机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
TF-idf 权
在大的文本合集里,一些词出现的频率很高(例如英文里的the, a, is)但包含的实际文本内容的有价值的信息却很少。如果我们把计数的数据直接提供给一个分类器,那些高频词条会影响罕见但更有意义的词条。为了重新加权计数特征为适合分类器使用的浮点值,现在普遍采用tf-idf变换。
tf的意思是term-frequency, 而tf-idf的意思是term-frequency times inverse document-frequency, 公式为:
-
这里,使用TfidfTransformer的默认设置,TfidfTransformer(norm='l2', use_idf=True, smooth_idf=True, sublinear_tf=False)
表示词条频数,即,一个词条在一个给定文档里出现的次数。
表示文档总数, 表示包含词条 的文档数,结果tf-idf向量经欧拉范数归一化
这个词条加权方案最初来自信息检索领域,后引入到文档分类、聚类问题,也得到好的效果。
下面我们进一步解释和举例说明tf-idf怎样精确地计算,以及使用TfidfTransformer, TfidfVectorizer计算tf-idf与标准定义的区别。idf的标准定义为
在TfidfTransformer, TfidfVectorizer里,通过设置参数smooth_idf=False, 1被加到idf上,而不是标准定义的分母项。
然后,归一化由TfidfTransformer类执行:
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer(smooth_idf=False)
transformer 
让我们用下面的counts举一个例子。第一项(列)出现频率100%, 所以意义不大,后两个向量出现频率低于50%, 故很可能是有代表性的文档内容。
counts = [[3, 0, 1],
[2, 0, 0],
[3, 0, 0],
[4, 0, 0],
[3, 2, 0],
[3, 0, 2]]
tfidf = transformer.fit_transform(counts)
tfidf
tfidf.toarray() 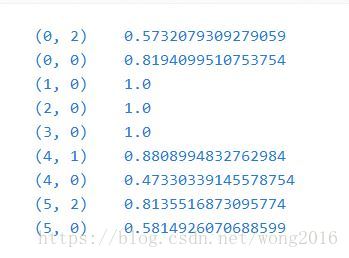

每一行被归一化为1范数。例如,我们可以按如下公式计算第一项在第一个文档里的tf-idf:
-
现在,如果我们重复计算该文档剩余两项,则得到
-
-
这样,原始tf-idf向量为[3, 0, 2.0986], 然后,按欧式(L2)范数,得到文档1的tf-idf:
进一步,缺省参数smooth_idf=True对分子分母分别加1,好像存在一个外部文档,包含每一个词条,这样避免了分母是0的情况。
使用这个修正,文档1的第三项的tf-idf修正为:
-
这样,经L2归一化的tf-idf修正为
transformer = TfidfTransformer()
transformer.fit_transform(counts).toarray()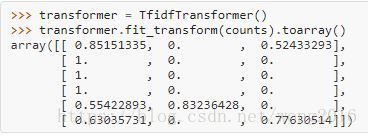
经fit方法计算的每个特征的权保存在一个模型属性里。
transformer.idf_
由于tf-idf经常用于文本特征数量化,也有另一个类TfidfVectorizer结合CountVectorizer, TfidfTransformer所有的选项在一个模型里:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
vectorizer = TfidfVectorizer()
vectorizer.fit_transform(corpus)
阅读更多精彩内容,请关注微信公众号:统计学习与大数据