公众号:EDPJ
目录
1. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
3. FD: On understanding the role of deep feature spaces on face generation evaluation
3.2 Fréchet Inception Distance (FID)
4. Addressing Discrepancies in Semantic and Visual Alignment in Neural Networks
5. Addressing Mistake Severity in Neural Networks with Semantic Knowledge
0. 摘要
1. Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
(2017,AdaIN)用自适应实例归一化进行实时的任意风格迁移_EDPJ的博客-CSDN博客
1.1 主要思想
为了解释实例归一化的成功,作者提出了一种新的解释,即实例归一化通过归一化特征统计来执行样式归一化,这些特征统计携带图像的风格信息。基于此,作者提出了自适应实例归一化 (Adaptive Instance Normalization,AdaIN)。 给定内容和风格,AdaIN 只需调整内容图像的均值和方差以匹配风格图像的均值和方差,从而使生成图像具有前者的内容和后者的风格。
1.2 AdaIN
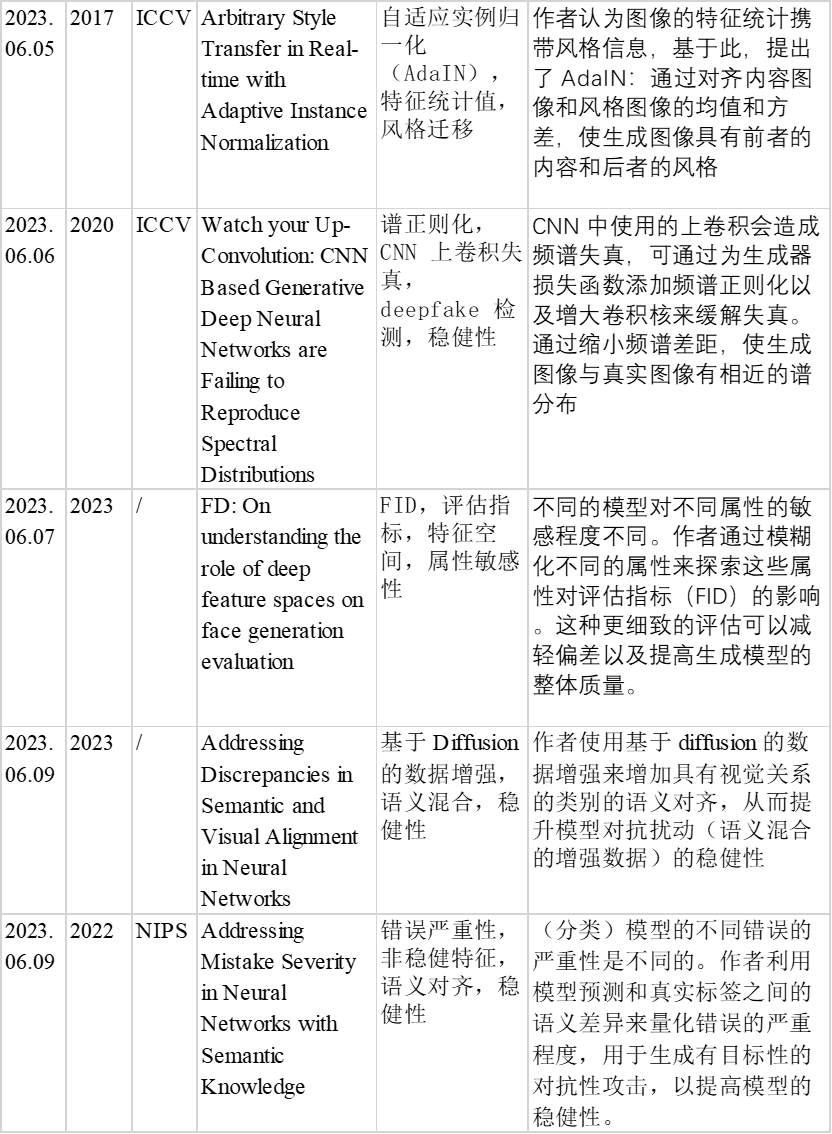
AdaIN 如公式 8 所示:
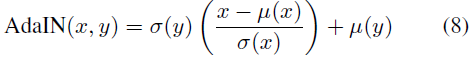
其中,x 和 y 分别表示内容图像和风格图像。μ(x) 和 σ(x) 表示内容图像的均值和标准差,μ(y) 和 σ(y) 表示风格图像的均值和标准差。由于图像的特征统计携带图像的风格信息,通过归一化消除内容图像的风格信息后,再使用风格图像的特征统计(风格信息)进行仿射变换,就能实现风格迁移。
