目录
六、 如何理解闭包,为什么有这种特性?为什么需要闭包?闭包的缺点?
一、 实现深拷贝和浅拷贝
1.深拷贝
function checkType(any) {
return Object.prototype.toString.call(any).slice(8, -1)
}
//判断拷贝的要进行深拷贝的是数组还是对象,是数组的话进行数组拷贝,对象的话进行对象拷贝
//如果获得的数据是可遍历的,就拿到对应的value,实现深拷贝
function clone(any){
if(checkType(any) === 'Object') { // 拷贝对象
let o = {};
//遍历
for(let key in any) {
o[key] = clone(any[key])
}
return o;
} else if(checkType(any) === 'Array') { // 拷贝数组
var arr = []
//遍历
for(let i = 0,leng = any.length;i<leng;i++) {
arr[i] = clone(any[i])
}
return arr;
} else if(checkType(any) === 'Function') { // 拷贝函数
return new Function('return '+any.toString()).call(this)
} else if(checkType(any) === 'Date') { // 拷贝日期
return new Date(any.valueOf())
} else if(checkType(any) === 'RegExp') { // 拷贝正则
return new RegExp(any)
} else if(checkType(any) === 'Map') { // 拷贝Map 集合
let m = new Map()
any.forEach((v,k)=>{
m.set(k, clone(v))
})
return m
} else if(checkType(any) === 'Set') { // 拷贝Set 集合
let s = new Set()
for(let val of any.values()) {
s.add(clone(val))
}
return s
}
return any;
}2.浅拷贝
function shallowCopy(src) {
var dst = {};
for (var prop in src) {
//只要还没读完就继续读,读到的话就直接把属性名返回就行,没有进入深层
//hasOwnProperty:是用来判断一个对象是否有你给出的名称的属性或对象。有则返回true,没有返回false,不过需要注意的是,此方法无法检查该对象的原型链中是否具有该属性,该属性必须是对象本身的一个成员。
if (src.hasOwnProperty(prop)) {
dst[prop] = src[prop];
}
}
return dst;
}二、 讲一下event loop
事件循环是js引擎执行js的机制,用来实现js的异步特性。事件循环的过程为:当执行栈空的时候,就会从任务队列中,取任务来执行。共分3步:
-
取一个宏任务来执行。执行完毕后,下一步。
-
取一个微任务来执行,执行完毕后,再取一个微任务来执行。直到微任务队列为空,执行下一步。
-
更新UI渲染。
1.EventLoop概念
Event Loop即事件循环,是指浏览器或Node的一种解决javaScript单线程运行时不会阻塞的一种机制,也就是我们经常使用异步的原理。
因为JavaScript就是单线程,也就是说,同一个时间只能做一件事。单线程就意味着,所有任务需要排队,前一个任务结束,才会执行后一个任务。如果前一个任务耗时很长,后一个任务就不得不一直等着。
所有任务可以分成两种,一种是同步任务(synchronous),另一种是异步任务(asynchronous)
2.同步任务和异步任务
