context-free grammars 上下文无关语法
这个用于parsing(句法分析)
能被finite automata 识别的语言叫做regular language
context-free language 包含 regualr language
例如以下language属于context-free 但是不属于 regular
G = (V, T, P ,S)
V : set of variables(non-terminals)
T : set of terminals
P : set of productions
S : start varible注意 这里的V, T, P ,S只是代表语法中的四种类型
比如下面的三行语法
S1这种在后续还需要被替代 所以属于V非终止变量
第三行的b这种不需要再被后续替换了 属于T终止变量
一共有三行 所以有三个P输出结果
S是起始位置 就是上图的S
⚠️:语法中的字母不是固定的 可以使用任何字母
Derivation Tree for aaabbb
例2
aabbbb
第一种思路可以把aabb看作一个整体 在其后面加上了些bb
aabbbb
第二种思路是把 bb看作是整个string的中央 如果a和b数量相等 就是ab 但是当b的数量大于a的时候 这时中央部分必然只包含b
context-free : 上下文无关
context-sensitive : 上下文有关
那么context-free和context-sensitive的区别 :
context-free左边只有一个变量即S aSbbbb 而context-sensitive就是aSb
aSbbbb左边即有变量varible 又有terminal
∑ = {ident,num,if,else,+,-,……}
总的来说 在词法分析的阶段 我们会把一个字符串作为输入给scanner 然后scanner会判断这是一个变量还是数字还是特殊字符还是赋值符号等等……
在计算机高级语言中 我们把变量名(identifier) 这一个类作为计算机语言表中的一个symbol 在scanner(词法分析)的过程中 无疑就是传入了一个字符串 返回一个类别 把各种类别组合在一起 形成了context-free language 然后用特定的grammar语法定义去判断这一堆类别组合是不是符合所规定的语法 如果不合规就会出现编译错误
x12 = abc + def ;
这里用类别看就是 ident = ident + ident ;即ident = Expr ;Assign → ident = Expr ;
Expr → ident + ident这两行语法就可以support上面的一行代码 但是不通用 只限于上面的代码
//我们发现上面的代码只能做加法 同时这个Expr只支持两个的ident 所以我们修改一下 使得更通用
Assign → ident = Expr ;
Expr → Expr Op ident|identOp → + |- | * | /
我们用一个实例来演示一下parsing tree (句法分析树)
⚠️:parsing tree之后会被我们转换成AST :abstract syntax tree(抽象语法树)然后AST才会被转换成IR :intermidiate representation
x = a + b * c ;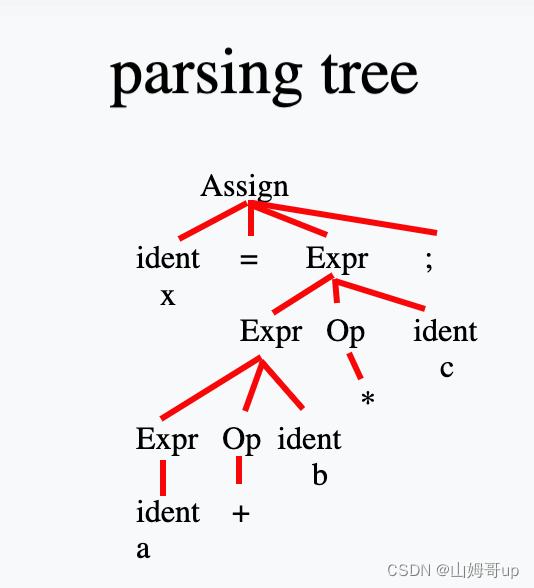
但是我们发现还存在一个问题 目前按照这个语法 会先做加法运算 再做乘法运算 这显然是不合数学规则逻辑 还需要改进语法
x = a + b * c ;
在数学中 我们称a或者b*c 为一项(term) 把b*c中的b或者c称因子(factor)
Assign → ident = Expr ;
Expr → Expr + Term | Expr - Term | TermTerm → Term * Factor | Term / Factor | Factor
Factor → ident | num

parsing tree是从底部开始向上运算 可以看到 这时候乘法*就处在了加号+的下面
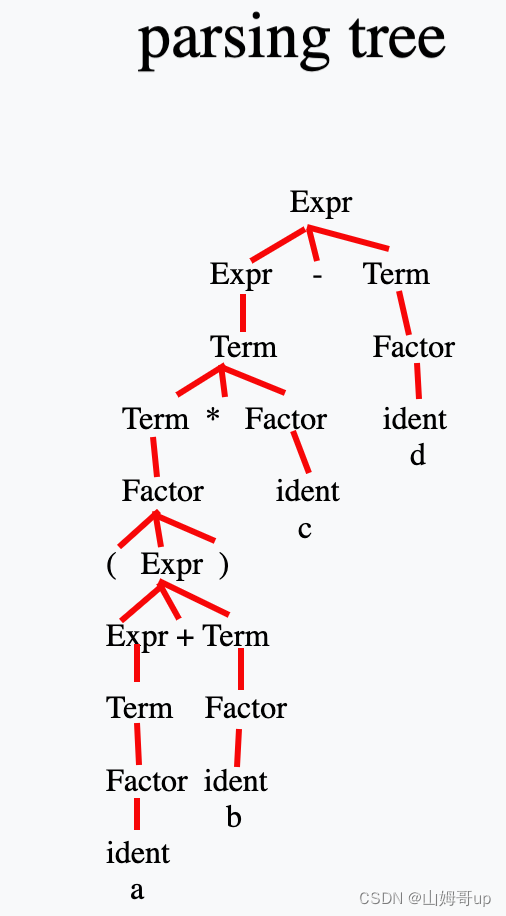
但是如果遇到 x = (a + b) * c - d; 呢?
这时在数学中(a + b)是一个factor c也是一个factor (a + b) * c是一个term
就形成了终极版本
Classic Expression Grammar :
Assign → ident = Expr ;
Expr → Expr + Term | Expr - Term | TermTerm → Term * Factor | Term / Factor | Factor
Factor → ident | num | ( Expr )