1.3 结构以及不同层使用 AdaIN 的效果


本文使用的网络结构和不同层使用 AdaIN 的效果如上两图所示。
由于 AdaIN 是基于图像特征(特征空间)的统计量进行操作,所以网络中越靠后的层可以提取到越精确地特征。基于这些精确特征的统计值,在实例归一化时可以更充分的消除内容图像的风格,从而实现更高质量的风格迁移。
2. Watch your Up-Convolution: CNN Based Generative Deep Neural Networks are Failing to Reproduce Spectral Distributions
(2020,谱正则化)观察你的上卷积:基于 CNN 的生成深度神经网络无法重现谱分布_EDPJ的博客-CSDN博客
2.1 主要思想
CNN 中使用的上卷积会造成频谱失真,可通过为生成器损失函数添加频谱正则化以及增大卷积核来缓解这种失真。通过缩小频谱差距,使生成图像与真实图像有相近的谱分布,从而提升生成质量。
2.2 上卷积造成的谱失真
线性插值上卷积和补零(灰度值为 0)上卷积分别如上图所示。这两种上卷积都会造成频谱失真。直观地理解是:
- 对于线性插值上卷积,由于填补的像素是原始像素的线性插值,所以相邻像素差异较小,从而导致频谱中低频分量的增加和高频分量的减少。
- 对于补零上卷积,由于原始像素和补零像素差别较大,从而导致频谱中高频分量的增加和低频分量的减少。
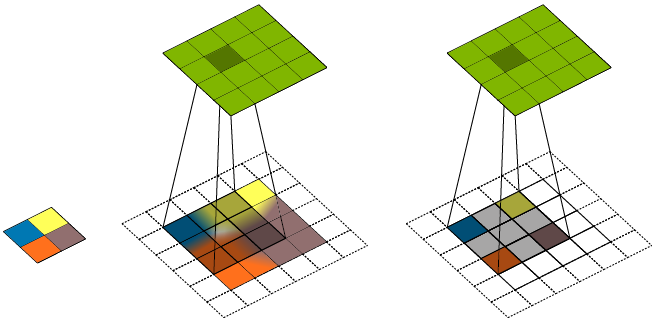
2.3 谱正则化
对图像进行离散傅里叶变换(DFT)获得二维频谱,沿径向进行方位角积分获得一维频谱。新的正则化项就是真实图像和生成图像一维频谱的交叉熵。通过缩小频谱差距,使生成图像与真实图像有相近的谱分布。
2.4 其他贡献
Deepfake 检测。由于现有生成网络中上卷积引起失真的普遍性,频谱失真可以作为一种指标来检测 deepfake。
谱正则化可以提升训练的稳定性。图像的频谱包含丰富的信息,通过使用谱正则化,可以提升模型的频谱意识。在更多信息的作用下,模型学习地更快,并且可以避免模式崩溃。
