目录
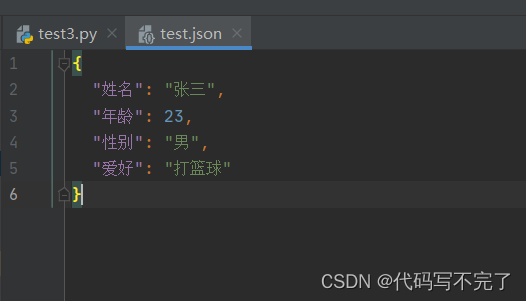
(1)使用 json.dump() 保存文件时中文会变成 Unicode,样式如下:
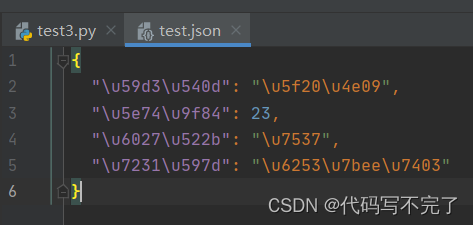
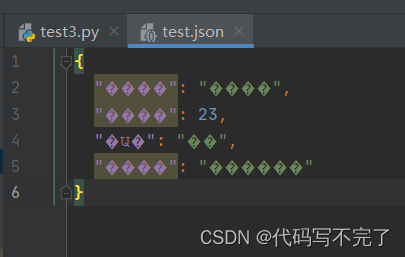
(2)使用 json.dump() 保存文件时中文会变成口字码,样式如下:
1.介绍
当使用json.dump()把python对象转换为json后存储到文件中时,文件可能会出现乱码的问题,本篇文章可以帮助您解决以下两种乱码:
主页还有一些其他的文章,可以通过以下链接快速访问:
2.样例代码
以下是用于演示的样例代码:
import json
json_data = {
"姓名": "张三",
"年龄": 23,
"性别": "男",
"爱好": "打篮球"
}
# 指定编码格式encoding='utf-8'
# with open('./data/test.json', 'w', encoding='utf-8') as f:
with open('./data/test.json', 'w') as f:
# indent参数指定缩进量
# 其中的ensure_ascii默认为True,表示会将所有输入的非ASCII字符转义。只要改成False就可以。
# json.dump(json_data, f, indent=2, ensure_ascii=False)
json.dump(json_data, f, indent=2)3.解决方法
(1)使用 json.dump() 保存文件时中文会变成 Unicode,样式如下:
json.dump()中的ensure_ascii默认为True,表示会将所有输入的非ASCII字符转义。只要改成False就可以。
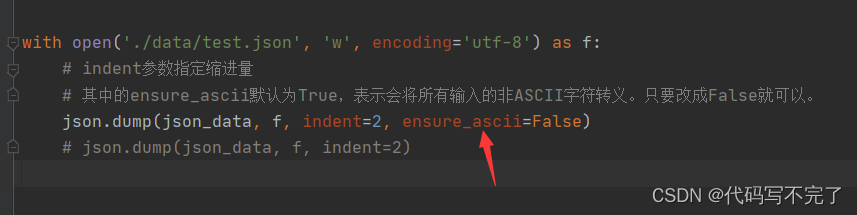
(2)使用 json.dump() 保存文件时中文会变成口字码,样式如下:
写入程序使用的编码方式和数据目标的编码方式不同造成的,申明open()函数的编码方式为'utf-8',即encoding="utf-8" 即可解决.

4.验证
重新运行程序,查看保存的json文件,发现中文不再乱码: