敏感词检测
敏感词的检测,一般是建立一个敏感词库,然后判断字符串中是否存在敏感词库中的某些词汇,然后将其过滤或者替换显示为其他文本,这对于一个和谐的网络环境是及其必要的,接下来就我们看看敏感词检测的实现方式有哪些。
传统方式
对于传统的敏感词检测,一般是将全部的敏感词放在集合中,然后循环遍历检测敏感词:
List<String> sensitiveList = Arrays.asList("阿巴阿巴", "花姑娘", "吊毛吃猪肉");
String text="花姑娘吃猪肉";
for (String s : sensitiveList) {
boolean hit = text.contains(s);
System.out.println(hit);
}
很明显,这种实现方式虽然很简单,但是敏感词库过大时,一次判断就要进行几万甚至十几万次循环判断,这是很耗时的。因此我们引入了敏感词检测的第二种方式。
有限状态机(DFA)
在 DFA 中,给定一个输入序列,DFA 通过根据输入和当前状态查找状态转移函数中的规则来决定下一个状态,最终判断是否接受输入。具体是怎么弄的呢。简单来说就是将所有敏感词的前缀复用起来,构造前缀树,这棵树记录了敏感词库中所有词可能构成的全部状态。
前缀树
比如现在有几个敏感词:吊毛吃猪肉、吊毛很帅、你很帅、你很笨、ctm…我们可以将其按照树形结构,构造成这样:
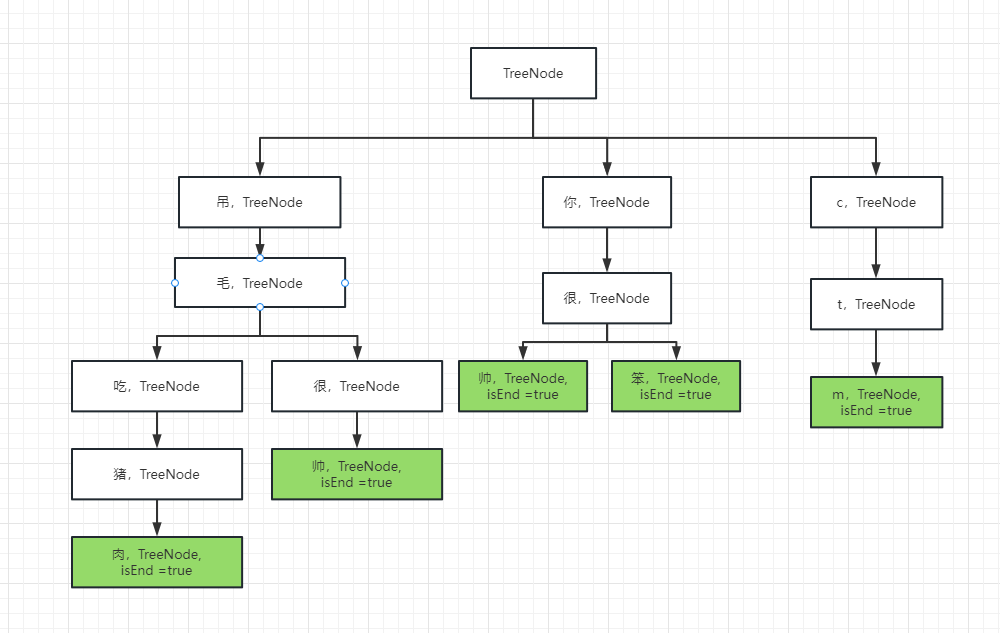
在检测时,循环检测字符串,只要遇到有结束标识(图中绿色的部分),就表明存在敏感词,这样一来,不仅能够节省内存空间,还能够减少判断次数。
前缀树结构
作为一棵树,那么它的结构也是很简单的:
/**
* 前缀树
*/
private static class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
// 子节点(key是下级字符,value是下级节点)
private final Map<Character, TrieNode> subNodes = new HashMap<>();
}
构造前缀树
我们只需要获取全部敏感词,依次对每个字符进行判断,完成构造即可:
/**
* 将一个敏感词添加到前缀树中
*
* @param keyword 敏感词
*/
private void addKeyword(String keyword) {
TrieNode tempNode = ROOT_NODE;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if (subNode == null) {
// 初始化子节点
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指向子节点,进入下一轮循环
tempNode = subNode;
// 设置结束标识
if (i == keyword.length() - 1) {
tempNode.setKeywordEnd(true);
}
}
}
敏感词判断
当拿到待检测的字符串,我们需要遍历该字符串,然后从树的根节点开始,不断获取子节点,当前所处节点达到某一个节点的结束标识为true时,代表目前的位置是一串敏感词,将其替换为***;然后继续从下一个字符开始,将树的节点指向根节点,继续检测,直到字符串遍历完成,具体代码如下:
/**
* 过滤敏感词
*
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public static String filter(String text) {
if (StringUtils.isEmpty(text)) {
return null;
}
// 指针1
TrieNode tempNode = ROOT_NODE;
// 指针2
int begin = 0;
// 指针3
int position = 0;
// 结果
StringBuilder sb = new StringBuilder();
while (position < text.length()) {
char c = text.charAt(position);
// 跳过符号
if (isSymbol(c)) {
// 若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode == ROOT_NODE) {
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if (tempNode == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = ROOT_NODE;
} else if (tempNode.isKeywordEnd()) {
// 发现敏感词,将begin~position字符串替换掉
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = ROOT_NODE;
} else {
// 检查下一个字符
position++;
}
}
// 将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
/**
* 判断是否为符号
*
* @param c 字符
* @return 判断
*/
private static boolean isSymbol(Character c) {
// 0x2E80~0x9FFF 是东亚文字范围
return !isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
public static boolean isAsciiAlpha(char ch) {
return isAsciiAlphaUpper(ch) || isAsciiAlphaLower(ch);
}
public static boolean isAsciiAlphaUpper(char ch) {
return ch >= 'A' && ch <= 'Z';
}
public static boolean isAsciiAlphaLower(char ch) {
return ch >= 'a' && ch <= 'z';
}
public static boolean isAsciiNumeric(char ch) {
return ch >= '0' && ch <= '9';
}
public static boolean isAsciiAlphanumeric(char ch) {
return isAsciiAlpha(ch) || isAsciiNumeric(ch);
}
结语
到此,我们可以得出结论,使用构造前缀树来完成敏感词检测,比起传统的遍历集合检测,能够节省些许的内存空间,而且在查询效率上有了提升。但是依然还存在着一些小问题,比如不能够完成多模式匹配。
什么是多模匹配?
比如敏感词abc和bcd。
匹配字符串abcde。
单模匹配后:***de
多模匹配后:****e

如果有兴趣,可以继续下去研究一下。