3. FD: On understanding the role of deep feature spaces on face generation evaluation
(2023,属性敏感性)FD:关于理解深度特征空间对人脸生成评估的作用_EDPJ的博客-CSDN博客
3.1 主要思想
不同的模型对不同属性的敏感程度不同。例如,FD 使用从 ImageNet 训练模型中提取的特征,着重强调帽子而不是眼睛和嘴巴等区域。 此外,使用面部性别分类器特征的 FD 在身份(识别)特征空间中更强调头发长度而不是距离。
作者通过模糊不同的属性来探索这些属性对评估指标(FID)的影响。这种更细致的评估可以减轻偏差以及提高生成模型的整体质量。
3.2 Fréchet Inception Distance (FID)
FID 假设两个 Inception 嵌入图像分布是多元高斯分布,计算公式如公式 1 所示:
![]()
其中 (μ1,Σ1) 和 (μ2,Σ2) 是图像集(即真实图像和生成图像)embedding 的样本均值和协方差,Tr(·) 是矩阵迹。
3.3 样本生成
真实数据集包含显著的属性相关性,为了测试单个属性对评估指标的影响,作者使用生成的数据集。该数据集的生成有两步:
- 首先,合成一组基本面孔,这些面孔表现出浅肤色和短发的预定义统一特征,不包含:面部毛发、化妆、皱眉的表情、帽子或眼镜等与各种面部语义相对应的 12 个二进制属性。
- 然后,分别合成包含上述12个属性的样本。
3.4 实验
实验方法是,保持其他属性不变,仅改变(模糊)一个属性,然后观察它对 FID 的影响。
用于生成的模型是在不同数据集上训练的不同架构的模型,从而获得不同的特征空间。
为了比较不同特征空间的 FID,先计算该特征空间中原始图像与模糊图像之间的 FID,然后除以原始图像和完全模糊图像之间 FID 来获得归一化的 FID。
3.5 分析
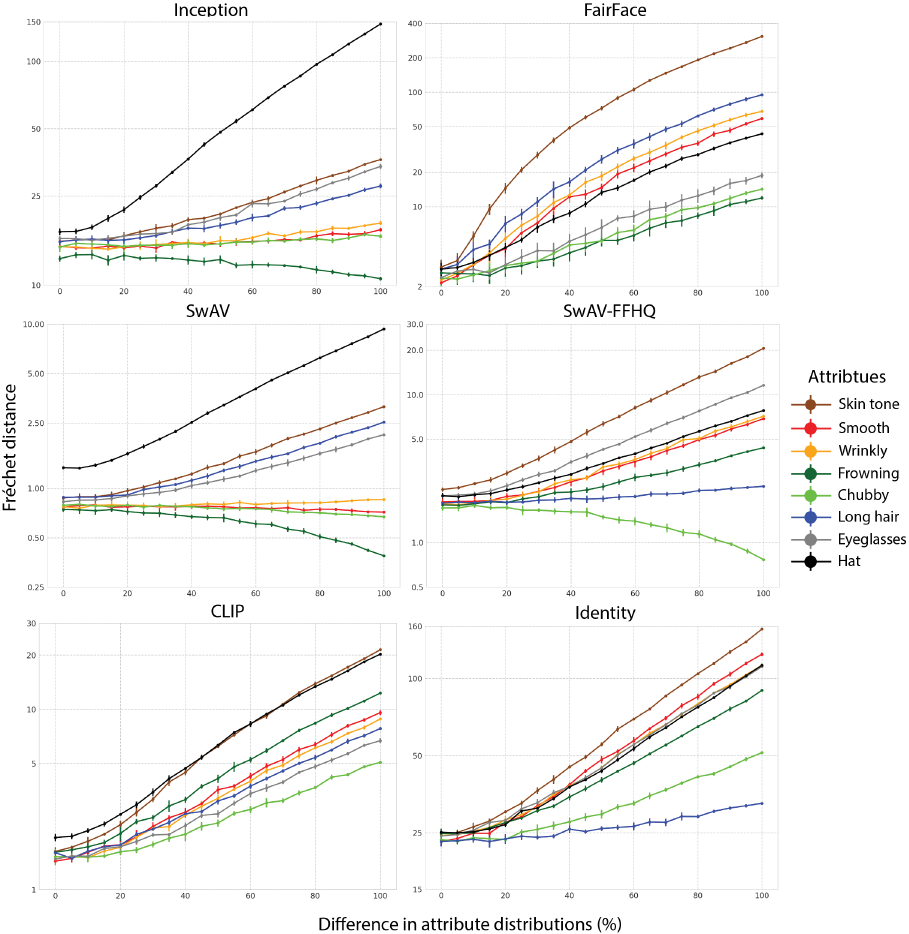
实验的一部分结果如上图所示。以 SwAV-FFHQ(在 FFHQ 上训练的 ResNet-50 模型)为例
