NLP入门教程系列
文章目录
前言
RNN是在NLP中非常经典的模型,RNN 的特征就在于拥有这样一个环路(或回路)。这个环路可以使数据不断循环。通过数据的循环,RNN 一边记住过去的数据,一边更新到最新的数据
一、RNN结构基本介绍
rnn的网络结构,其实相较于cnn还是较为简单的一点的,如下图
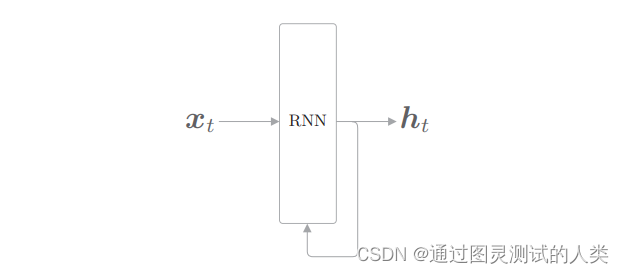
有一个输入为x,经过网络后一部分输出为h,然后其中h的一份复制会作为输入重新回到rnn中。将上述图展开以后,可以得到下面的图
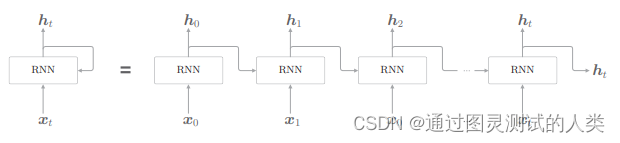
可以看到,0时刻的输出会作为1时刻的输入并且同1时刻的x一起输入到网络中,
其中
h t = t a n h ( h t − 1 W h + x t W x + b ) h_t = tanh(h_{t−1}W_h + x_tW_x + b) ht=tanh(ht−1Wh+xtWx+b)
RNN 有两个权重,分别是将输入 x转化为输出 h 的权重 Wx 和将前一个 RNN 层的输出转化为当前时刻的输出的权重 W h W_h Wh。此外,还有偏置 b。这里, h t − 1 h_{t−1} ht−1 和 x t x_t xt都是行向量
许多文献中将 RNN 的输出 h t h_t ht称为隐藏状态(hidden state)或隐藏状态向量(hidden state vector)
二、反向传播
1.Backpropagation Through Time
将 RNN 层展开后,就可以视为在水平方向上延伸的神经网络,因此RNN 的学习可以用与普通神经网络的学习相同的方式进行。同理,反向传播也可以按照普通的方式进行。但是,当时序数据的时间跨度的增大,消耗的资源会非常多,并且梯度也会出现不稳定。
2.Truncated BPTT
在处理长时序数据时,通常的做法是将网络连接截成适当的长度。具体来说,就是将时间轴方向上过长的网络在合适的位置进行截断,从而创建多个小型网络,然后对截出来的小型网络执行误差反向传播法,这个方法称为 Truncated BPTT。在处理长度为 1000 的时序数据时,如果展开 RNN 层,它将成为在水平方向上排列有 1000 个层的网络。当然,无论排列多少层,都可以根据误差反向传播法计算梯度。但是,如果序列太长,就会出现计算量或者内存使用量方面的问题。此外,随着层变长,梯度逐渐变小,梯度将无法向前一层传递。因此,如图所示,
我们来考虑在水平方向上以适当的长度截断网络的反向传播的连接

这样的话,截断了反向传播的连接,以使学习可以以 10 个RNN 层为单位进行。像这样,只要将反向传播的连接截断,就不需要再考虑块范围以外的数据了,因此可以以各个块为单位(和其他块没有关联)完成误差反向传播法
3.Truncated BPTT的mini-batch学习
在探讨 Truncated BPTT 时,并没有考虑 mini-batch 学习。换句话说,我们之前的探讨对应于批大小为 1 的情况。因此,在输入数据的开始位置,需要在各个批次中进行“偏移”。对长度为1000的时序数据,以时间长度10为单位进行截断。此时,如何将批大小设为 2 进行学习呢?在这种情况下,作为 RNN 层的输入数据,第 1 笔样本数据从头开始按顺序输入,第 2 笔数据从第 500 个数据开始按顺序输入。也就是说,将开始位置平移 500

总结
以上就是今天简单总结的内容,本文仅仅简单介绍了rnn,具体使用的示例代码会在后面给出