一.Tensor element types
1.Specifying the numeric type with dtype
The default data type for tensors is 32-bit floating-point.
torch.float32 or torch.float: 32-bit floating-point
torch.float64 or torch.double: 64-bit, double-precision floating-point
torch.float16 or torch.half: 16-bit, half-precision floating-point
torch.int8: signed 8-bit integers
torch.uint8: unsigned 8-bit integers
torch.int16 or torch.short: signed 16-bit integers
torch.int32 or torch.int: signed 32-bit integers
torch.int64 or torch.long: signed 64-bit integers
torch.bool: Boolean
2.A dtype for every occasion
In order to allocate a tensor of the right numeric type, we can specify the proper dtype as an argument to the constructor.
import torch
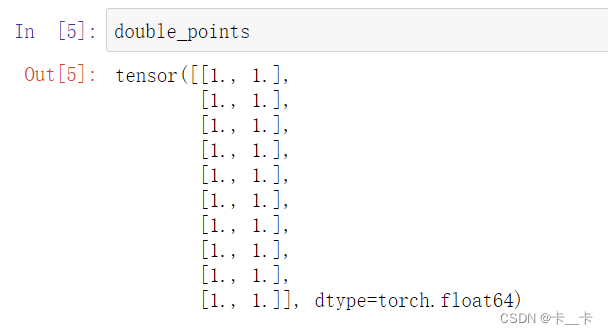
double_points=torch.ones(10,2,dtype=torch.double)
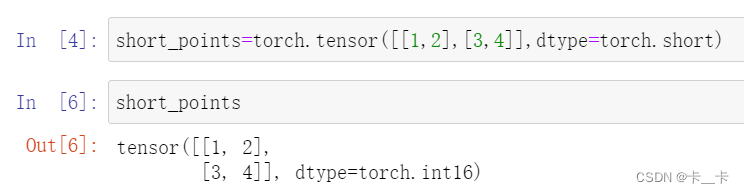
short_points=torch.tensor([[1,2],[3,4]],dtype=torch.short)
We can find out about the dtype for a tensor by accessing the corresponding attribute:

We can also cast the output of a tensor creation function to the right type using the corresponding casting method.
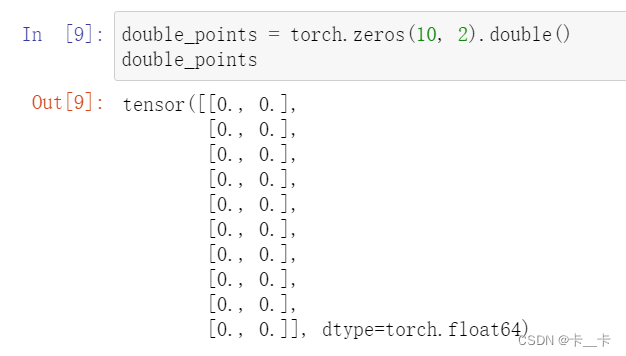
double_points = torch.zeros(10, 2).double()
or the more convenient to method:
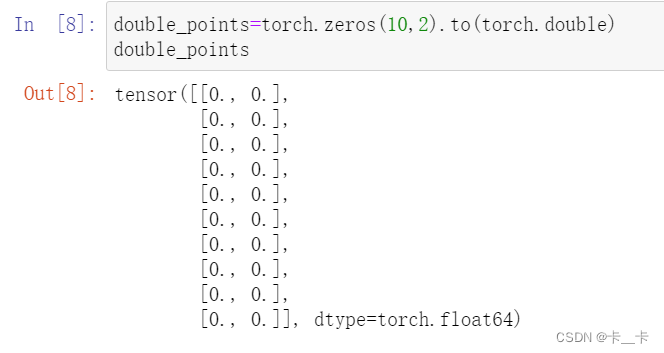
double_points=torch.zeros(10,2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)
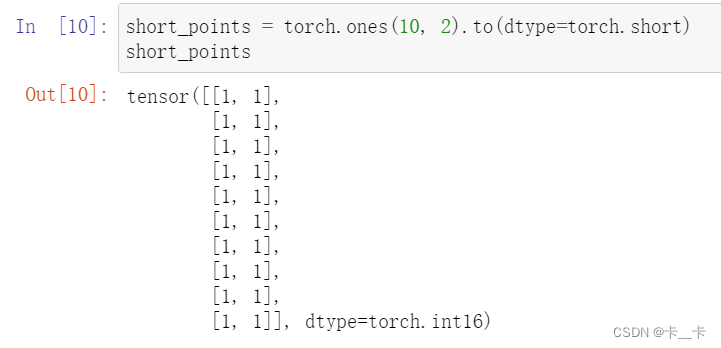
Conclusion
double_points=torch.ones(10,2,dtype=torch.double)
double_points = torch.zeros(10, 2).double()
double_points=torch.zeros(10,2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)
Next
a = torch.rand(5, dtype=torch.double) # 随机生成一个大小为5的一维张量
# 使用rand生成的随机数范围是0到1之间

