概述
国好事达保险公司创建于1931年的美国好事达保险公司(Allstate)是美国第二大从事个人险种业务的财险和意外险保险公司, 并跻身于全美最大的15家人寿保险公司的行列。公司的总部设在芝加哥地区。
2018年12月,世界品牌实验室发布《2018世界品牌500强》榜单,美国好事达保险公司排名第486。
好事达 Allstate 致力于改善其理赔服务并发布了一个科研数据集,该数据集将有助于构建可预测理赔严重程度的模型。本案例研究旨在开发用于预测特定保险索赔成本(严重程度)的自动化模型。

提供给好事达的数据集包含发生在家庭中的事故数据(每一行数据对应一个特定的家庭),目标变量为索赔成本,这是度量的数字。
由于提供给好事达的数据是关于个人信息的,Allstate 在高度匿名化数据(更改特征名称)方面做得很好,并且该数据集的这一方面使得很难理解特征。数据集包含 Allstate 客户的索赔记录。整个数据集是高度匿名的。
下图是数据集截图
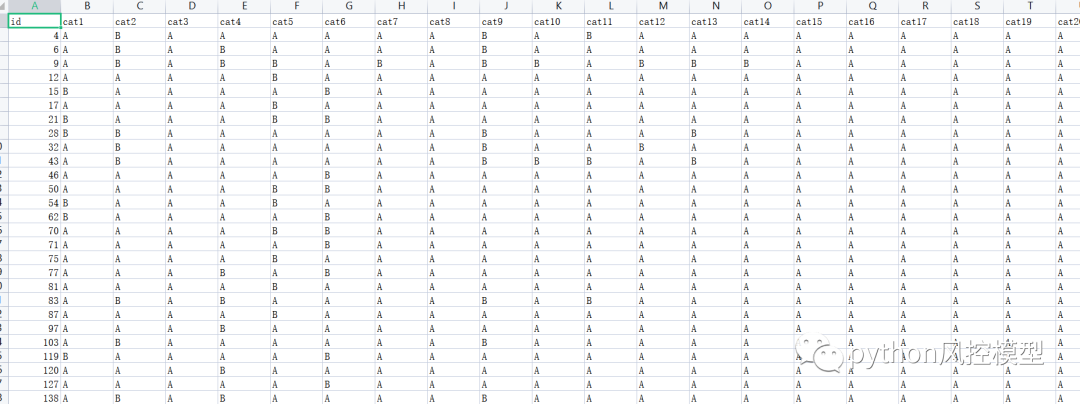
问题陈述:
训练数据集包含分类和连续特征。目标变量是一个损失(索赔严重程度),它是数字类型的。由于目标变量是数字和损失值,我们可以将此问题视为回归问题。这也是一个有监督的机器学习问题,因为我们有训练数据的目标值。在我看来,这样做将提高整体客户服务,这将有利于公司和索赔人,并有助于保险公司。
我们的任务是预测新家庭的索赔将或可能有多严重,根据给定的特征预测未来的损失。
指标
对于回归模型,我们要使用的指标——平均绝对误差 (MAE)
这是一个简单直接的明显指标,将预测值与实际值进行比较。MAE 不会因为不识别异常值而对我们的模式产生太大影响。MAE 很容易解释,因为它简单易计算。
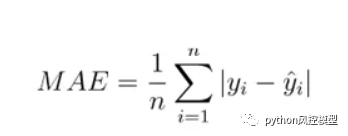
第1部分:
数据分析与可视化:
1.1 数据集概览:
·训练数据:188318行和132个特征/列以及目标变量。
· 测试数据:129446 行和 132 个特征/列,其中目标特征不存在。
· 除target feature和id feature外,共有130个distinct features。这些特征包含分类和数值数据类型。
