需求:
三个不同的dfs中存在不同的多个节点id,现在需要求出不同的dfs之间的节点对应关系,比如,哪些节点在某一个dfs,但是不在另一个dfs中
思路:
一、 如果是单纯计算dfs中节点数量,则可以使用scala,代码如下:
1 准备原始数据
将原始数据存放在文本文件dfs_id中(本文通过subline),格式如下:
2415,2416,2417,2418,2419,2421,2422,2423,2424,2425,2426,2427,2428,2429,2430,2431,2432,2433,2434,2435,2436,2437,2438,2439,2440,2441,2442,2443,2444,2445,2446,2447,2448,2449,2450,2541,2542,2544,2724,3124,3126,2605,2606,3133,3194,3272,3271,3273,3274,3302,3313,3314,3652,3654,3657,3944
2 计算代码
1. 在【spark】/bin目录下启动spark:
spark-shell --master=local
2. 读取源数据文件,创建rdd
scala> var rdd = sc.textFile("/Users/wooluwalker/Desktop/dfs_id")
rdd: org.apache.spark.rdd.RDD[String] = /Users/wooluwalker/Desktop/dfs_id MapPartitionsRDD[2] at textFile at <console>:24
3. 计算id个数
scala> rdd.flatMap(x=>x.split(',')).count()
res3: Long = 56
3 上述代码只用于个数的计算,不能用于不同dfs之间的id对比,为了是实现这个功能,推荐使用hive
二、 使用hive将不同dfs的id汇总到一张表中
1 创建表 tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split 结构相同,如下: line string 2 上传对应的数据到不同的表中 load data local inpath '/Users/wooluwalker/Desktop/dfs_3_taskid' into table tb_dfsid_3_confluence_task_id_split; load data local inpath '/Users/wooluwalker/Desktop/dfs_137_taskid' into table tb_dfsid_137_confluence_task_id_split; 3 将tb_dfsid_137_confluence_task_id_split,tb_dfsid_3_confluence_task_id_split一横行的数据拆分成一纵列,
放到tb_dfsid_137_confluence_task_id_split_vertical,tb_dfsid_3_confluence_task_id_split_vertical: create table if not exists tb_dfsid_137_confluence_task_id_split_vertical as select * from ( select explode(split(line,",")) as dfsid_137 from tb_dfsid_137_confluence_task_id_split ) tmp; create table if not exists tb_dfsid_3_confluence_task_id_split_vertical as select * from ( select explode(split(line,",")) as dfsid_137 from tb_dfsid_3_confluence_task_id_split
) tmp;
4 创建表tb_dfsid_3_137_confluence_task_id_compare,汇总对比dfs_3和dfs_137下的节点
create table if not exists tb_dfsid_3_137_confluence_task_id_compare
select dfsid3, dfsid137
from
tb_dfsid_3_confluence_task_id_split_vertical id3
full outer join
tb_dfsid_137_confluence_task_id_split_vertical id137
on id3.dfsid3 = id137.dfsid137;
dfs_3 与dfs_137的节点对比如下(部分):
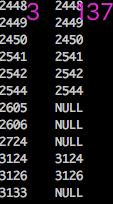
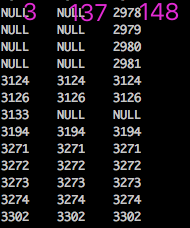
同样也可得到 dfs_3 与dfs_137 dfs_137之间的对比:
注:
- 子查询必须有select表的别名!!!!
- 子查询中必须指明字段的别名(as dfsid_137),否则据此创建出来的表 tb_dfsid_137_confluence_task_id_split_vertical 列名为col,不利于后续计算