)
# x_(t-1)=x_t_prev
x_t_prev = diffusion(mel, t-1)
x_0_pred = denoise_fn(x_t, t, cond, speaker)[:, 0]
x_start = norm_spec(coarse_mel)
x_t_prev_pred = q_posterior_sample(x_start, x_t, t)[:,0]
return x_0_pred, x_t, x_t_prev, x_t_prev_pred, t
Training loss
- generator loss = fm_loss + adv_loss + reconst_loss
- fm_loss: 判别器输入真实&预测特征的中间层一范数
- adv_loss: 判别器将预测特征误判为真实特征的范数
- reconst_loss:x_0_pred和mel的范数
- discriminator loss = real_loss + fake_loss
- real_loss: D(x_t, x_t_prev, s, t)
- fake_loss: D(x_t, x_t_prev_pred, s, t)
- 补充:只是使用到diffusion的加噪和去噪过程,没有计算x_t和标准高斯分布的距离(diffusion常用的loss)
- diffusion按照随机时间步 t t t预测x_t的特征,和真实的mel经过diffusion的结果,经由判别器判别,监督生成优化,避免陷入单高斯分布。
Active shallow diffusion mechanism
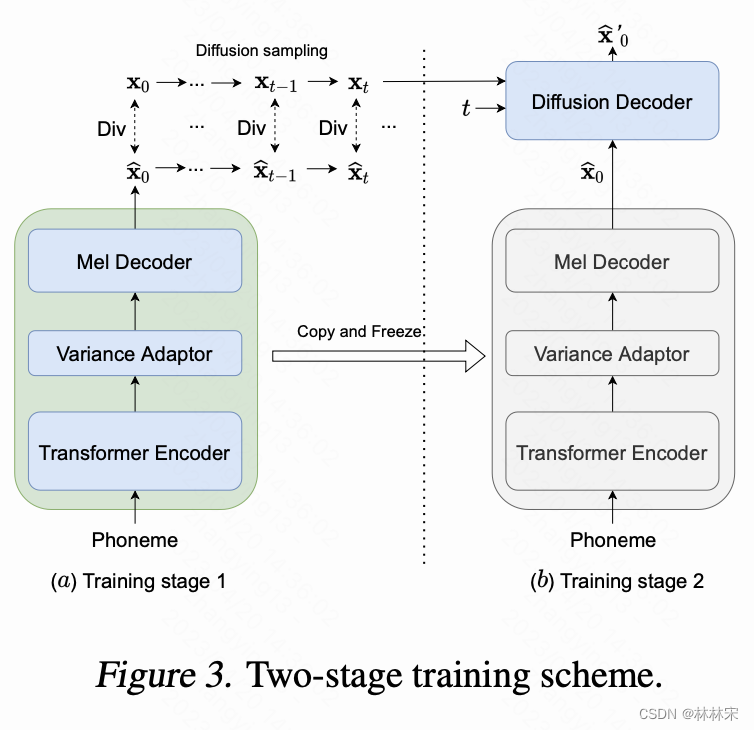
- 为了加速推理过程,提出一种active shallow diffusion mechanism,此方法需要两个步骤的训练:
-
stage1: 训练fastspeech-based 声学模型,输出corse mel (记为 x 0 ^ \widehat{x_0} x0 )作为强先验;
-
stage2: stage1的声学模型参数固定,加diffusion结构,对 corse mel进行加工
损失函数修改 -
before
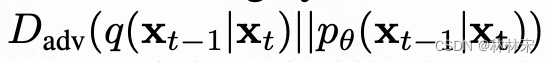
-
now
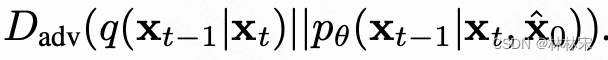
-
- inference阶段,decoder预测 corse mel (记为 x 0 ^ \widehat{x_0} x0 ),经过一步diffusion加噪声处理成 x 1 ^ \widehat{x_1} x1 ,然后再通过一步降噪预测 x 0 x_0 x0