· 在 130 个特征中,116 个是分类特征,14 个是数值特征。我们注意到火车数据集中没有缺失值。这表明 Allstate 提供了高度用户友好的预置数据。
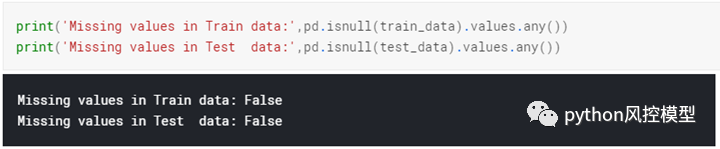
1.2 缺失值
-
由于训练和测试数据中没有缺失值,我们可以说该数据已经过预处理。如果数据中存在缺失值,我们需要考虑替代方案,例如删除这些行或用平均值填充这些值以处理缺失数据。
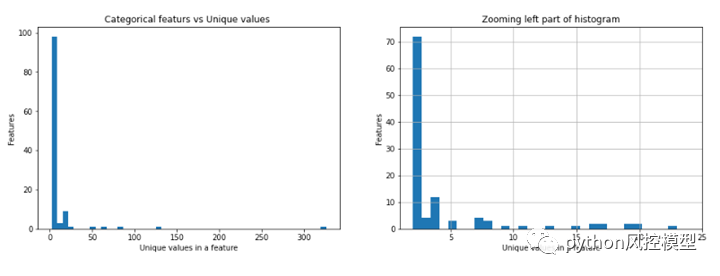
fig, (ax1, ax2) = plt.subplots(1,2)fig.set_size_inches(16,5)ax1.hist(unique_categories.unique_values, bins=50)ax1.set_title('Categorical featurs vs Unique values ')ax1.set_xlabel('Unique values in a feature')ax1.set_ylabel('Features')values = unique_categories[unique_categories.unique_values <= 25].unique_valuesax2.set_xlim(1,25)ax2.hist(values, bins=30)ax2.set_title('Zooming left part of histogram')ax2.set_xlabel('Unique values in a feature')ax2.set_ylabel('Features')ax2.grid(True)
-
从上图中,我们注意到几乎有 100 个特征,每个特征的唯一值少于 10 个。
-
有一个特征包含超过 300 个唯一值,我们在上面的代码中也看到了这一点。
-
尝试绘制缩放后的图像以查看这些分布是如何发生的,我们可以看到只有极少数特征具有更多的唯一值。
1.3 连续特征数据分析部分:
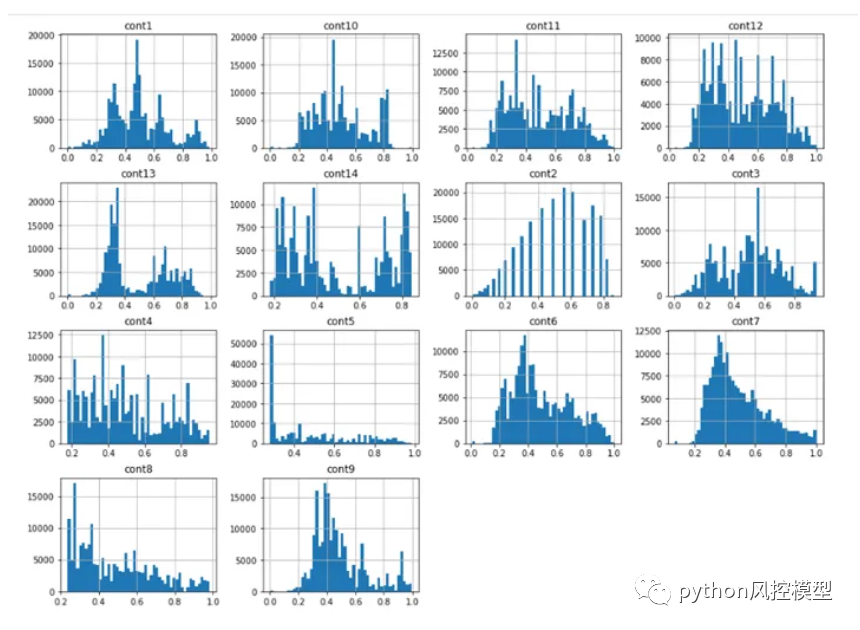
-
