前言
最近在做yolov5识别手势的项目,爬了很多坑,也排除了不少bug,记录一下。参考前人的经验,遇到写得好的文章我会推荐。我主要讲一下这些bug,若有不足之处,欢迎评论指出。
炼丹方法
收集数据集
1、爬取数据
这里主要参考网上爬虫代码就好了,我有一个代码但不是我写的就不分享了。
优点:可以简单获得大量数据
缺点:网上简单爬取的数据质量良莠不齐,基本质量很差
2、使用plotplayer制作
数据集要求:
下面给出两个链接讲得很详细了,我补充一点:根据实际需求灵活应变,贴近使用环境。
参考链接:
添加链接描述
添加链接描述
准备视频,打开potplayer,按快捷键:alt+g。
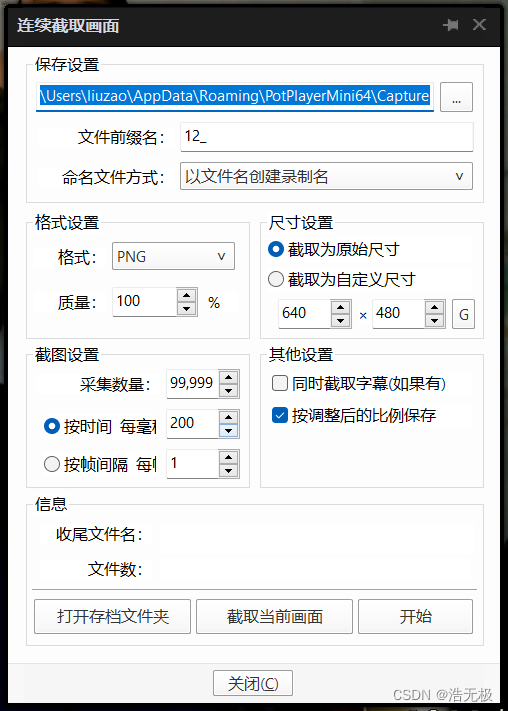
自己可以探索plotplayer其他设置。我给出一个推荐方法:
采集数量99999(保证能截取整个视频),按200ms截取。
稍微人工处理一下数据,去除一些模糊的,质量不好的图片。
划分数据集
网上大部分方法是VOC数据集的划分,但我这个是YOLO格式的数据集。
1、先用这位博主的代码对数据集划分,修改源文件路径和新文件路径即可
数据集划分代码
import os
import random
from shutil import copy2
# 源文件夹路径
file_path = r"D:/Code/Data/centerlinedata/tem_voc/JPEGImages/"
# 新文件路径
new_file_path = r"D:/Code/Data/GREENTdata/"
# 划分数据比例6:2:2
split_rate = [0.6, 0.2, 0.2]
class_names = os.listdir(file_path)
# 目标文件夹下创建文件夹
split_names = ['train', 'val', 'test']
print(class_names) # ['00000.jpg', '00001.jpg', '00002.jpg'... ]
# 判断是否存在目标文件夹,不存在则创建---->创建train\val\test文件夹
if os.path.isdir(new_file_path):
pass
else:
os.makedirs(new_file_path)
for split_name in split_names:
split_path = new_file_path + "/" + split_name
print(split_path) # D:/Code/Data/GREENTdata/train, val, test
if os.path.isdir(split_path):
pass
else:
os.makedirs(split_path)
# 按照比例划分数据集,并进行数据图片的复制
for class_name in class_names:
current_data_path = file_path # D:/Code/Data/centerlinedata/tem_voc/JPEGImages/
current_all_data = os.listdir(current_data_path)
current_data_length = len(current_all_data) # 文件夹下的图片个数
current_data_index_list = list(range(current_data_length))
random.shuffle(current_data_index_list)
train_path = os.path.join(new_file_path, 'train/') # D:/Code/Data/GREENTdata/train/
val_path = os.path.join(new_file_path, 'val/') # D:/Code/Data/GREENTdata/val/
test_path = os.path.join(new_file_path, 'test/') # D:/Code/Data/GREENTdata/test/
train_stop_flag = current_data_length * split_rate[0]
val_stop_flag = current_data_length * (split_rate[0] + split_rate[1])
current_idx = 0
train_num = 0
val_num = 0
test_num = 0
# 图片复制到文件夹中
for i in current_data_index_list:
src_img_path = os.path.join(current_data_path, current_all_data[i])
if current_idx <= train_stop_flag:
copy2(src_img_path, train_path)
train_num += 1
elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):
copy2(src_img_path, val_path)
val_num += 1
else:
copy2(src_img_path, test_path)
test_num += 1
current_idx += 1
print("Done!", train_num, val_num, test_num)
划分完成
2、建立下面的文件结构:
all_split # 这是刚才划分完成的文件夹
images
train # 刚才划分的训练图片
val # 刚才划分的验证图片
labels
train # 训练标签,用labelimg打标签的路径
val # 验证标签,用labelimg打标签的路径
test # 刚才划分的测试图片
A.yaml # 配置文件
A.yaml配置如下:

