一 只进行推理
如果只是进行推理的话,还是比较容易计算的。
目前模型的参数绝大多数都是float32类型, 占用4个字节。所以一个粗略的计算方法就是,每10亿个参数,占用4G显存(实际应该是10^9*4/1024/1024/1024=3.725G,为了方便可以记为4G)。
比如LLaMA的参数量为7000559616,那么全精度加载这个模型参数需要的显存为:
7000559616 * 4 /1024/1024/1024 = 26.08G

如果用用半精度的FP16/BF16来加载,这样每个参数只占2个字节,所需显存就降为一半,只需要13.04G。
目前int4就是最低精度了,再往下效果就很难保证了。比如百川给的量化结果对比如下:
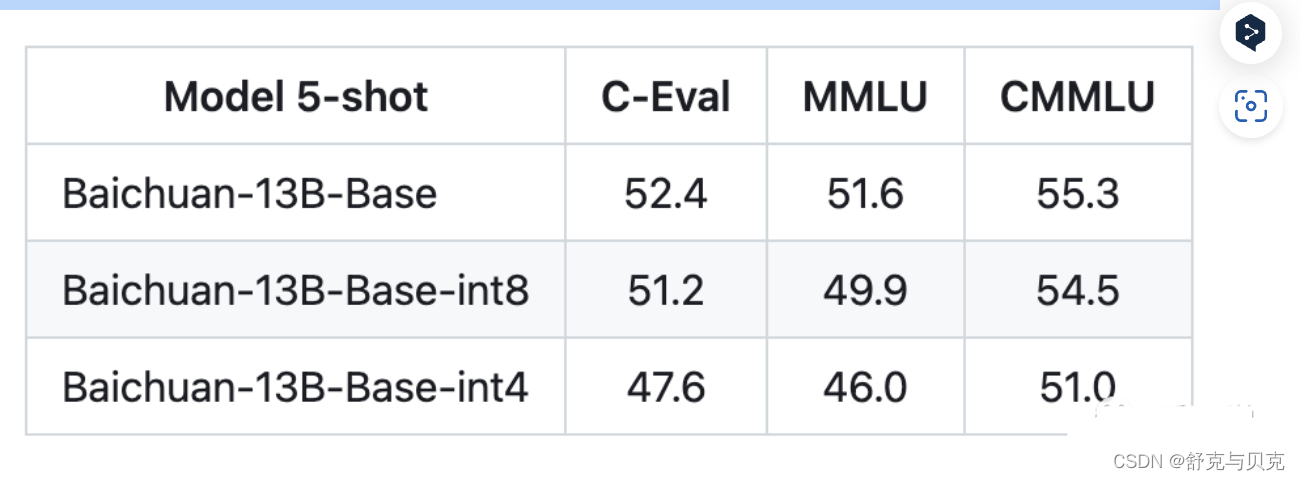
注意上面只是加载模型到显存,模型运算时的一些临时变量也需要申请空间,比如你beam search的时候。所以真正做推理的时候记得留一些Buffer,不然就容易OOM。
如果显存还不够,就只能采用Memery Offload的技术,把部分显存的内容给挪到内存,但是这样会显著降低推理速度。
| dtype | 每10亿参数需要占用内存 |
|---|---|
| float32 | 4G |
| fp16/bf16 | 2G |
| int8 | 1G |
| int4 | 0.5G |
