发送带参数的请求
我们在使用百度搜索的时候经常发现url地址中会有一个
?,那么该问号后边的就是请求参数,又叫做查询字符串
在url携带参数
直接对含有参数的url发起请求
import requests # 导入 requests 模块
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 设置请求头,模拟浏览器访问
url = 'https://www.baidu.com/s?wd=python' # 要访问的 URL
response = requests.get(url, headers=headers) # 发起 GET 请求,并将响应保存在 response 变量中
通过params携带参数字典
1.构建请求参数字典
2.向接口发送请求的时候带上参数字典,参数字典设置给params
import requests # 导入 requests 模块
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 设置请求头,模拟浏览器访问
# 这是目标url
# url = 'https://www.baidu.com/s?wd=python'
# 最后有没有问号结果都一样
url = 'https://www.baidu.com/s?' # 要访问的 URL,注意此时未添加请求参数
# 请求参数是一个字典,即wd=python
kw = {
'wd': 'python'} # 设置请求参数
# 带上请求参数发起请求,获取响应
response = requests.get(url, headers=headers, params=kw) # 发起带有请求参数的 GET 请求,并将响应保存在 response 变量中
print(response.content) # 打印响应内容
print(response.status_code) # 打印响应状态码
print(response.request.url) # 打印请求的URL
当然携带参数,并不是只有这一种方法,第二种方式是直接将参数拼接到URL中。
import requests # 导入 requests 模块
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"} # 设置请求头,模拟浏览器访问
# 目标url
url = 'https://www.baidu.com/s?wd={}'.format("python")