- 对头发的模糊程度增加(0%→100%)时,FID 基本没有变化,说明该特征空间对头发这一属性不敏感;
- 对肤色(skin tone)的模糊程度增加(0%→100%)时,FID 明显增加,说明该特征空间对肤色这一属性十分敏感。
差异分析。
- 作者推测这些差异是特征空间捕获与训练期间使用的目标函数最相关的语义特征的结果。
- CLIP 特征对所有研究的特征都很敏感,这可能有两个原因:(1) CLIP 是在海量数据集上训练的,(2) 文本为图像编码器提供了丰富的感知特征信息来源,而这些信息是无法通过经典监督学习的。
- 虽然特征空间使用了在架构类型、大小和最终层特征数方面各不相同的网络, 这些因素会对实验结果造成影响,但作者认为更大的影响来自于训练集和目标函数。
4. Addressing Discrepancies in Semantic and Visual Alignment in Neural Networks
(2023,语义混合)处理神经网络中语义和视觉对齐的差异_EDPJ的博客-CSDN博客
4.1 主要思想
作者使用基于 diffusion 的数据增强来增加具有视觉关系的类别的语义对齐,从而提升模型对抗扰动的稳健性。
4.2 语义混合
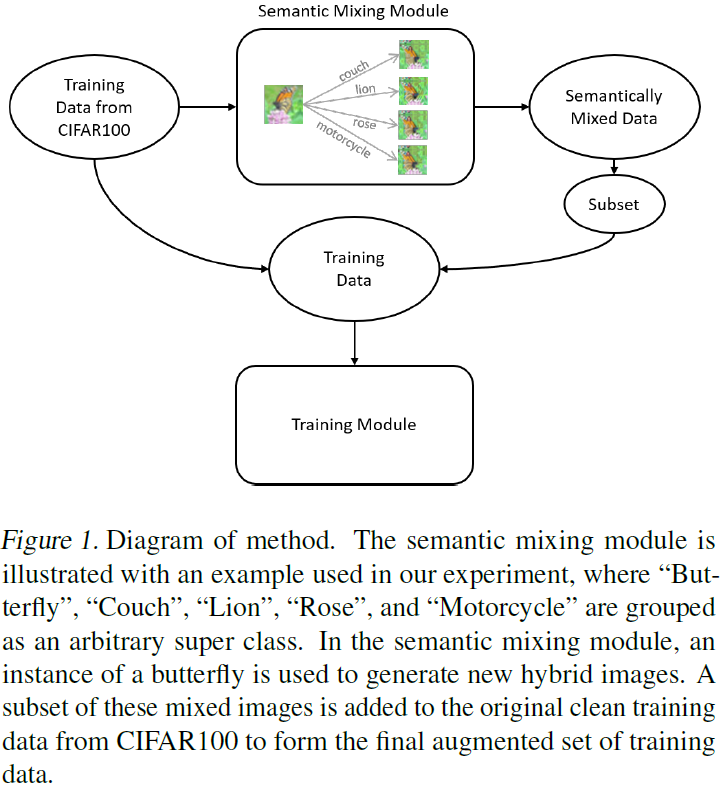

基于 diffusion 的数据增强 MagicMix 对图像进行语义混合,流程如图 1 所示。语义混合的结果如图 2 所示。以第 4 列(椅子到公交车)为例,随着语义混合程度的加深(0% → 50% → 75%),椅子的外观表现得越来越像公交车。
4.3 方法
使用纯净数据 + 语义混合数据训练模型,使模型在有扰动的情况下,依然能够进行准确的分类,即,提升了模型的稳健性。
5. Addressing Mistake Severity in Neural Networks with Semantic Knowledge
(2022,错误严重性)用语义知识处理神经网络中的错误严重性_EDPJ的博客-CSDN博客
5.1 主要思想