二 进行模型训练
以LLM中最常见的Adam + fp16混合精度训练为例,分析其显存占用有以下四个部分:
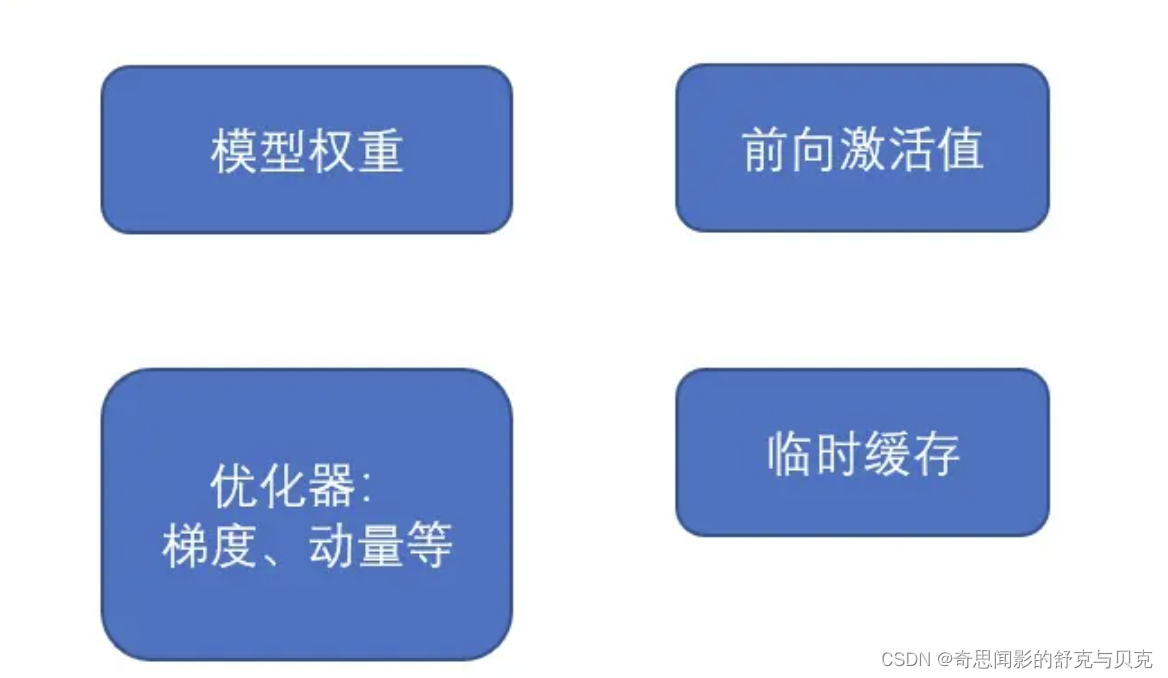

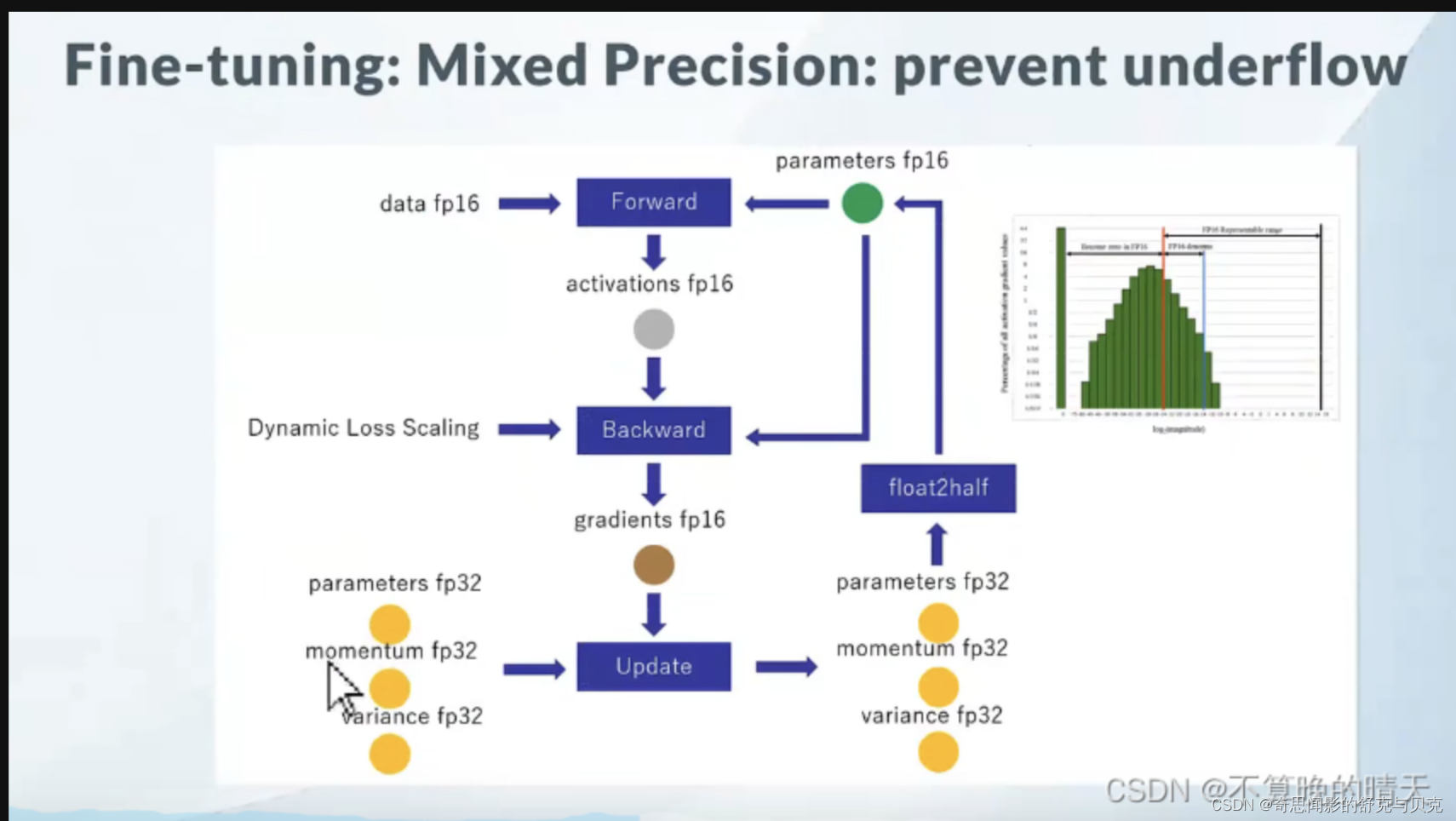
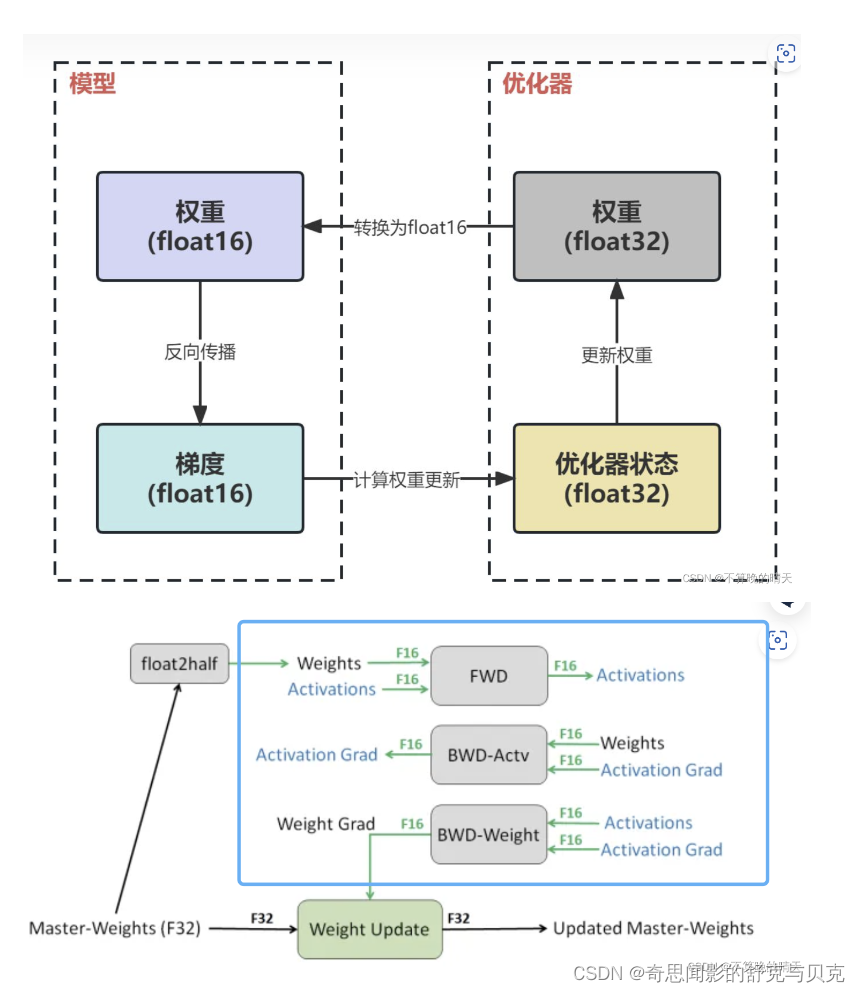

GPT-2含有1.5B个参数,如果用fp16格式,只需要1.5G*2Byte=3GB显存, 但是模型状态实际上需要耗费1.5B*16=24GB.
比如说有一个模型参数量是1M,在一般的深度学习框架中(比如说PyTorch),一般是32位存储。32位存储的意思就是1个参数用32个bit来存储。那么这个拥有1M参数量的模型所需要的存储空间的大小即为:1M * 32 bit = 32Mb = 1M * 4Byte = 4MB。因为1 Byte = 8 bit。现在的quantization技术就是减少参数量所占的位数:比如我用16位存储,那么:所需要的存储空间的大小即为:1M * 16 bit = 16Mb = 2MB。

结论如下:
- 不考虑Activation,3090的模型容量上限是 24/16=1.5B,A100的模型容量上限是 80/16=5B
- 假设训练的过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得我们的理论计算值
16Φ更接近真实的显存占用,那么24G的3090的模型容量上限是1.5B(差不多是GPT-2的水平),80G的A100的模型容量上限是5B
- 假设训练的过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得我们的理论计算值
- 考虑Activation,3090的模型容量上限是 0.75B,A100的容量上限是 2.5B
- batchsize为1的训练效率非常低,batchsize大于1才能充分发挥GPU的效率,此时Activation变得不可忽略。经验之谈,一般需要给Activation预留一半的显存空间(比如3090预留12G,A100预留40G),此时3090的模型容量上限是0.75B,A100的容量上限是2.5B,我们实际测试结果接近这个值
- 激活在训练中会消耗大量的显存。一个具体的例子,模型为1.5B的GPT-2,序列长度为1K,batch size为32,则消耗显存为60GB。
- [1B, 5B] 是目前市面上大多数GPU卡的分水岭区间
- [0, 1B) 市面上绝大多数卡都可以直接硬train一发
- [1B, 5B] 大多数卡在这个区间的某个值上触发模型容量上限,具体触发值和显存大小有关
- (5B, ~) 目前没有卡能裸训