同步任务:函数返回—>拿到预期结果 异步任务:函数返回—>拿不到预期结果,还要通过一定的手段获得结果 简单点说 : 同步任务:会立即执行的任务 异步任务:不会立即执行的任务(异步任务又分为宏任务与微任务)
在异步任务中,任务被分为两种,一种宏任务(MacroTask)也叫Task,一种叫微任务(MicroTask)。
宏任务:由宿主对象发起的任务(setTimeout)。宏任务(定时器)包括 script, setTimeout,setInterval,setImmediate(Node.js),I/O,postMessage, MessageChannel,UI rendering(即I/O、定时器、事件绑定、ajax)
微任务:由js引擎发起的任务(promise)。微任务包括 process.nextTick(Node.js),promise.then(),promise.catch(),MutationObserver。(即Promise的then、catch、finally和process的nextTick)
注意:Promise的then等方法是微任务,而Promise中的代码是同步任务,并且,process的nextTick的执行顺序优先于Promise的then等方法,因为process.nextTick是直接告诉浏览器说要尽快执行,而不是放入队列
3.同步任务
当有多个同步任务时,这些同步任务会依次入栈出栈,如下图
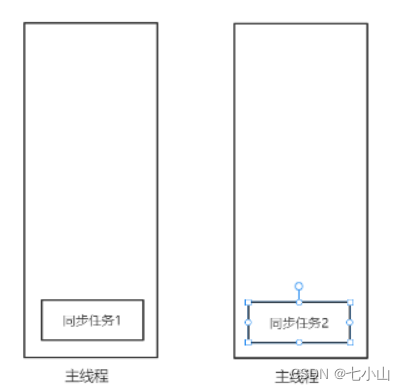
同步任务1先入栈,执行完之后,出栈,接着同步任务2入栈,依此类推
4.异步任务
异步任务会在同步任务执行之后再去执行,那么如果异步任务代码在同步任务代码之前呢?在js机制里,存在一个队列,叫做任务队列,专门用来存放异步任务。也就是说,当异步任务出现的时候,会先将异步任务存放在任务队列中,当执行完所有的同步任务之后,再去调用任务队列中的异步任务
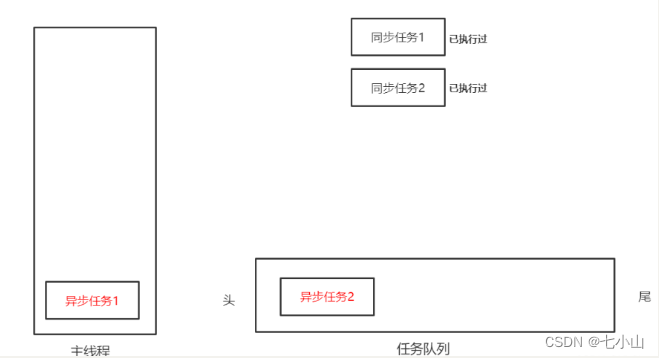
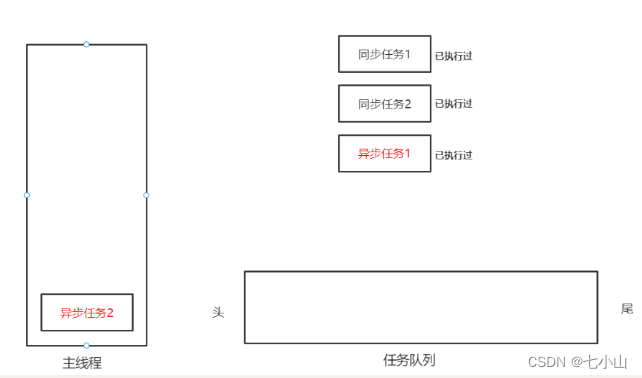
例如下图,现在存在两个同步任务,两个异步任务
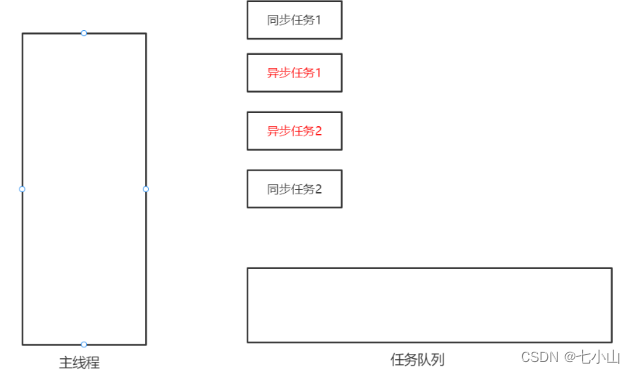
js会先将同步任务1提至主线程,然后发现异步任务1和2,则将异步任务1和2依次放入任务队列
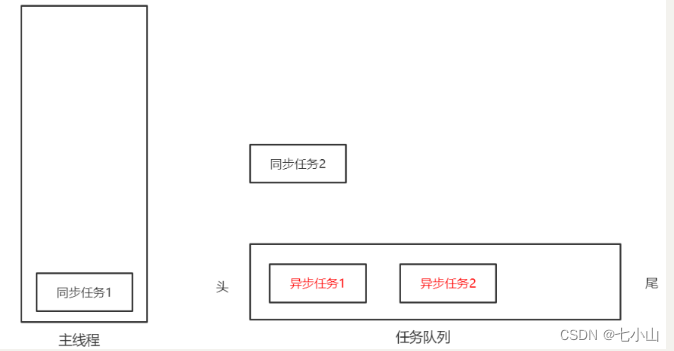
然后同步任务1执行完之后出栈,又将同步任务2入栈执行
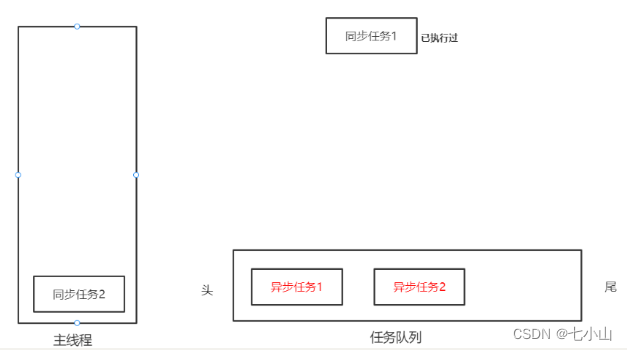
当同步任务2执行完之后,再从任务队列中提取异步任务执行
5.总结
js中,微任务总是先于宏任务执行,也就是说,这三种任务的执行顺序是:同步任务>微任务>宏任务
6.案例
<script>
console.log(1);
setTimeout(function(){
console.log(2)
},0)
new Promise((resolve,reject)=>{
console.log(3)
resolve()
console.log(4)
}).then(()=>{
console.log(5)
})
console.log(6)
</script>

三、 js如何判断一个变量是数组
判断变量的类型是最经常使用的方法,但是判断的方式有很多
1.typeof
var ary = [1,2,3,4];
console.log(typeof ary); // 输出‘object’很明显,typeof只能检测基本数据类型,并不能检测出来是否为数组。
2.instanceof
var ary = [1,2,3,4];
console.log(ary instanceof Array); //输出true看起来挺好使的,实际上也确实挺好使的,但是要求变量必须在当前页面声明。
3.原型链
var ary = [1,2,3,4];
console.log(ary.__proto__.constructor==Array); //输出true
console.log(ary.constructor==Array) //输出true 两种方法都一样,但是在IE中“proto”没有定义。这种方法也存在和“instanceof”一样的问题,必须先声明变量。