b=a.to(torch.short) # 取整数部分

When mixing input types in operations, the inputs are converted to the larger type automatically.

二.Memory function
1.Indexing into storage
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()
Even though the tensor reports itself as having three rows and two columns, the storage under the hood is a contiguous array of size 6. In this sense, the tensor just knows how to translate a pair of indices into a location in the storage.The layout of a storage is always one-dimensional.

We can also index into a storage manually.
points.storage()[0] # out:4.0
Next
points_2 = torch.tensor([[4.0, 1.0, 5.0], [3.0, 2.0, 1.0]])
points_2.storage()

points_3 = torch.tensor([4.0, 1.0, 5.0, 3.0, 2.0, 1.0])
points_3.storage()

Multiple tensors can index the same storage even if they index into the data differently.
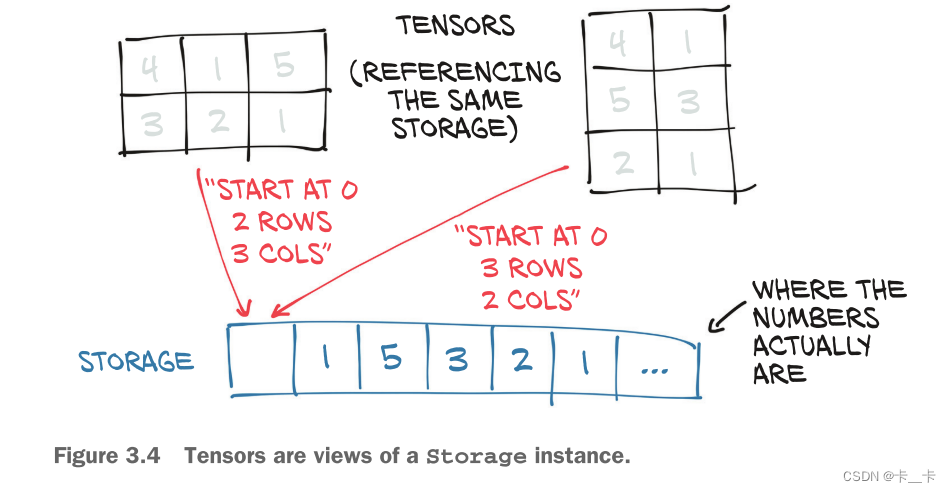
Changing the value of a storage leads to changing the content of its referring tensor.
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()

points_storage()[0] = 2.0
points

2.Modifying stored values: In-place operations
The zero_ method zeros out all the elements of the input. Any method without the trailing underscore leaves the source tensor unchanged and instead returns a new tensor.
a=torch.ones(3,2)
a.zero_()
a