我们注意到每个连续特征的分布变化很大。每个图中都有很多尖峰。所以在 PDF 中不存在这些连续特征的一致性。
-
Cont2 特征实际上看起来像正态分布,但我们无法谈论该特征是什么,因为它们是匿名的。
1.4 连续特征的复选框图
fig, (ax1, ax2) = plt.subplots(1,2)fig.set_size_inches(14,5)ax1.boxplot(train_data['loss'])ax1.set_ylabel('loss')ax1.set_title('Box plot of loss feature')#values = uniq_values_in_categories[uniq_values_in_categories.unique_values <= 25].unique_valuesax2.set_ylim(1,10000)ax2.boxplot(train_data['loss'])ax2.set_ylabel('loss')ax2.set_title('Zoomed version of loss feature')
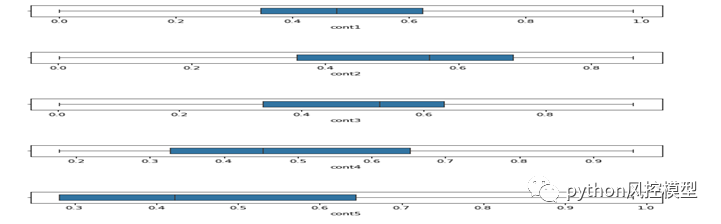

-
我们可以看到大多数连续特征的平均值都在 0.5 左右。所有值都在 0 和 1 之间。这表明数据已经标准化。
-
我们注意到所有连续特征的平均值都在 0.5 左右,这非常好,我们可以说 Allstate 做了预处理然后给出了数据。
-
所有连续特征都在 [0,1] 范围内,这非常好
1.5 检查连续特征之间的相关性:
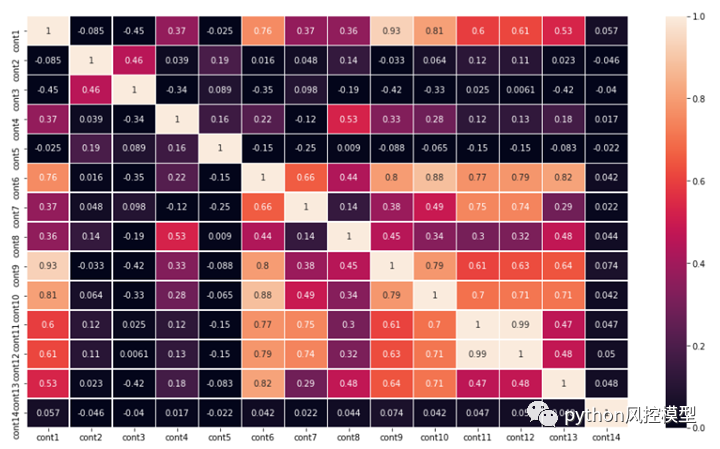
-
有几个高度相关的特征。例如,参见 cont 14 和 cont 12——它们的相关值为 0.99,这几乎是它可以获得的最大值。
-
因此,我们可以删除一些高度相关的特征并训练模型,看看它是否会出现任何性能下降。
-
另一方面,由于我们不知道任何关于数据或特征名称的具体信息,我们不能盲目地删除特征。它也可能导致更糟糕的模型。
-
所以处理这些类型的数据有点困难。我们实际上需要在有和没有模型下降的情况下训练模型,并且必须决定什么是正确的做法。
-
Cont11 和 Cont12 非常相关。我正在考虑至少放弃其中一个功能。