4.isArray
let a = [2,543,32];
console.log(Array.isArray(a));//true必须先声明变量
5.完美方法
var arr = [1,2,3,4];
console.log(Object.prototype.toString.call(arr)) //输出"[object Array]"为了使用简便,我们可以封装成一个函数。
var ary = [1,2,3,4];
function isArray(o){
return Object.prototype.toString.call(o)=='[object Array]';
}
console.log(isArray(ary));当然,这种方法不仅仅可以用来判断是否为数组,其他的也同样适用。
console.log(Object.prototype.toString.call(123)) //[object Number]
console.log(Object.prototype.toString.call('123')) //[object String]
console.log(Object.prototype.toString.call(undefined)) //[object Undefined]
console.log(Object.prototype.toString.call(true)) //[object Boolean]
console.log(Object.prototype.toString.call({})) //[object Object]
console.log(Object.prototype.toString.call([])) //[object Array]
console.log(Object.prototype.toString.call(function(){})) //[object Function]四、 JavaScript数据类型
JavaScript共有八种数据类型,分别是 Undefined、Null、Boolean、Number、String、Object、Symbol、BigInt
其中 Symbol 和 BigInt 是ES6 中新增的数据类型:
Symbol 代表创建后独一无二且不可变的数据类型,它主要是为了解决可能出现的全局变量冲突的问题。 BigInt 是一种数字类型的数据,它可以表示任意精度格式的整数,使用 BigInt 可以安全地存储和操作大整数,即使这个数已经超出了 Number 能够表示的安全整数范围。 这些数据可以分为原始数据类型和引用数据类型:
栈:原始数据类型(Undefined、Null、Boolean、Number、String) 堆:引用数据类型(对象、数组和函数)
五、 柯里化
1. 什么是函数柯里化
函数柯里化就是我们给一个函数传入一部分参数,此时就会返回一个函数来接收剩余的参数。 柯里化是一种函数的转换。是指将一个函数从可调用的 f(a, b, c) 转换为 f(a)(b)(c)
2. 简单的柯里化的实现
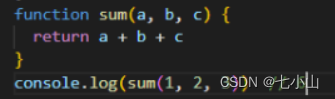
没有柯里化的实现
将其转化为柯里化的案例
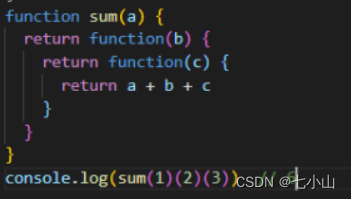
上述代码可简写为

3.函数柯里化的好处
我们希望处理函数时,希望函数功能尽可能单一。如下面代码所示,我们希望第一个参数+2,第二个参数*2,第三个参数** 2,最后再相加,此时我们可以使用函数的柯里化
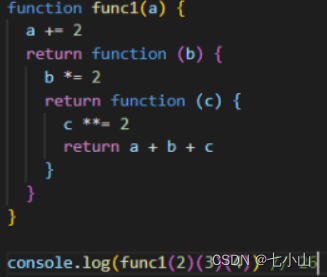
function makeAdder(count) {
return function(num) {
return count + num
}
}
// 在之后使用返回的函数时,我们不需要再继续传入count 了
var adder5 = makeAdder(5)
adder5(10)
adder5(14)