They are recognizable from a trailing underscore in their name, like zero_, which indicates that the method operates in place by modifying the input instead of creating a new output tensor and returning it.
3.Tensor metadata: Size, offset, and stride
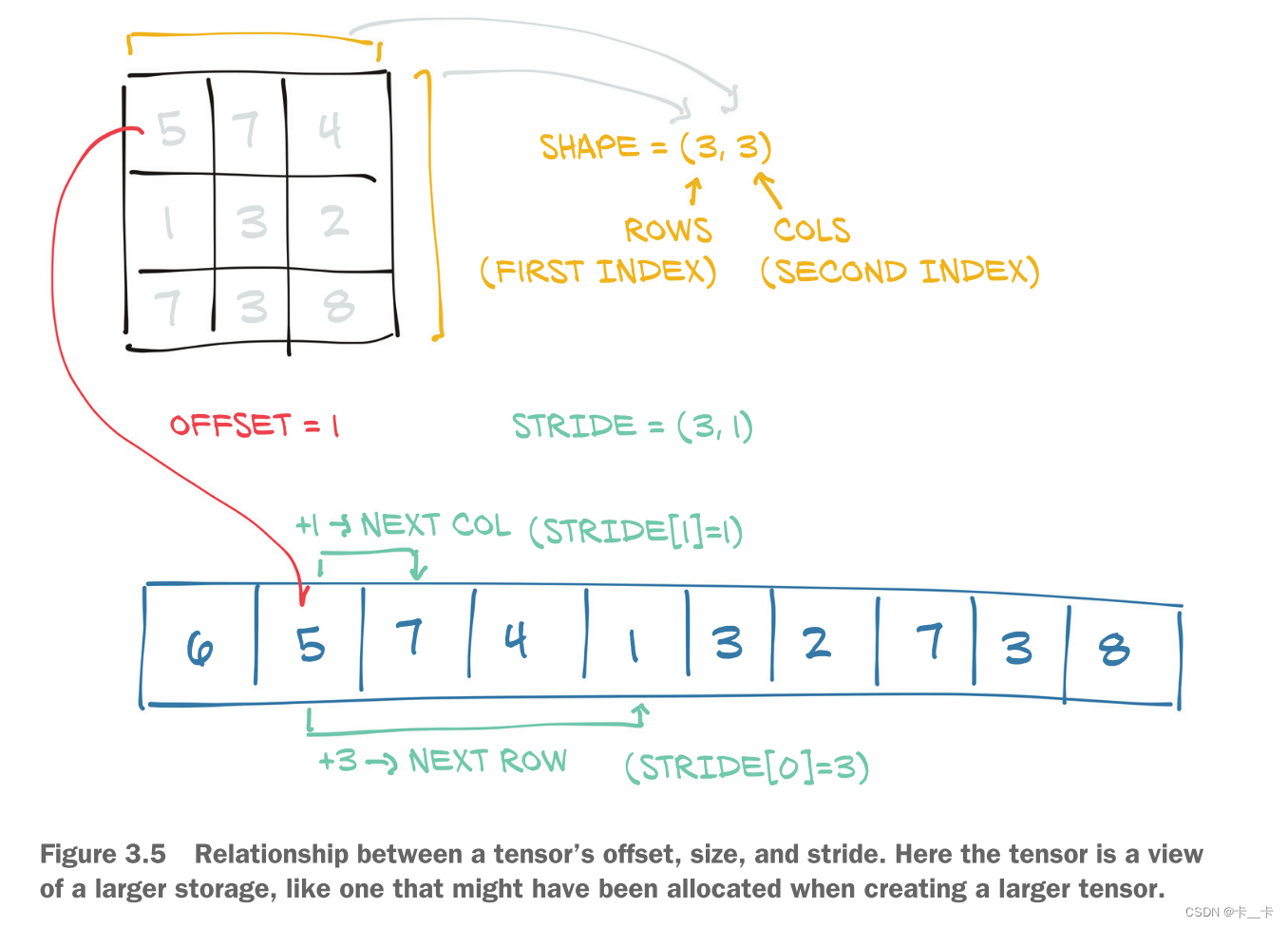
The size (or shape, in NumPy parlance) is a tuple indicating how many elements across each dimension the tensor represents.The storage offset is the index in the storage corresponding to the first element in the tensor. The stride is the number of elements in the storage that need to be skipped over to obtain the next element along each dimension.
import torch
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
print(second_point)
print(second_point.storage_offset())

