写在前面
事实上,bed文件取交集已经又现成的工具:bedtools intersect,前面也有解读过相关参数:bedtools之intersect命令参数。
这里写的python脚本纯属造轮子,而且运行速度很慢,还需要改进。
另外进行了GhitGPT测试,挺有意思的。
实现代码
实现思路是:把两个bed的位置写入为字典,然后获取两者的交集和补集。
脚本命名:inter_bed.py
# inter_bed.py
from collections import defaultdict
import sys
bed1 = sys.argv[1]
bed2 = sys.argv[2]
output_dir = sys.argv[3]
def bed_dict(bed):
dic = defaultdict(list)
with open(bed, 'r') as f:
for line in f:
chrom, start, end = line.strip().split('\t')[:3]
dic[chrom].extend(list(range(int(start), int(end)+1))) # 【修改:2023.5.13】
return dic
def inters(b1, b2, outdir):
bedd1 = bed_dict(b1)
with open(b2, 'r') as f, open(outdir+'/inter.bed', 'w') as pf1, open(outdir+'/p1only.bed', 'w') as pf2, open(outdir+'/p2only.bed', 'w') as pf3:
for line in f:
chrom, start, end = line.strip().split('\t')[:3]
poss1 = set(bedd1[chrom])
poss2 = set(range(int(start), int(end)+1)) # 【修改:2023.5.13】
inter = poss1.intersection(poss2)
p1only = poss1.difference(poss2)
p2only = poss2.difference(poss1)
if inter:
inter_lst_split = split_num_l(inter)
inter_lst_mg = mg_str_lst(inter_lst_split)
for i in inter_lst_mg:
pf1.write('{m}\t{s}\n'.format(m=chrom, s=i))
if p1only:
p1o_lst_split = split_num_l(p1only)
p1o_lst_mg = mg_str_lst(p1o_lst_split)
for i in p1o_lst_mg:
pf2.write('{m}\t{s}\n'.format(m=chrom, s=i))
if p2only:
p2o_lst_split = split_num_l(p2only)
p2o_lst_mg = mg_str_lst(p2o_lst_split)
for i in p2o_lst_mg:
pf3.write('{m}\t{s}\n'.format(m=chrom, s=i))
def split_num_l(num_lst):
"""merge successive num, sort lst(ascending or descending): 'as' or 'des'