adder5(1100)
adder5(555)4.柯里化的优点
柯里化是使函数变得更具体些,即作用范围更小
5.传入函数的柯里化执行
function currying(fn, ...rest) {
return function(...args) {
//...rest=3,4
//...args=1,2
return fn(...rest, ...args);
}
}
function sum(a, b, c, d) {
console.log(a + b + c + d)
}
//传入sum,即currying(fn,...rest)解析成sum,1,2
//add是接收currying返回的函数
const add = currying(sum, 1, 2);
//add(3,4)即function(3,4),这个function是sum(3,4),所以add(3,4)就会执行最后那个sum四个数相加的函数
add(3, 4);
// 执行结果
10
function add(a, b, c, d) {
console.log(a + b + c + d);
}
const curriedAdd = currying(add);
//接收curry()()()()
curriedAdd(1)(2)(3)(4); // 10
curriedAdd(1, 2, 3)(4); // 10
curriedAdd(1, 2, 3, 4); // 10
function currying(fn) {
//一开始,curriedAdd传入一个参数1,len=add参数长度4
const len = fn.length;
//_args=[]
let _args = [];
const curry = () => {
//...args=1
return function (...args) {
//_args.length=0,args.length=1,小于len=4
// 如果参数攒够了就执行
if (_args.length + args.length >= len) {
const result = fn(..._args, ...args);
// 执行完重置_args
_args = [];
return result;
}
// 参数不够就继续攒
else {
//_args=[..._args,...args]=[1]
_args = [..._args, ...args];
//curriedAdd(1)返回值是一个curry函数,以此类推
return curry();
}
}
}
return curry();
}六、 如何理解闭包,为什么有这种特性?为什么需要闭包?闭包的缺点?
(1)什么是闭包?
闭包就是能够读取其他函数内部变量的函数。
由于在javascript中,只有函数内部的子函数才能读取局部变量,所以说,闭包可以简单理解成“定义在一个函数内部的函数“。
所以,在本质上,闭包是将函数内部和函数外部连接起来的桥梁。
(2)如何生成闭包?
函数嵌套 + 内部函数被引用。
function outer() {
var a = 1;
function inner() {
console.log(a);
}
return inner;
}
//这里的闭包就是返回的inner函数
var b = outer();(3)闭包作用?
-
可以让内部的函数访问到外部函数的变量,避免变量在全局作用域中存在被修改的风险
-
可以读取函数内部的变量
-
让这些变量的值始终保持在内存中,不会在f1调用后被自动清除
(4)使用闭包的注意事项?
不用的时候解除引用,避免不必要的内存占用。
为什么有闭包的这种特性:如果形成闭包,外部函数执行完后,其中的局部变量可能被内部函数使用,所以不能销毁,因此内部函数能一致访问到这些局部变量,直到引用解除。
(5)闭包的优点?
-
隐藏变量,避免放在全局有被篡改的风险。
-
方便调用上下文的局部变量
(6)闭包的缺点?
-
使用时候不注意的话,容易产生内存泄漏。
-
由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除