爬取每日一文并保存到 Word 文档的教程
在本教程中,我们将使用 Python 爬虫技术从每日一文网站(https://meiriyiwen.com/random)爬取文章,并将其保存到 Word 文档中。我们将涵盖以下知识点:HTTP 请求、HTML 解析、数据提取以及使用 BeautifulSoup 库进行网页解析。
1. HTTP 请求
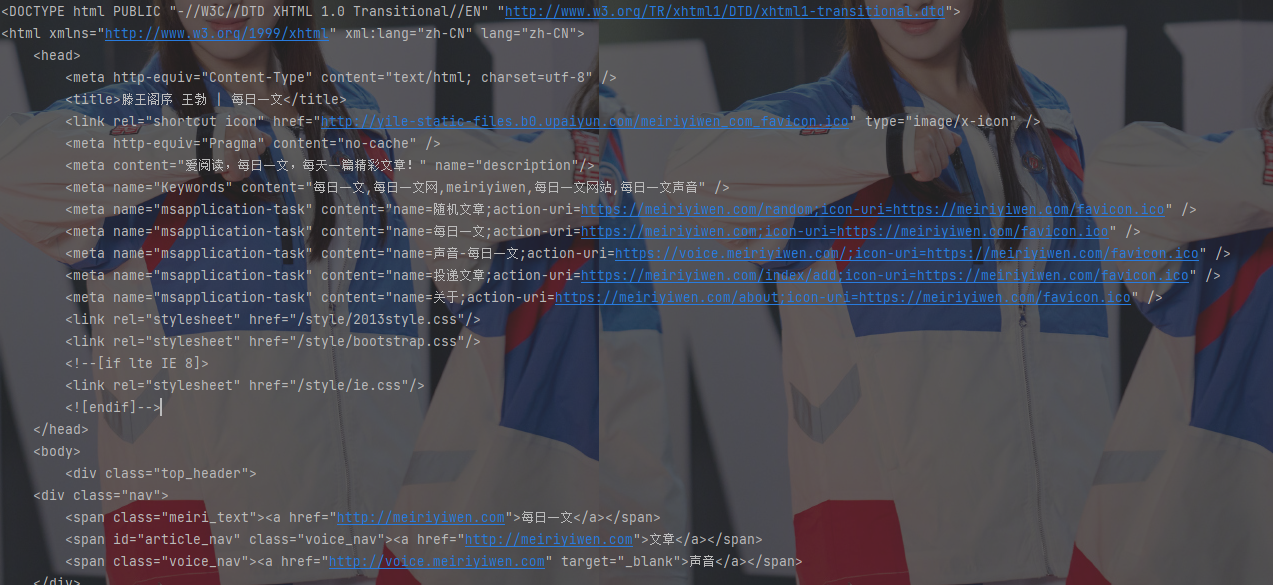
首先,我们需要发送一个 HTTP 请求来获取目标网页的内容。我们将使用 requests 模块中的 get() 方法发送 GET 请求,并打印观察获取的内容。
import requests
# 发送 HTTP GET 请求
response = requests.get('https://meiriyiwen.com/random')
# 解码响应内容
decoded_content = response.content.decode('utf-8')
# 打印观察获取的内容
print(decoded_content)
2. HTML 解析
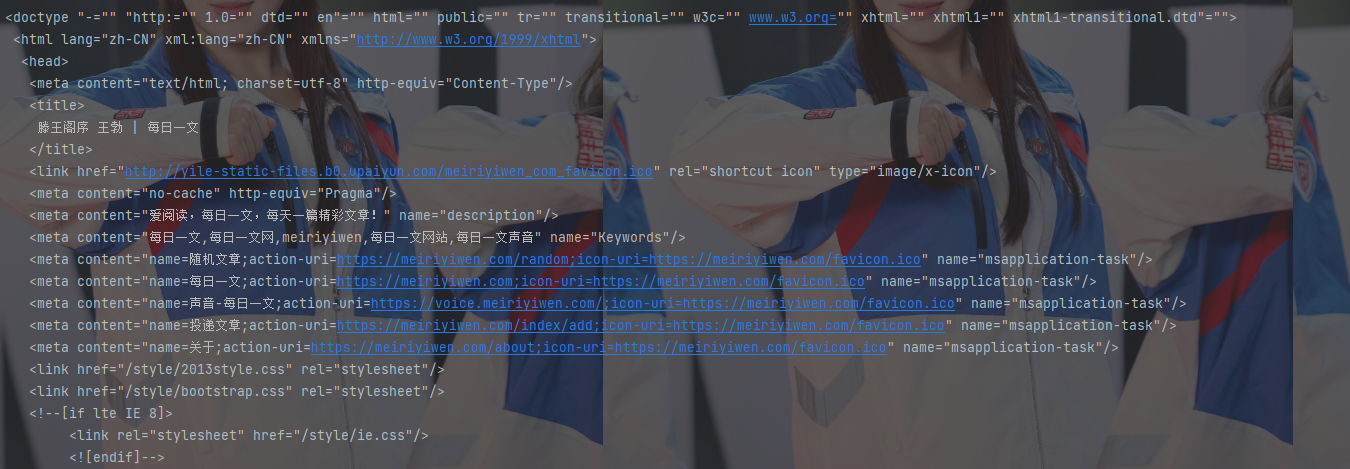
我们需要解析获取的 HTML 内容以提取所需的数据。为此,我们使用 BeautifulSoup 库进行 HTML 解析,并打印观察解析后的内容。
import requests
from bs4 import BeautifulSoup
# 发送 HTTP GET 请求
response = requests.get('https://meiriyiwen.com/random')
# 解码响应内容
decoded_content = response.content.decode('utf-8')
# 使用 BeautifulSoup 解析 HTML 内容
soup = BeautifulSoup(decoded_content, 'html.parser')
# 打印观察解析后的内容
print(soup.prettify()) # 输出格式化后的前 500 个字符,方便观察
3. 数据提取
现在,我们可以根据 HTML 结构提取所需的数据。我们的目标是提取文章的标题、作者和内容。
# 提取文章标题
title = soup.find('h1').text.strip()
# 提取文章作者
author = soup.find('p', class_='article_author').text.strip()
# 提取文章内容
content_tags = soup.find('div', class_='article_text').find_all('p')
content = '\n'.join([tag.text.strip() for tag in content_tags])

4. 保存到 Word 文档
为了将文章保存到 Word 文档中,我们使用 python-docx 库中的 Document 类。我们创建一个空的 Word 文档,添加标题、作者和内容,并保存为 .docx 文件。
from docx import Document
# 创建 Word 文档
document = Document()