eg: [1, 3,4,5,6, 9,10] -> [[1], [3, 4, 5, 6], [9, 10]]
"""
num_lst_tmp = [int(n) for n in num_lst]
sort_lst = sorted(num_lst_tmp) # ascending
len_lst = len(sort_lst)
i = 0
split_lst = []
tmp_lst = [sort_lst[i]]
while True:
if i + 1 == len_lst:
break
next_n = sort_lst[i+1]
if sort_lst[i] + 1 == next_n:
tmp_lst.append(next_n)
else:
split_lst.append(tmp_lst)
tmp_lst = [next_n]
i += 1
split_lst.append(tmp_lst)
return split_lst
def mg_str_lst(mylst):
"""[[1], [3, 4, 5, 6], [9, 10]] -> ['1', '3~6', '9~10']
"""
mg_l = []
for num_l in mylst:
if len(num_l) == 1:
mg_l.append(str(num_l[0]) + '\t' + str(num_l[0]))
else:
mg_l.append(str(num_l[0]) + '\t' + str(num_l[-1]))
return mg_l
if __name__ == '__main__':
inters(bed1, bed2, output_dir)
比如有两个bed文件:
$ cat tst1.bed
1 100 2000
2 10 50
$ cat tst2.bed
1 120 2030
2 20 90
使用方法
python inter_bed.py tst1.bed tst2.bed outdir
执行后,outdir目录下有3个文件inter.bed, p1only.bed, p2only.bed分别是:bed交集,bed1独有的位点,bed2独有的位点。
$ head inter.bed p1only.bed p2only.bed
==> inter.bed <==
1 120 1999
2 20 49
==> p1only.bed <==
1 100 119
2 10 19
==> p2only.bed <==
1 2000 2029
2 50 89
其中,inter.bed文件与bedtools intersect命令得到的相同:
bedtools intersect -a tst1.bed -b tst2.bed
ChitGPT测试
问了两个问题,直接输入bedtools,默认应该是问“xxx”是什么,回答比较专业。同时也问了用bedtools取得交集,不仅给出了示例,还解释了参数(这确实比引擎搜索的结果要直接得多)。
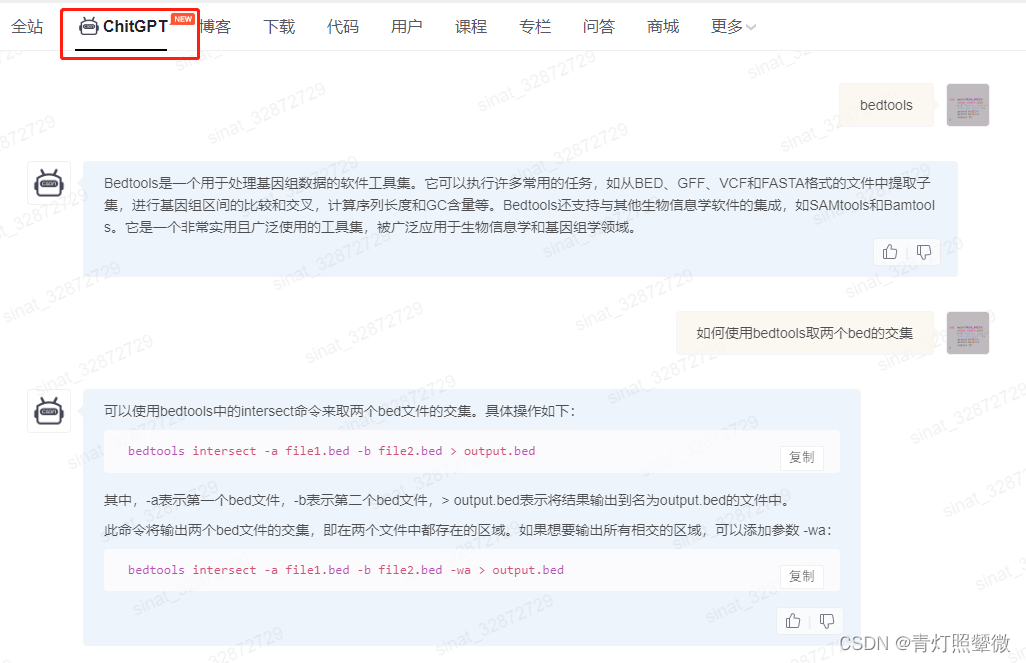
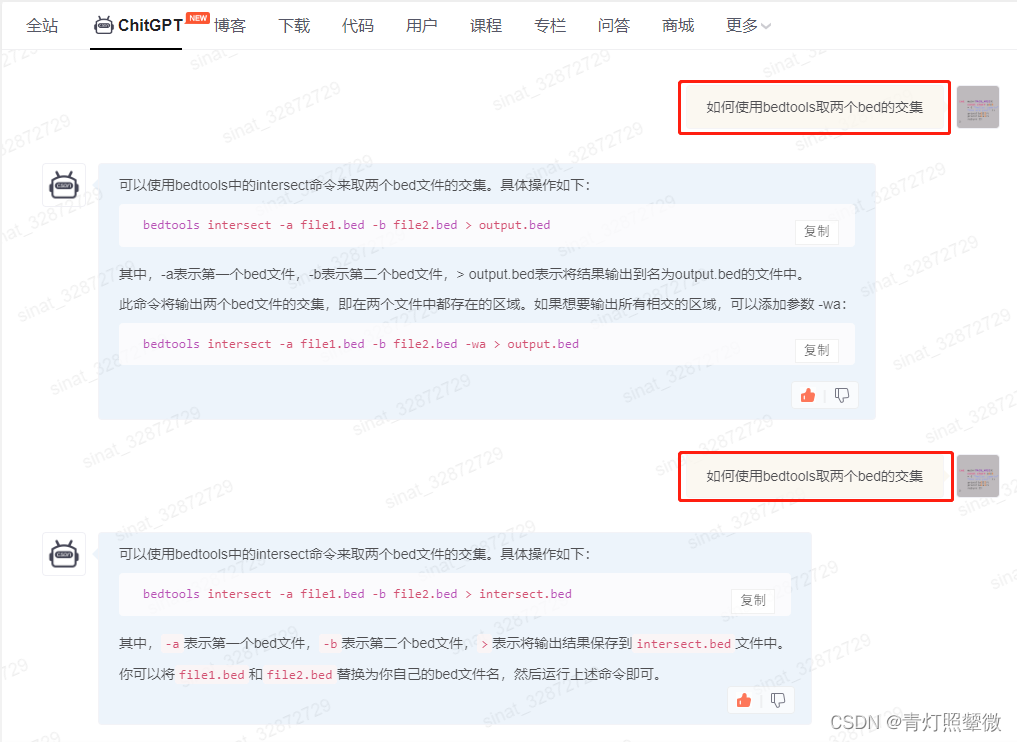
并且同样的问题,还有可能换一些描述给出:
修改日志:
【2023.5.13】感谢网友提醒脚本inter_bed.py问题。在使用range(start,end)取位置时,是取不到最后一个值end,修改为range(start, end+1),得到结果与bedtools intersect相同。增加GhitGPT的小测试。