The resulting tensor has offset 2 in the storage (since we need to skip the first point, which has two items).
It’s important to note that this is the same information contained in the shape property of tensor objects:
second_point.shape

The stride is a tuple indicating the number of elements in the storage that have to be skipped when the index is increased by 1 in each dimension.
points.stride()

second_point.stride()

Accessing an element i, j in a 2D tensor results in accessing the storage_offset + stride[0] * i + stride[1] * j element in the storage. The offset will usually be zero; if this tensor is a view of a storage created to hold a larger tensor, the offset might be a positive value.
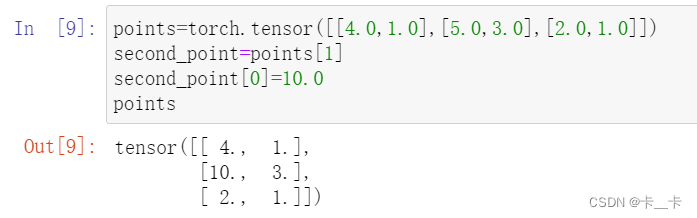
Changing the subtensor will have a side effect on the original tensor:
points=torch.tensor([[4.0,1.0],[5.0,3.0],[2.0,1.0]])
second_point=points[1]
second_point[0]=10.0
points
we can eventually clone the subtensor into a new tensor:
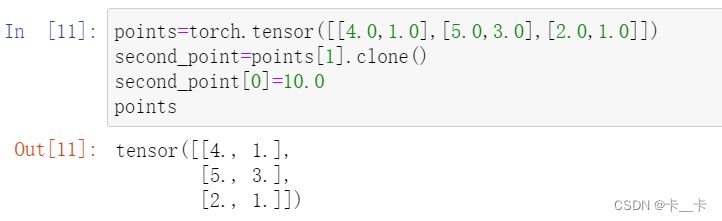
points=torch.tensor([[4.0,1.0],[5.0,3.0],[2.0,1.0]])
second_point=points[1].clone()
second_point[0]=10.0
points
4.Transposing without copying
t function, a shorthand alternative to transpose for two-dimensional tensors:
points.t()

We can easily verify that the two tensors share the same storage
b=points.t()
id(points.untyped_storage()) == id(b.untyped_storage())