1.6 分析目标变量:
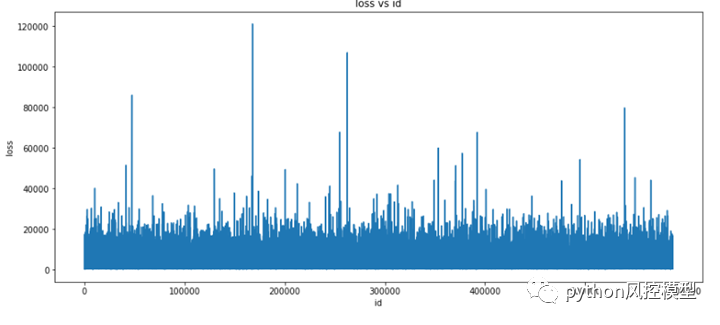
1.7 计算偏度,看看我们如何减少偏度:
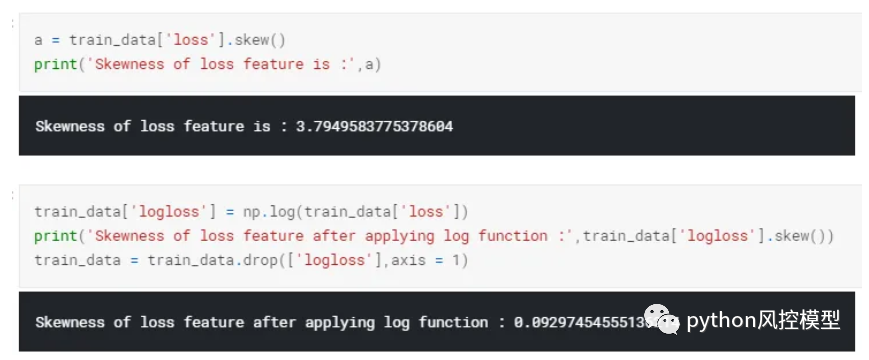
-
我们可以看到目标变量存在很大的偏度,这将导致错误的预测。
-
我们对该目标变量应用了对数转换,并注意到偏度下降了很多。
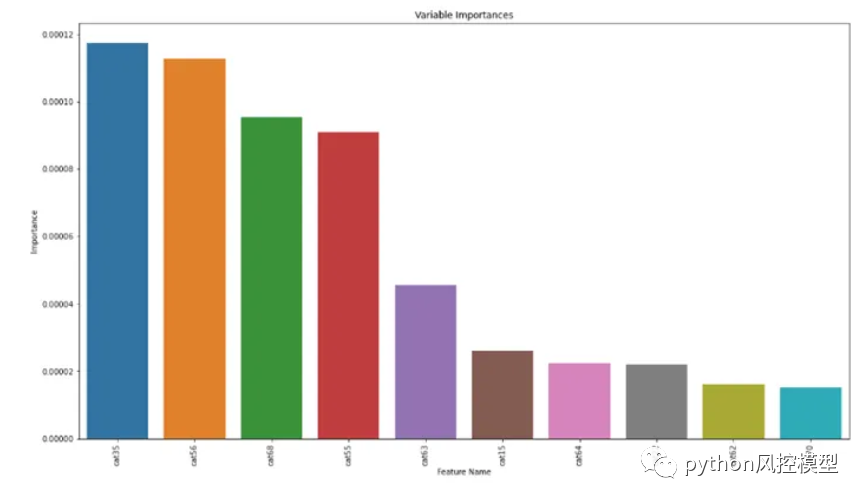
1.8 特征重要性
我们可以看到最后几个特征,如 Cat62、Cat64、Cat70、Cat22……当您在组合数据以及测试和训练上训练模型时,这些特征的重要性非常低。
1.9 主成分分析[PCA]:
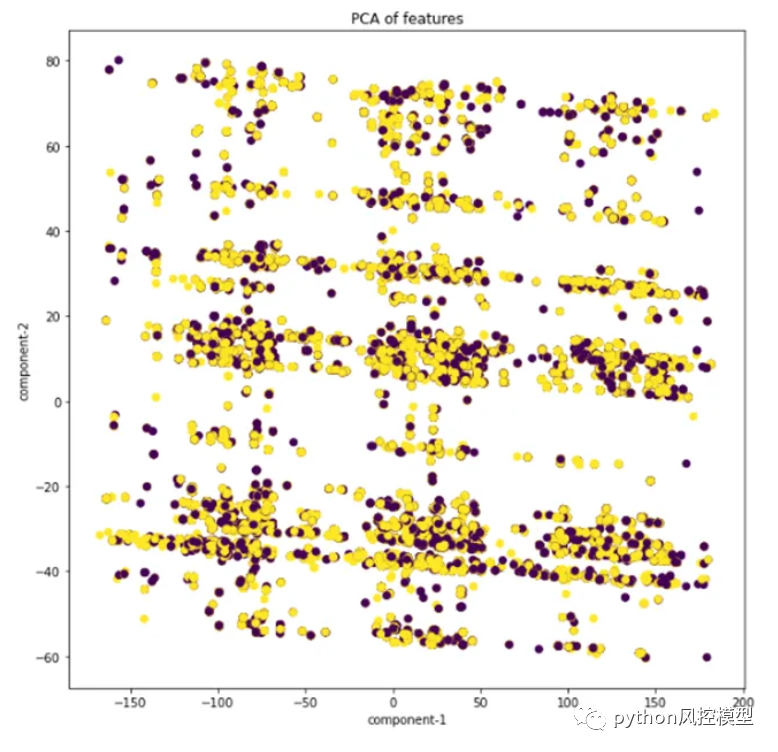
我观察到即使使用 2 个主成分的 模型,我们也无法轻松分离数据。这表示测试数据和训练数据都具有相似的分布。
1.9XGBOOST超参调优
我使用 Gridsearchcv 对 XGBOOST 模型调参
-
我们调整了 2 个参数并得到 {'max_depth': 10, 'min_child_weight': 1}
-
我们调整了 2 个参数并得到 {'gamma': 1, 'learning_rate': 0.1}
-
我们调整了 2 个参数并得到 {'colsample_bytree': 0.6, 'subsample': 0.8}
-
最终超参数调优结果:{'colsample_bytree': 0.5,'subsample': 0.8,'learning_rate': 0.1,'max_depth': 12,'min_child_weight': 1,'gamma':1}
寻找最好的 n_rounds :res = xgb.cv(params, xgtrain, num_boost_round=2500, nfold=5,stratified=False,early_stopping_rounds=50,verbose_eval=500, show_stdv=True,feval=log_xgboost_eval_mae, maximize=False)best_nrounds = res.shape[0] - 1cv_mean = res.iloc[-1, 0]cv_std = res.iloc[-1, 1]print('Ensemble-CV: {0}+{1}'.format(cv_mean, cv_std))print('Best n rounds are :',best_nrounds)
Ensemble-CV:0.40487799999999996+0.0002799499955349193
最佳 n 轮是:2418
最不重要 0 特征是 cat24最不重要 1 特征是 cat60最不重要 2 特征是 cat46最不重要 3 特征是 cat69最不重要 4 特征是 cat34最不重要 5 特征是 cat47 最不重要6 特征是 cat70 最不重要 7 特征是 cat20最不重要8 个特征是 cat15最不重要 9 个特征是 cat64最不重要 10 个特征是 cat62*********['cat24', 'cat60', 'cat46', 'cat69', 'cat34', 'cat47', 'cat70', 'cat20', 'cat15', 'cat64', 'cat62']
特征重要性在机器学习模型的各个方面都起着重要作用,因为它让我们理解了为什么它会按照它的方式做事。所以拥有一个高度可解释的模型总是好的。
我们可以看到 'cat14'、'cat35'、'cat97'、'cat20'、'cat48'、'cat86'、'cat70'、'cat62'、'cat69'、'cat15'、'cat64'——这些是训练模型的最不重要的特征。
总结:
很多数据集上,集成模型会比普通模型有更好的结果。我们仍然可以通过对模型进行一些更敏感的超参数调整来优化模型。我们可以删除最不重要的特征,也可以尝试做一些特征工程。我们可以尝试集成和深度学习模型以获得更好的分数。
Allstate美国好事达保险公司理赔预测模型案例就为大家介绍到这里,《Python金融风控模型案例实战大全》更多实战案例会定期更新,用于银行培训,大家记得收藏课程。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。