# 发送GET请求
response = requests.get(url, headers=headers) # 发起带有请求参数的 GET 请求,并将响应保存在 response 变量中
print(response.content) # 打印响应内容
print(response.status_code) # 打印响应状态码
print(response.request.url) # 打印请求的URL
- 同样地,我们导入
requests库和定义请求头部(headers)。 - 然后,我们构造完整的请求URL,将参数"python"拼接到URL中。
- 接着,我们使用
requests.get函数发送GET请求,通过传递headers将头部添加到请求中。 - 最后,我们打印响应状态码和请求的URL。
这两种方式的结果应该是相同的,都会发送一个带有指定头部和参数的GET请求到百度搜索页面。一种方式是通过params参数传递参数,另一种方式是直接拼接到URL中。根据需求和习惯,您可以选择其中一种方式来发送带有头部和参数的请求。
运行结果
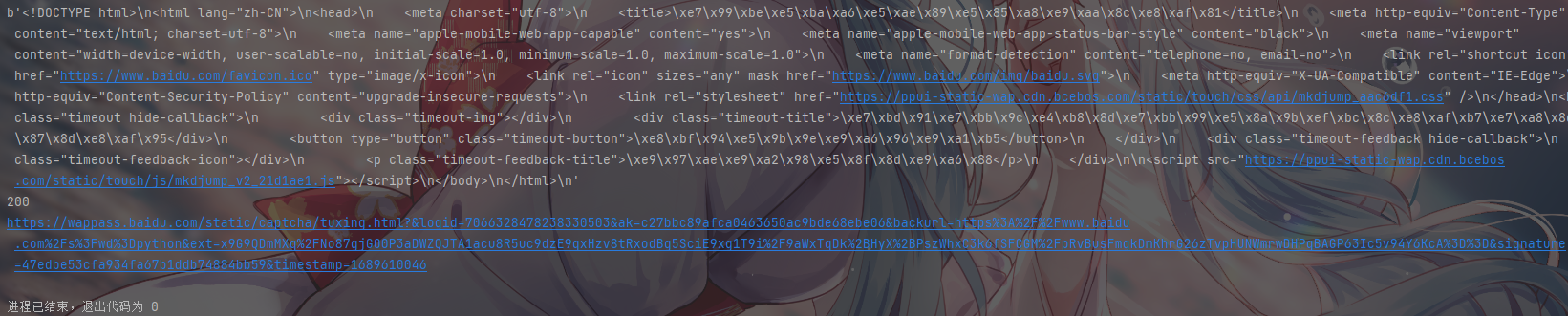
从运行结果可以看出
1.返回了
响应内容·2.返回了
状态码3.返回了经过我们携带参数后发送请求后得到的
url地址
思考
前两项都没有问题
第三项返回的url地址是这样的
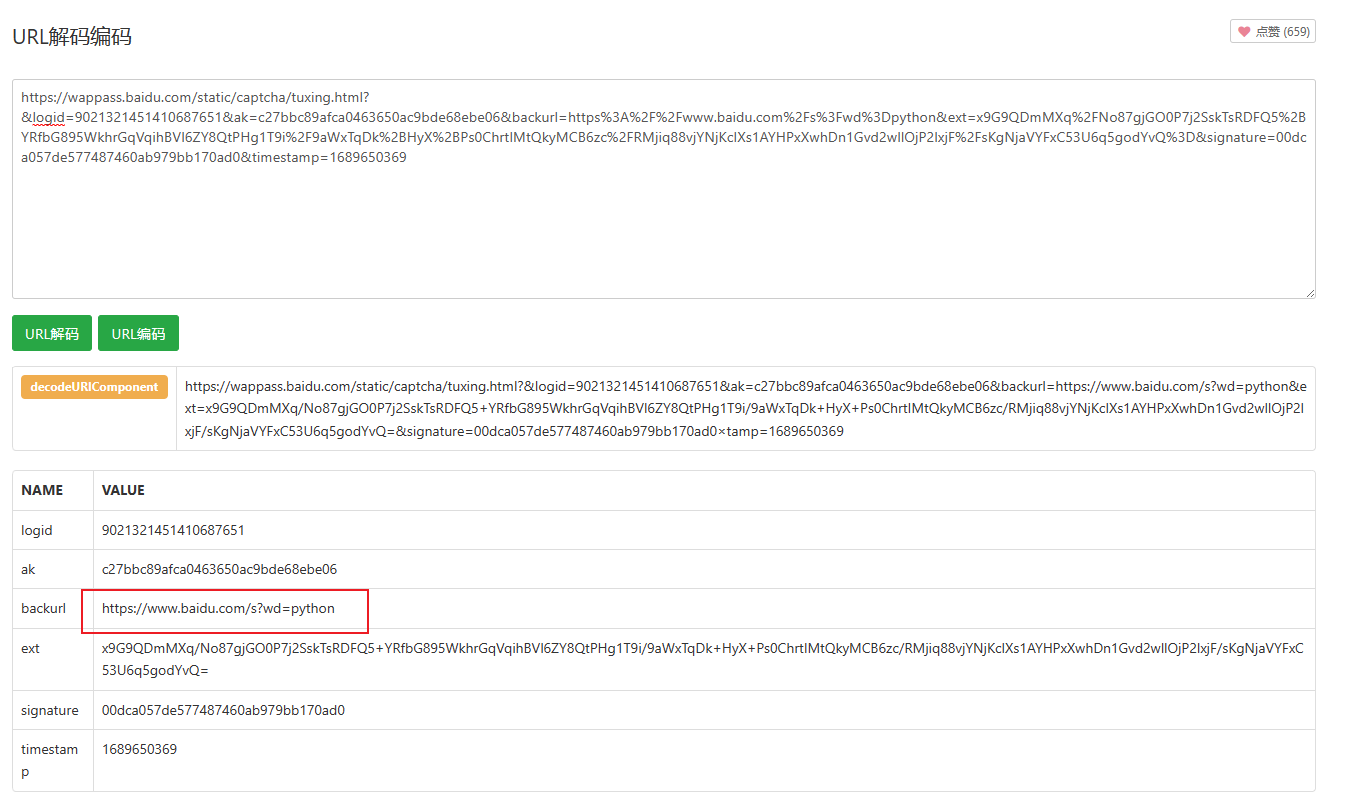
https://wappass.baidu.com/static/captcha/tuxing.html?&logid=8942509947662239692&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3D%25E4%25BC%25A0%25E6%2599%25BA%25E6%2592%25AD%25E5%25AE%25A2&ext=x9G9QDmMXq%2FNo87gjGO0P1Mp5uvFzuAL%2F5H%2B6udoILQaaeyhUvJM%2FH2FbXwC2V2ug1T9i%2F9aWxTqDk%2BHyX%2BPs2XG9KoIOTaqsDSpFr2Y1s11BToUucrnPfSjdXR1JUIw4uIBNlXlGYC%2BrQSfMy70TKgNjaVYFxC53U6q5godYvQ%3D&signature=f03cf9c4de5408e13ab9ca4a61e8af8c×tamp=1689611641
为什么会是这样的呢?
