前言:这篇博客写的很烂。
建议参考:https://cuiqingcai.com/1319.html
一、什么是beautifulsoup?
BeautifulSoupu库是一个可以将html文档转换成·一个BeautifulSoup类,然后,我们可以通过BeautifulSoup类的方法来提取出去omen需要的元素。
二、如何创建一个BeautifulSoup对象?
构建一个 BeautifulSoup 对象需要两个参数,第一个参数是将要解析的 HTML 文本字符串,第二个参数告诉 BeautifulSoup 使用哪个解析器来解析 HTML。
解析器负责把 HTML 解析成相关的对象,而 BeautifulSoup 负责操作数据(增删改查)。”html.parser” 是Python内置的解析器,”lxml” 则是一个基于c语言开发的解析器,它的执行速度更快,不过它需要额外安装。

三、四大对象种类。
BeautifuilSoup将复杂的HTML文档转换成一个复杂的文档树,每个节点都是python对象。
下面,我们来看一个示例,这是一个html文档。
<html> <head> <meta charset="utf-8"/> <title>BeautifulSoup实例</title>> <body> <h1>人生苦短,我用python</h1> <div> <p>你不努力,谁替你坚强?</p>
<p>我在未来等你</p> </div> </body> </head> </html>
BeautifulSoup会将HTML文档解析成一个DOM树,beautifulSoup会把DOM树中的节点转化为python对象。
所有对象可以归纳为4种:
Tag tag对象与XML或HTML原生文档中的Tag相同,通俗说就是标记。
BeautifulSoup BeautifulSoup 对象是指一个文档的全部内容
NavigableString 标签中的内容直接使用.string即可获取,他是一个NavigableString对象。一个NavigableString字符串对象与python中unicode字符串相同,通过unicode()方法可以将NavigableString转换成unicode字符串;
unicode_string=unicode(soup.p.string)
commet Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦
#comment注意事项 对于以下html文档 <a class="sister href="http://www.baidu.com" id="link1"><!--这是注释---></a>
print(soup.a) print(soup.a.string) print(type(soup.a.string)) 执行结果: <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a> Elsie <class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下:
另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下:
if type(soup.a.string)==bs4.element.Comment:
print soup.a.string
上面的代码中,我们首先判断了它的类型,是否为 Comment 类型,然后再进行其他操作,如打印输出。

四、标签树的遍历
按照遍历方式分为:上行遍历、平行遍历、下行遍历
下行遍历:
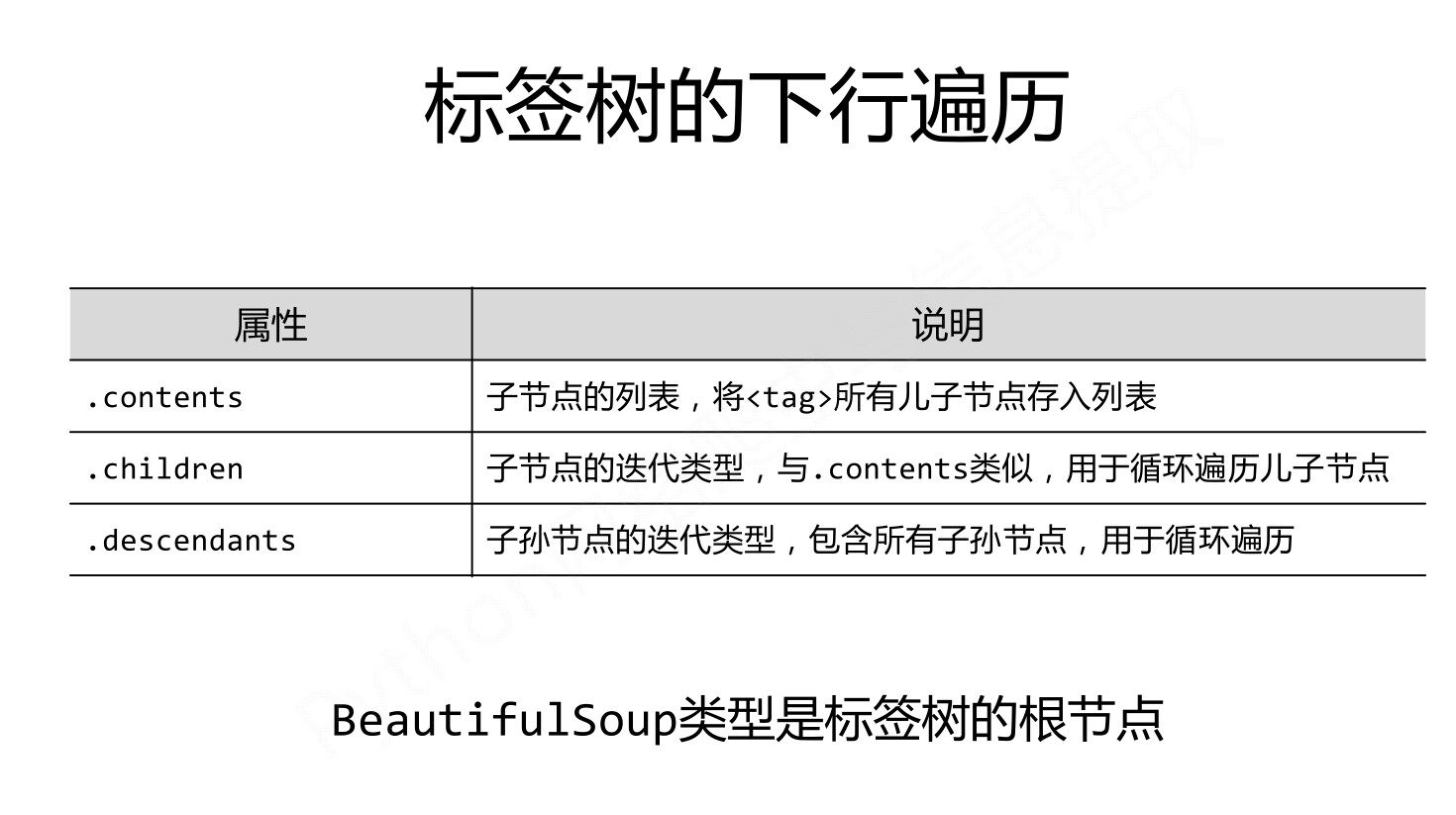
有一点需要注意,字符串没有.contents /.children/.descendants 属性,因为字符串没有子节点
from bs4 import BeautifulSoup demo="""<html> <head> <meta charset="utf-8"/> <title>BeautifulSoup实例</title>> <body> <h1>人生苦短,我用python</h1> <div> <p>你不努力,谁替你坚强?</p> <p>我在未来等你</p> </div> </body> </head> </html>""" soup=BeautifulSoup(demo,"html.parser") print(soup.body.contents)
执行结果为:


