1概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
2详细步骤图
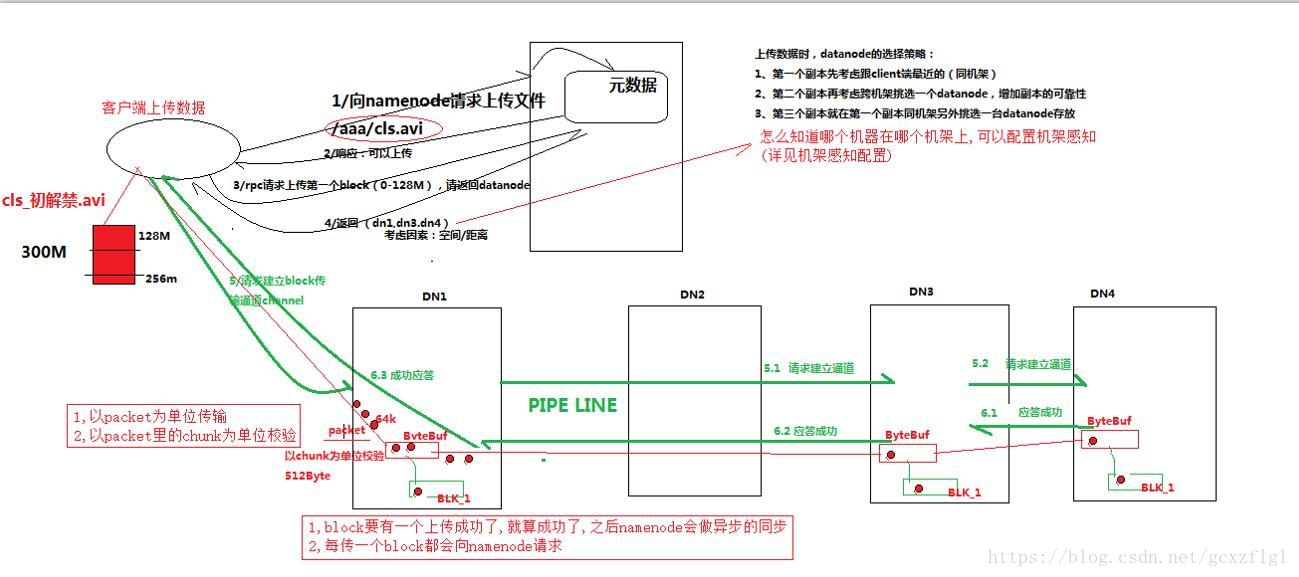
3详细步骤解析
1.跟namenode通信请求(RPC)上传文件,namenode中的元信息检查目标文件是否已经存在,父目录是否存在
2.namenode返回后是否可以上传
3.客户端再向namenode请求第一个block该传输到那些datanode上
4.namenode会返回三台datanode
第一个datanode是经过距离和存储来判断,他会先选择同机架的也就是同一路由器的,然后根据内部存储空间大小来选择存储空间充足的,返回第一个namenode
第二个datanode是通过不同机架的datanode随机挑选一个,如果都在同一个机器上,机器一旦挂掉数据全部丢失,放在不同位置可以起到一定的安全性
第三个在第一个副本同机架另外挑选一个作为第三个datanode
5.client请求3台中的一台A上传数据(本质上是一个RPC调用,简历pipeline),A收到请求后会继续调用B,然后B调用C,将每个pipeline简历完成,逐级返回客户端
6.client开始向A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位64k大小,每512k会调用一次chuck进行校验,通过后写入buffer缓存中,在写入上传datenode的本地且同时传递给B,每传一个packet会放入一个应答队列等待应答
7.当一个block传输完成之后,client再次请求namenode上传第二个block服务器,直到全部传输完毕
8.如果传输过程中失败,并且不是全部失败,有一个已经传输成功,就认为已经传输成功了,之后namenode会做异步同步