我们开头讲过什么是参数,现在来完整介绍一下
在发送请求时,参数是用于向服务器传递额外数据的一种方式。它们通常以键值对的形式出现,并附加在请求的URL或请求体中,以便服务器能够理解和使用这些数据。
在使用 requests 库发送请求时,您可以通过不同的方式传递参数:
-
URL参数:将参数直接附加在URL的查询字符串中,通常使用问号(?)将URL路径和参数部分分隔,多个参数之间使用与号(&)连接。例如:
https://www.example.com/search?q=keyword&page=1。 -
请求体参数:对于一些请求方法(如POST、PUT),参数可以作为请求体中的数据进行发送。这种方式常用于提交表单数据或传递较大量的数据。参数会作为请求体的一部分进行发送。
经过复习了参数的知识点 与练习的案例我们可以得到
在百度搜索URL中,
wd是一个参数,表示搜索关键词(word)。百度搜索URL的格式通常是https://www.baidu.com/s?wd={搜索关键词},其中{搜索关键词}就是需要进行搜索的内容。当您在浏览器地址栏中输入关键词并按下回车键进行搜索时,浏览器会将关键词作为
wd参数的值添加到搜索URL中,然后发送请求到百度搜索服务器。百度搜索服务器会根据这个参数的值,返回相应的搜索结果页面。您是可以将
wd参数替换成其他名称,但需要确保在构建URL时,参数名称要与百度搜索服务器接受的参数名称一致。一般来说,wd参数是百度搜索接口约定的标准参数名称。例如,以下两个URL的效果是等价的:
https://www.baidu.com/s?wd=pythonhttps://www.baidu.com/s?q=python
在这两个URL中,
wd和q都是搜索关键词的参数名称,只要保持URL中的参数名正确,百度搜索服务器就可以正确解析搜索关键词并返回相应的搜索结果。
第一步,我们现在控制输出中找线索

第二步,在浏览器中打开百度搜索python,查看得出的实际URL地址
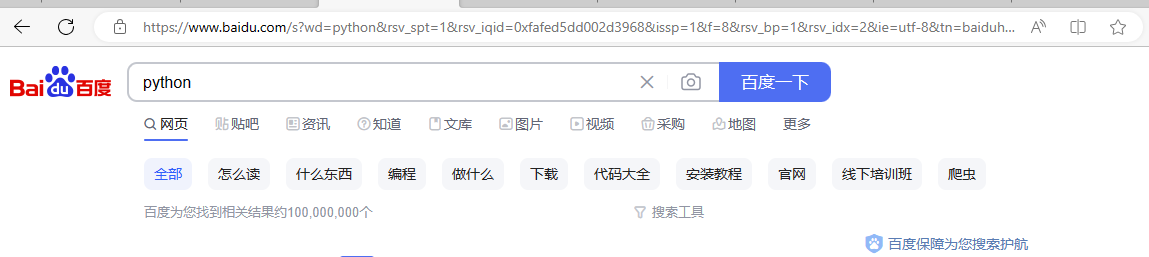
https://www.baidu.com/s?wd=python&rsv_spt=1&rsv_iqid=0xfafed5dd002d3968&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=7&rsv_sug1=5&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=2276&rsv_sug4=4493&rsv_sug=1
可以发现两者得出的url地址是不一样的。
为什么返回的url地址里会有%这些符号呢,是经过了编码还是加密呢?
返回的URL地址中的百分号(%)符号是经过URL编码的结果,而不是加密。
URL编码是一种用于对URL中的特殊字符进行转义的过程。它确保URL的完整性和可传输性,因为某些字符在URL中具有特殊含义,可能会引起解析错误或干扰URL的结构。
为什么需要URL编码?