上行遍历:

from bs4 import BeautifulSoup demo="""<html> <head> <meta charset="utf-8"/> <title>BeautifulSoup实例</title>> <body> <h1>人生苦短,我用python</h1> <div> <p>你不努力,谁替你坚强?</p> <p>我在未来等你</p> </div> </body> </head> </html>""" soup=BeautifulSoup(demo,"html.parser")
for parent in soup.p.parents:
if parent is None:
print(parent)
else:
print(parent.name)
执行结果为:

平行遍历:
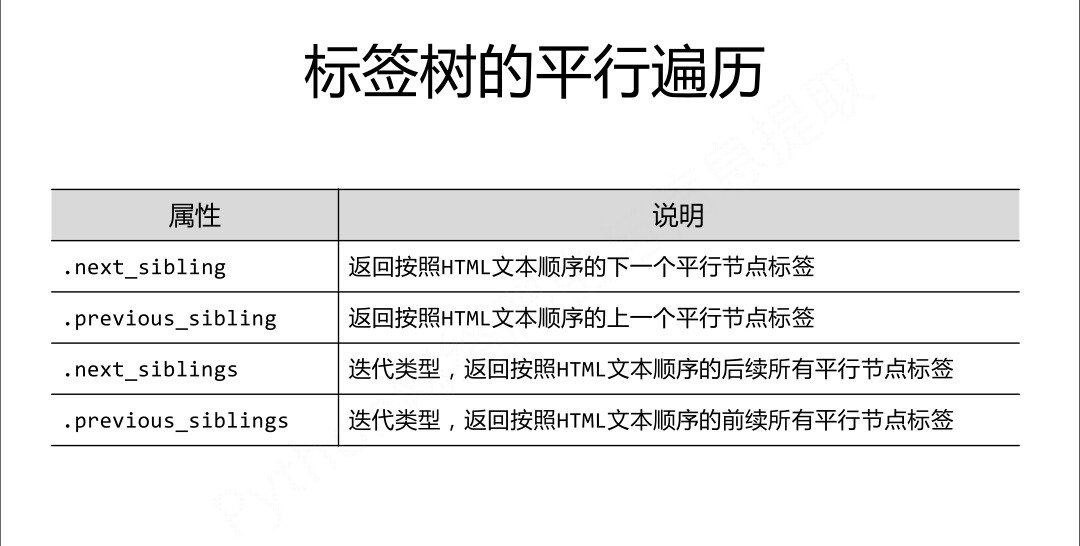
from bs4 import BeautifulSoup demo="""<html> <head> <meta charset="utf-8"/> <title>BeautifulSoup实例</title>
</head> <body> <h1>人生苦短,我用python</h1> <div>
<a href="http://www.baidu.com">百度一下</a> <p>你不努力,谁替你坚强?</p> <p>我在未来等你</p> </div> </body> </html>""" soup=BeautifulSoup(demo,"html.parser")
print(soup.body.next_sibling) print(soup.p.next_sibling.previous_sibling)
执行结果如下:
存在一个困惑,为什么第一个没有输出呢???


说实话,这篇写的不好。