# 添加标题
document.add_heading(title, level=1)
# 添加作者
document.add_paragraph('作者: ' + author)
# 添加内容
document.add_paragraph(content)
# 保存 Word 文档
doc_file_name = title + '.docx'
document.save(doc_file_name)
# 输出保存成功的提示信息
print("文件保存成功:" + doc_file_name)

完整代码
import requests # 导入 requests 模块,用于发送 HTTP 请求和获取网页内容
from bs4 import BeautifulSoup # 导入 BeautifulSoup 模块,用于解析 HTML 内容
from docx import Document # 导入 Document 类,用于创建和编辑 Word 文档
# 发送请求并获取网页内容
response = requests.get('https://meiriyiwen.com/')
response.raise_for_status() # 检查是否请求成功
html_content = response.content # 获取网页内容的二进制数据
# 解析 HTML 内容
soup = BeautifulSoup(html_content, 'html.parser') # 使用 BeautifulSoup 解析 HTML 内容
# 提取文章标题、作者和内容
title = soup.find('h1').text.strip() # 提取文章标题,使用 strip() 方法去除标题两边的空白字符
author = soup.find('p', class_='article_author').text.strip() # 提取文章作者
content_tags = soup.find('div', class_='article_text').find_all('p') # 提取文章内容的所有 <p> 标签
content = '\n'.join([tag.text.strip() for tag in content_tags]) # 将内容的所有段落文本拼接在一起,使用换行符分隔
# 创建 Word 文档
document = Document() # 创建一个空的 Word 文档
# 添加标题
document.add_heading(title, level=1) # 添加文章标题,设置标题级别为 1
# 添加作者
document.add_paragraph('作者: ' + author) # 添加作者信息
# 添加内容
document.add_paragraph(content) # 添加文章内容
# 保存 Word 文档
doc_file_name = title + '.docx' # 设置 Word 文档的文件名,使用文章标题作为文件名
document.save(doc_file_name) # 保存 Word 文档到指定文件名
# 输出保存成功的提示信息
print("文件保存成功:" + doc_file_name) # 打印保存成功的提示信息,包含文件名