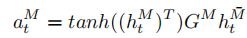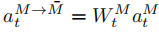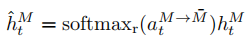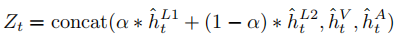2021
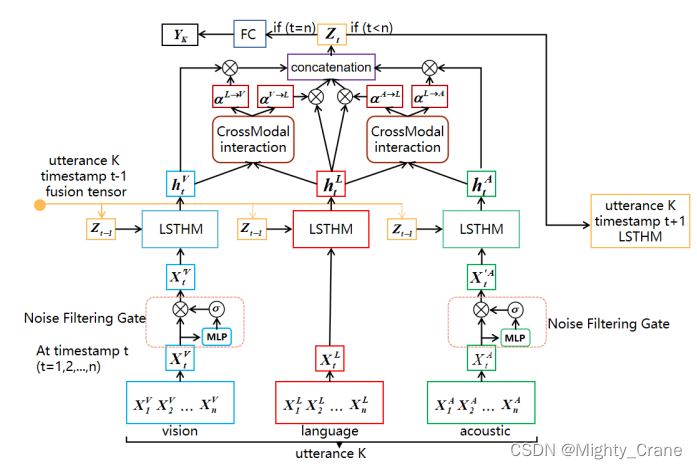
(看来是两两交互式的,v和l就像coatten一样交互出对应的两个输出,再对应的和原本的拼接,再统一拼起来。但是这样一方面v和a没有交互啊?另一方面l会有俩?)
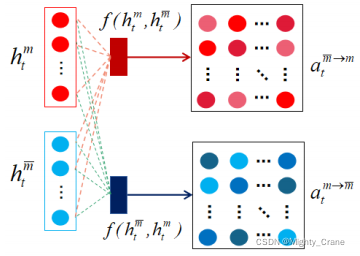
首先,我们初始化一个跨模态权矩阵 G M ∈ R d h l × d h m G^M∈R^{d^l_h×d^m_h} GM∈Rdhl×dhm来计算组合向量 a t M a^M_t atM,其中 d l h dlh dlh是语言模态隐藏状态的维数, d h m d^m_h dhm是视觉或声学模态隐藏状态的维数。计算结果见等式(5)。
以语言与视觉模态的交叉模态交互为例, a t L → V a^{L→V}_t atL→V越高,说明语言模态特征捕获的情感信息与视觉模态特征的相关性越高。同样, a t V → L a^{V→L}_t atV→L越高,说明视觉模态特征捕获的情感信息与语言模态特征的相关性越高。然后通过方程(7)得到最终的隐藏态输出ˆhMt。
(感觉对多头注意力公式的理解加深了?softmax就相当于把映射的向量再归一化成加权系数,而一开始的a也是内积出来的,只不过中间加了俩学习参数)