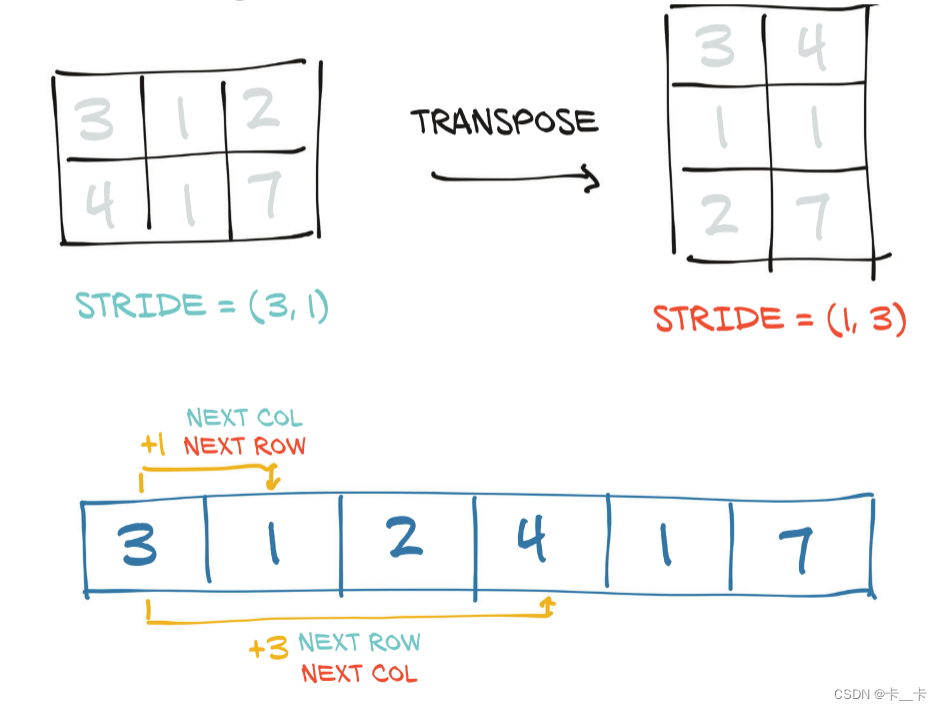
and that they differ only in shape and stride:
print(points.stride())
print(points.t().stride())

but

So
No new memory is allocated: transposing is obtained only by creating a new Tensor instance with different stride ordering than the original.
5.Transposing in higher dimensions
引入:维度
a=torch.ones(2,3)
out: # 2行3列
tensor([
[1., 1., 1.],
[1., 1., 1.]
])
a=torch.ones(2,2,3)
out: # 2块,每块2行3列
tensor([
[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]
])
a=torch.ones(2,2,2,3)
out: # 2块,每块里面有2块,每块是2行3列
tensor([
[
[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]
],
[
[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]
]
])
a=torch.ones(3,2,2,2,3)
out: # 3块,每块有2块,每块有2块,每块2行3列
# 为方便描述,在下文中第1个参数叫做第0维,第2个参数叫做第1维...
tensor([
[
[
[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]
],
[[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]]
],
------------------------
[[[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]]],
-----------------------
[[[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]],
[[[1., 1., 1.],
[1., 1., 1.]],
[[1., 1., 1.],
[1., 1., 1.]]]]
])
Let’s see stride()
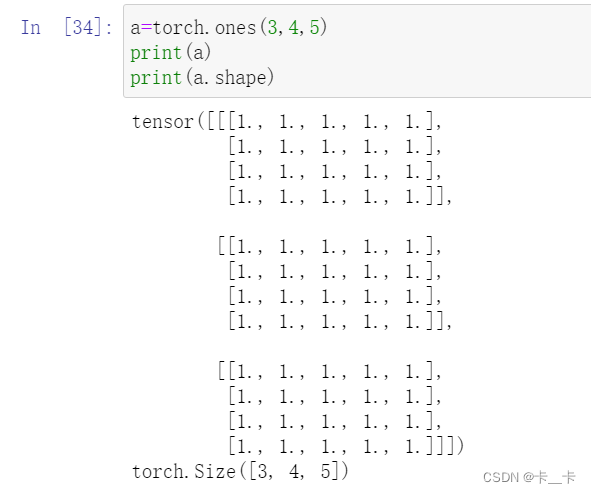
a=torch.ones(3,4,5)
print(a)
print(a.stride()) # 第3维跨越20个数字,后面正常按行列

a=torch.ones(2,3,4,5)
print(a)
print(a.stride())

