本文是FedProx的论文,值得一看。
由于本文之前有简单看过一次,这次就不细读,就只读其中比较重要的部分也就是PedProx的实现和收敛证明。
定义 1:(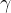 -不精确解)
-不精确解)
对于一个函数 ,其中
。我们认为
是优化目标
的一个
-不精确解,当且仅当
,其中
。注意当
越小,意味着精确度越高。
在后文的分析中都使用了这个概念来测量每一轮的计算量。
之后文章指出FedAvg的主要问题:虽然执行更多的本地epoch允许更多的本地计算和减少通信,可以大大提高通信受限网络中的总体收敛速度。更大的本地epoch可能导致每个设备朝向其本地目标的最优,可能会影响收敛,甚至导致方法发散。
比强制规定固定数量的本地epoch更自然的方法,是允许epoch根据网络的特性而变化,并通过考虑这种异构性来谨慎地合并解决方案。
框架:FedProx
强制每个设备执行统一的工作量是不现实的。我们通过允许基于设备的可用系统资源在本地执行不同数量的工作来概括FedAvg,然后聚合掉队者发送的部分解决方案。
换句话说,FedProx不是在整个训练过程中为所有设备假设统一的,而是隐式地为不同的设备和不同的迭代适应可变的
。正式地,对于第
轮训练的第
个用户,我们定义
- 不确定度,
定义 2:( -不精确解)
-不精确解)
对于一个函数 ,其中
。我们认为
是优化目标
的一个
-不精确解,当且仅当
,其中
。注意当
越小,意味着精确度越高。
意思就是,加了“正则项”后的损失函数在当前 轮权重下的梯度,乘个
这个系数后得到一个值,如果有一个权重
使得当前
轮下的梯度小于这个值,那就叫
-不精确解。类似于
,
度量了在第
轮设备
上执行多少本地计算来解本地函数。
近端项
近端项可以有效地限制本地异构数据的影响。所有的客户都再求解 ,转而求解带有近端项的
:
近端项在两个方面是有益的:
- 它通过限制局部更新以更接近初始(全局)模型来解决统计异质性问题,而无需手动设置epoch。
- 它允许安全地合并由系统异构性导致的可变数量的本地工作
算法:FedProx

首先对于每一轮 会选出
个设备参与训练,然后服务器发送上轮聚合好的
给所有的客户,然后每个用户
都找到一个
使得该权重是以下函数的
-不精确解:
然后每个客户再将这样的 发回给服务器。服务器进行聚合。
作者提到,如果我们选择特定的 ,函数
的Hessian矩阵将是正定的,这也就意味着本来是非凸的损失函数,加上近端项后很可能变成凸函数;本就是凸函数的,将变成强凸函数。
而且我们也可以注意到FedAvg是FedProx的一个特例,当且仅当:
- µ=0
- 特定选择为SGD的本地解算器
- 跨设备和更新循环的常数
后文是对收敛性的分析和实验对比,以及对系统异质性的讨论。
通篇文章提出了FedProx,这是一个解决联邦网络中系统和统计异构性的优化聚合算法。FedProx允许在设备之间本地执行不同数量的工作,依赖近端项来稳定聚合。文章对一组联邦数据集的经验评估验证了前文的理论分析,并证明FedProx框架可以显著改善现实异构网络中联邦学习的收敛。