(分类)模型的不同错误的严重性是不同的。作者利用模型预测和真实标签之间的语义差异来量化错误的严重程度,用于生成有目标性的对抗性攻击,以提高模型的稳健性。
5.2 名词解释
错误严重性:对于自动驾驶系统,把行人误判为树枝 vs 把行人误判为骑自行车的人,明显前者有更低的语义相似性,同时也表示更高的错误严重性。
错误的语义对齐:如上所述,即使模型预测出错,也应该尽量使预测的错误标签与真实标签有更接近的语义相似性(做法就是语义对齐),从而降低错误严重性。
模型稳健性:在有扰动的条件下,模型的预测精度不变或是仅有略微的降低。此外,即使出错,也应该有较低的错误严重性。
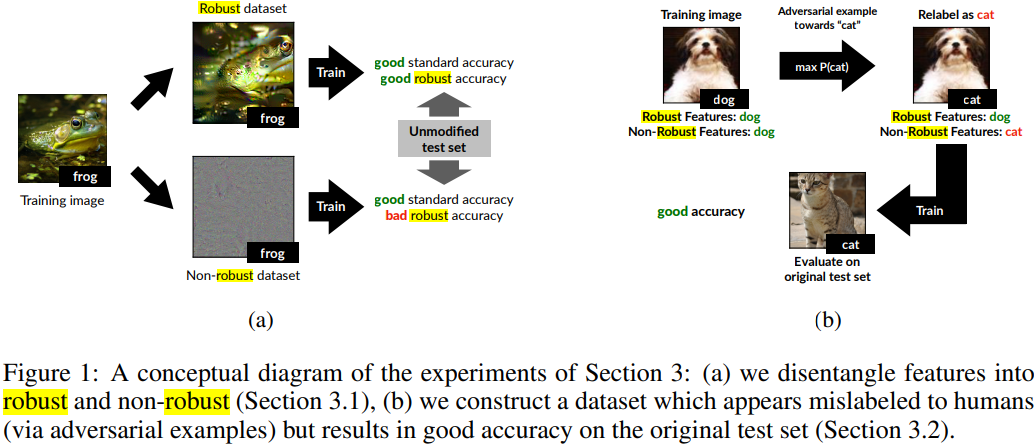
稳健特征与非稳健特征:图像的特征可以分为稳健特征和非稳健特征。如下图所示,图像来源于Ilyas (2019) 等人的论文 “Adversarial Examples Are Not Bugs, They Are Features”。
- 非稳健特征可以为分类模型预测提供信息,但人类难以察觉。例如在对抗防御中,为图像添加微小的扰动,在人类看来,图像并未发生变化,但是模型缺可能把该图像误判为其他类别。
- 而稳健特征不受扰动的影响。
5.3 方法
使用分阶段训练:
第一阶段使用语义目标性对抗训练,把语义知识嵌入到训练过程中。与非目标性方法(找到会导致任何错误分类的扰动,而不考虑错误标签是什么)不同,这种方法会产生扰动,骗模型预测指定的(目标)类别。
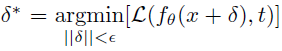
目标 t 是从一组与图像 x 的原始标签 y 语义相似的类 C(y) 中选择的。C(y) 是与 y 的语义相似度最高的五个标签的集合。该式促使找到范围 ε 内使模型误判为 t 的扰动 δ* 。
第二阶段进行标准训练。如下式所示。即使出现可能使模型发生误判的扰动,模型依然能够进行正确判断。即,通过训练提升了模型的稳健性。
![]()
5.4 分析
经过分阶段训练后,模型的稳健性提升,不容易因为扰动而发生误判。而且即使误判,也会预测与真实标签语义接近的标签,降低了错误严重性。