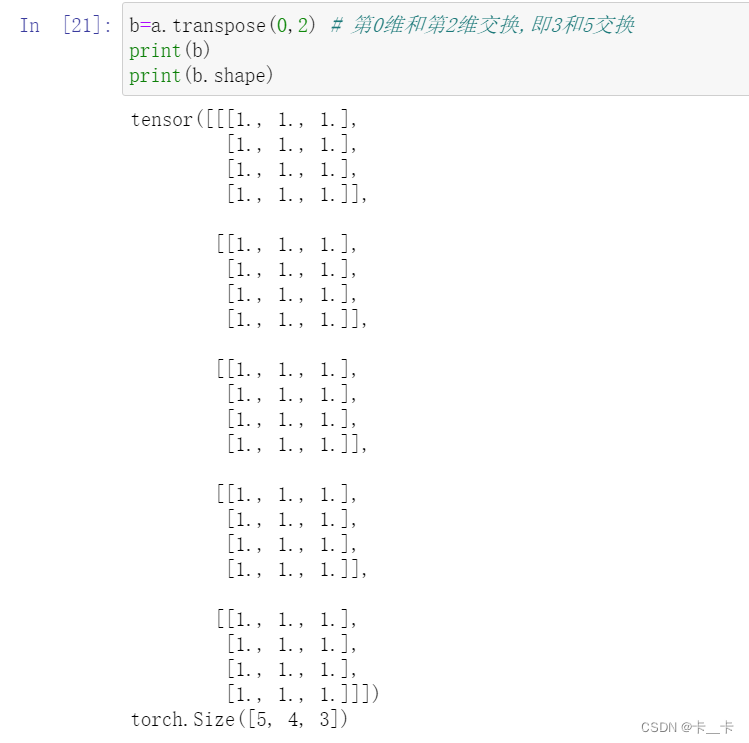
We can transpose a multidimensional array by specifying the two dimensions along which transposing (flipping shape and stride) should occur:
a=torch.ones(3,4,5)
print(a)
print(a.shape)
b=a.transpose(0,2) # 第0维和第2维交换,即3和5交换
print(b)
print(b.shape)
print(a.stride())
print(b.stride())

至于具体的转置
a=torch.tensor([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a.shape)
print(a)

我们写出每个点的坐标
1(0,0,0)
2(0,0,1)
3(0,0,2)
4(0,1,0)
5(0,1,1)
6(0,1,2)
7(1,0,0)
8(1,0,1)
9(1,0,2)
10(1,1,0)
11(1,1,1)
12(1,1,2)
然后交换第0维和第2维
得到各数的坐标应该为
1(0,0,0)
2(1,0,0)
3(2,0,0)
4(0,1,0)
5(1,1,0)
6(2,1,0)
7(0,0,1)
8(1,0,1)
9(2,0,1)
10(0,1,1)
11(1,1,1)
12(2,1,1)
即

6.Contiguous tensors
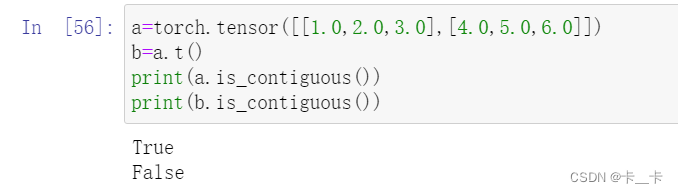
In our case, points is contiguous, while its transpose is not:
a=torch.tensor([[1.0,2.0,3.0],[4.0,5.0,6.0]])
b=a.t()
print(a.is_contiguous())
print(b.is_contiguous())
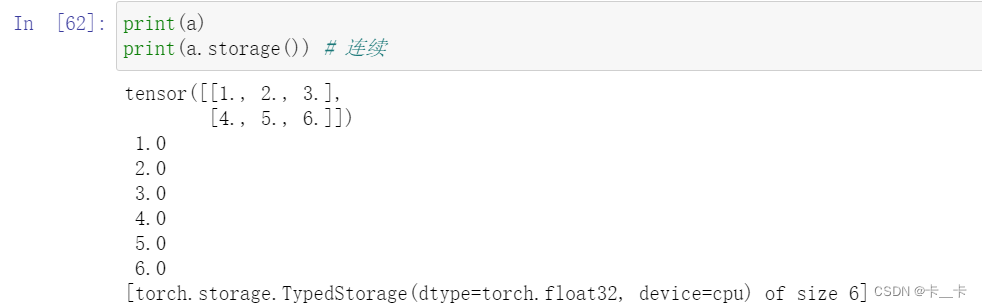