- URL中的特殊字符(如空格、问号、等号等)必须进行编码,以便正确传递和解析。
- URL编码还允许在URL中包含非ASCII字符(如中文字符),因为URL的编码格式采用的是ASCII码,不支持直接包含非ASCII字符。
URL编码的过程:
- 将URL中的特殊字符转换为%加两位十六进制数的形式。例如,空格会被编码为%20。
- 非ASCII字符会被转换为UTF-8编码的字节序列,然后将每个字节转换为%加两位十六进制数的形式。
URL编码的示例: 原始URL:
https://www.example.com/search?q=keyword space编码后的URL:https://www.example.com/search?q=keyword%20space在Python中,可以使用
urllib.parse模块中的quote()函数进行URL编码,将特殊字符转换为URL编码形式。而unquote()函数则用于解码,将编码字符还原为原始字符。
有编码就有解码
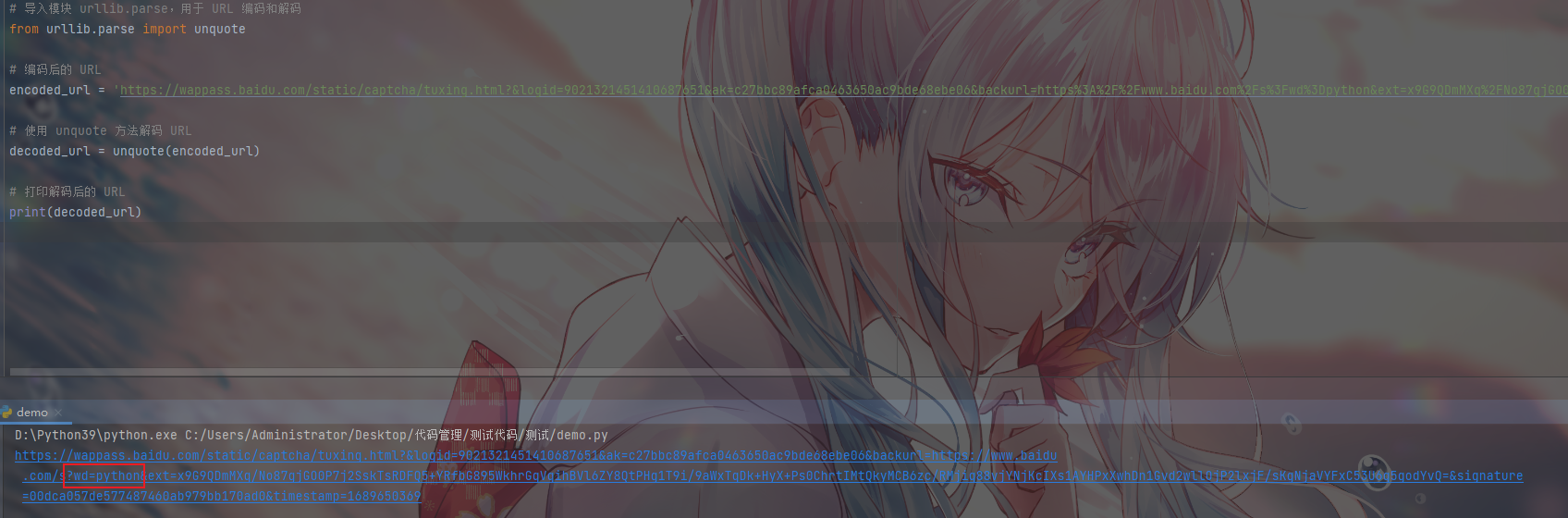
- 通过python的第三方库进行解码
# 导入模块 urllib.parse,用于 URL 编码和解码
from urllib.parse import unquote
# 编码后的 URL
encoded_url = 'https://wappass.baidu.com/static/captcha/tuxing.html?&logid=9021321451410687651&ak=c27bbc89afca0463650ac9bde68ebe06&backurl=https%3A%2F%2Fwww.baidu.com%2Fs%3Fwd%3Dpython&ext=x9G9QDmMXq%2FNo87gjGO0P7j2SskTsRDFQ5%2BYRfbG895WkhrGqVqihBVl6ZY8QtPHg1T9i%2F9aWxTqDk%2BHyX%2BPs0ChrtIMtQkyMCB6zc%2FRMjiq88vjYNjKcIXs1AYHPxXwhDn1Gvd2wllOjP2lxjF%2FsKgNjaVYFxC53U6q5godYvQ%3D&signature=00dca057de577487460ab979bb170ad0×tamp=1689650369'
# 使用 unquote 方法解码 URL
decoded_url = unquote(encoded_url)
# 打印解码后的 URL
print(decoded_url)
-
通过网络上的URL解码网站进行解码