基础3文章是机器学习的核心,本文章(前向传播与反向传导)是贯穿神经网络知识的核心plus
x通过“工序f(f(f(…)))”得到y
f(x)称为单道工序; f(f(f(f(…)))) 称为多道工序
从input x到得到label y,这中间经历的过程就是f(x)。文章3里面的简单线性模型: f(x)=ax+b,可以理解为一道工序——加工了“x”。如果把“x”想象作一堆未加工的猪肉,最终要得到可以售卖的火腿肠,那么“a*x”就是把肉揉成条状,“+b”就是再加上包装。
总之,f(x)就是处理x的工序。
神经网络觉得仅仅用一道工序的话太过简单,希望通过“多道工序”将x映射到y,这就是复合函数——f(f(f(f(......))))。
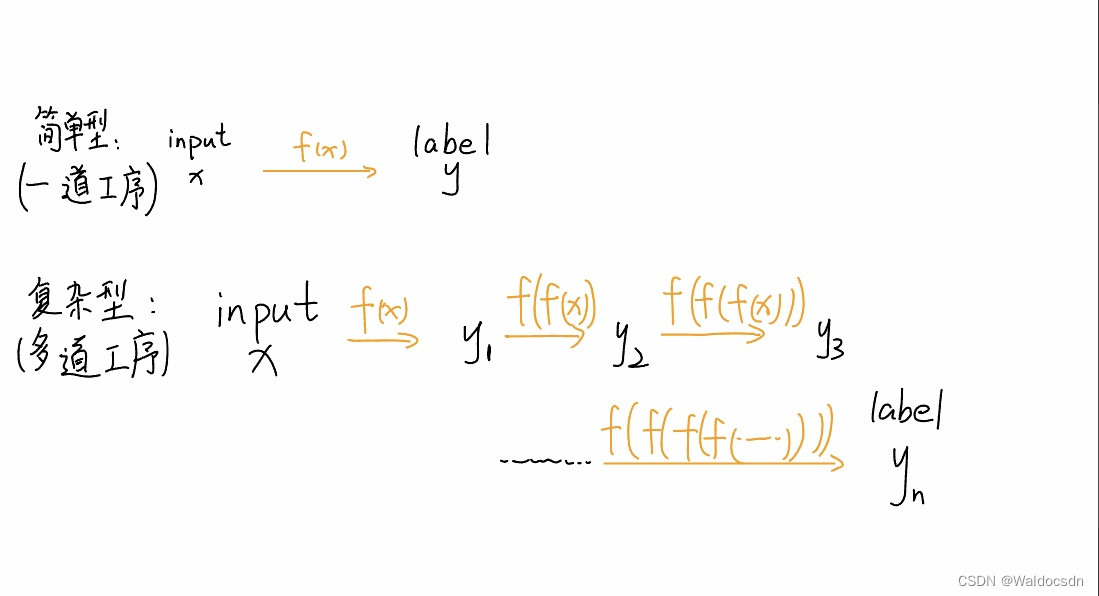
复习一下“单道工序”处理过程(梯度下降)
梯度下降的目的: 缩小误差(minimize loss)、寻求最优参数
现有模型y=ax+b,现要通过“已有数据x、y”(数据是训练集、真实值)来得到参数a、b(操作过程就是梯度下降)。

计算loss极小值时,得到的w’、b’ 就可以作为我们要的模型,此时模型会接近于红色线。
详情见下面视频: 清晰版链接:https://pan.baidu.com/s/1ySSN08D9qFABdLoeSaBGaQ
提取码:131n
GradientDescent简述用于NLP:CV基础文章3
神经网络基础结构
- 神经网络的基础结构: 线性映射、激活层、隐藏层。
- “需要多道工序f(f(f(…)))”——就是隐藏层。
神经网络就是不断重复单道机器学习工序(把上一轮的输出作为下一轮的输入),而当神经网络的层数足够深的时候,就变成了“深度学习”。

上面左右两张图是在论文、帖子中常见的神经网络,是通用结构。
隐藏层就是除开头尾的多道工序。

线性映射: 把离散的数据点拟合成线性模型就叫线性映射。线性映射对应于计算处理过程。
如下图,是一个个离散的点,当我们把这些点拟合成线性模型时,这些离散的点就线性化了,此时不用管得到的模型有多差。

在设置神经网络的“层”的时候,通常需要设置一个激活层。激活层是在计算处理完成后的一道工序,需要使用激活函数,如: Relu函数。
根据经验举个例子: 有时候计算出一个矩阵时,其中元素会有负值,而我们不需要这些值。此时使用Relu函数,把负值变成0,正值设置为y=x。

前向传播
前向传播就可以理解为神经网络从输入到输出(x—>y),也就是复合函数f ( f ( f (…) ) ) 从内到外。

反向求导
经过前向传播得到的模型肯定不太好,需要不断通过梯度下降修正模型,梯度下降的根本目的就是缩小误差(minimize loss)、寻找最优参数。“梯度下降”有很多方法,其中最简单的就是“反向求导”。

注 下面视频清晰版:链接: https://pan.baidu.com/s/1l6fD4up3OoW8amZCLxfemQ?pwd=vdkh 提取码: vdkh
反向求导概述用于CVNLP基础文章4