About contiguous
a=torch.tensor([[1.0,2.0,3.0],[4.0,5.0,6.0]])
b=a.t()
c=b.contiguous()

a和b的存储方式相同,而c是按序存储的
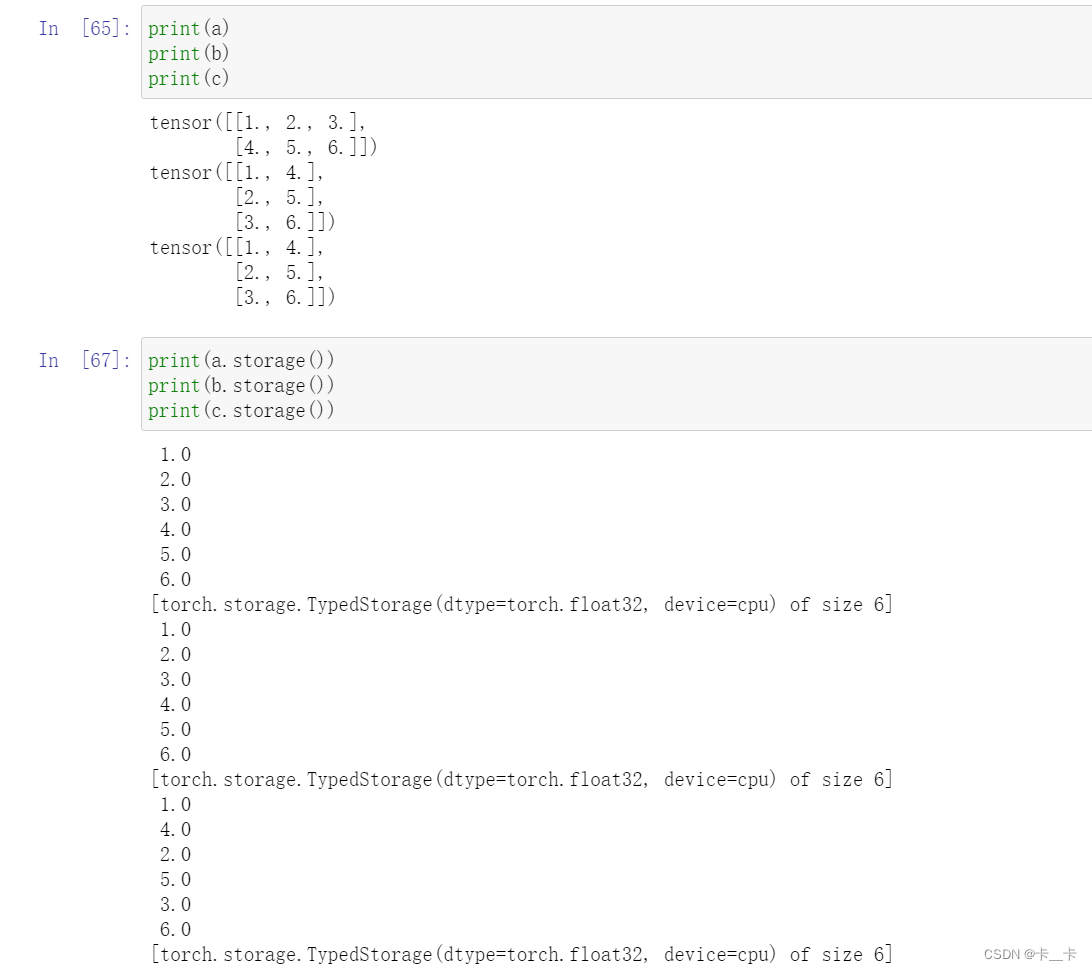
因此stride也不同