3、接下来用labelimg对训练集和验证集标注即可
参考链接:
添加链接描述
添加链接描述
yolov5模型训练
炼丹主要参考这个博主的方法,我提出几点注意事项
教程:超详细从零开始yolov5模型训练
1、batch一定要设置的小一点
如果不清楚到底能设多大,可以用auto batch参数,即设置为 -1
python train.py --img 640 --batch -1 --data ./yolo_A/A.yaml --weights yolov5s.pt --cache
运行这行代码,如下显示,自动选择了15作为batch参数

这是2080ti的显卡,所以你掂量掂量自己显卡能用多少吧。其实这个参数和网络复杂程度有关,相同数据集,网络越复杂,batch size越小,这里使用yolov5l.pt。之前使用yolov5s.pt的时候,auto batch就显示为47。深度学习,哈哈,算力学习吧
建议:知道了大概batch设置多大,手动设置为2的指数,这样方便GPU运算
一些batch设置过大的错误:



总结了一下:和cuDNN有关的报错,内存之类的报错,都可以怀疑一下batch参数。
2、博主没有进行数据集划分,科学的训练数据集是需要的。但博主是带人入门,可以理解。
数据集划分可以参考我上面介绍的方法。
数据集划分意义
简单提升训练效果的措施
1、选择质量高的图片,划分数据集进行交叉验证
2、yolov5l.pt–折中的选择
如图所示,yolov5l速度慢一点,却能换来AP指标的大大提升。

3、多GPU训练,提高batch size
虽然前面我说到不要设置太高batch size,但这是建立在你硬件设备基础上的。如果实验室有GPU可以利用,那么考虑多GPU训练,提高batch size,这个效果很显著。
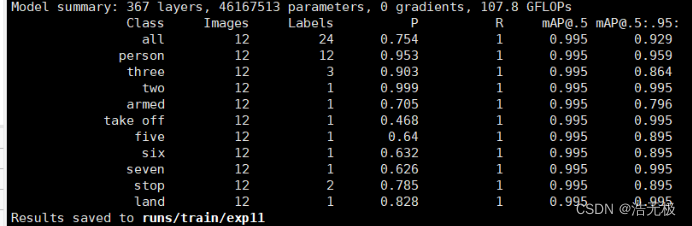
关于batch size的理解
没使用多GPU训练前的验证情况:
使用多GPU训练后的验证情况:
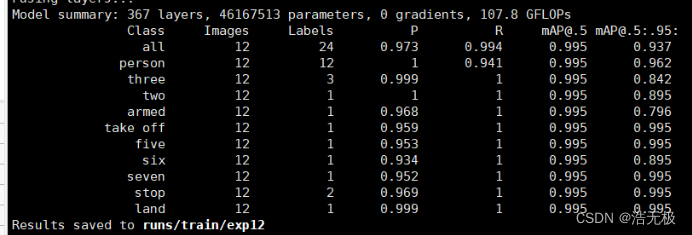
当然,这仅是特例,但方法值得尝试一下,又不需要知道太多原理性东西。
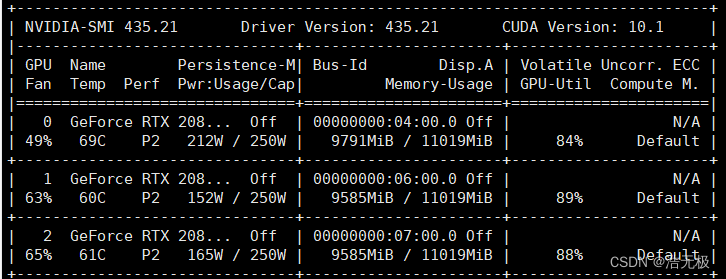
如下图所示,是多GPU训练batch设置过高的报错。对了,多GPU训练不能使用auto batch。

3个GPU训练,设置64 batch size会报错,好像是因为不能整除3。设置48就好了。
官网介绍链接
torch.distributed.run是最新pytorch版本的,旧版本使torch.distributed.launch
4、关于训练策略,这有篇文章写得不错,可以了解一下。
添加链接描述
关于参数的说明
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs, -1 for autobatch')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='train, val image size (pixels)')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='image --cache ram/disk')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
# Logger arguments
parser.add_argument('--entity', default=None, help='Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='Version of dataset artifact to use')
return parser.parse_known_args()[0] if known else parser.parse_args()
–weight参数:预训练的权重文件,例如:yolov5s.pt, yolov5l.pt
–cfg:训练的模型文件,默认是yolov5s.yaml(代码默认是空的,如果不指定就根据weight参数决定模型参数。如果指定的话,以指定的模型文件为主。)
–data:训练数据的位置
–hyp:超参数,一般不使用
–epochs:训练轮数,默认是100
–batch-size:默认是16
–imgsize or --img or --imgsz:默认640,必须是32的倍速,暂时不需要更改
–resume:断点训练
–nosave:仅保存最后一个检查点数据
–device:使用cuda设备
–cache:利用缓存加速
–workers:cpu加载数据的工作进程,影响训练速度,会占用cpu内存,越大训练速度越快。但是到达瓶颈后,不升反降,也可能超过cpu负载报错。
–hyp:超参数进化,这个可以试试
注意:只要训练参数一致,数据没有更改,无论训练多少次,结果都是一样的,包括提示信息、result.png等,不存在多次训练看平均效果的说法
结语
沉迷炼丹,无法自拔!
