非线性激活函数是深度学习网络重要的组成部分,随着近几年的快速发展,越来越多的激活函数被提出与改进。选择一个合适的激活函数将决定了模型的最终结果。下文总结了13种常见的激活函数的计算方式与对应图像,文中的计算方式来自于pytorch。
1.Sigmoid
这是一款比较早的激活函数,其计算公式如下所示:
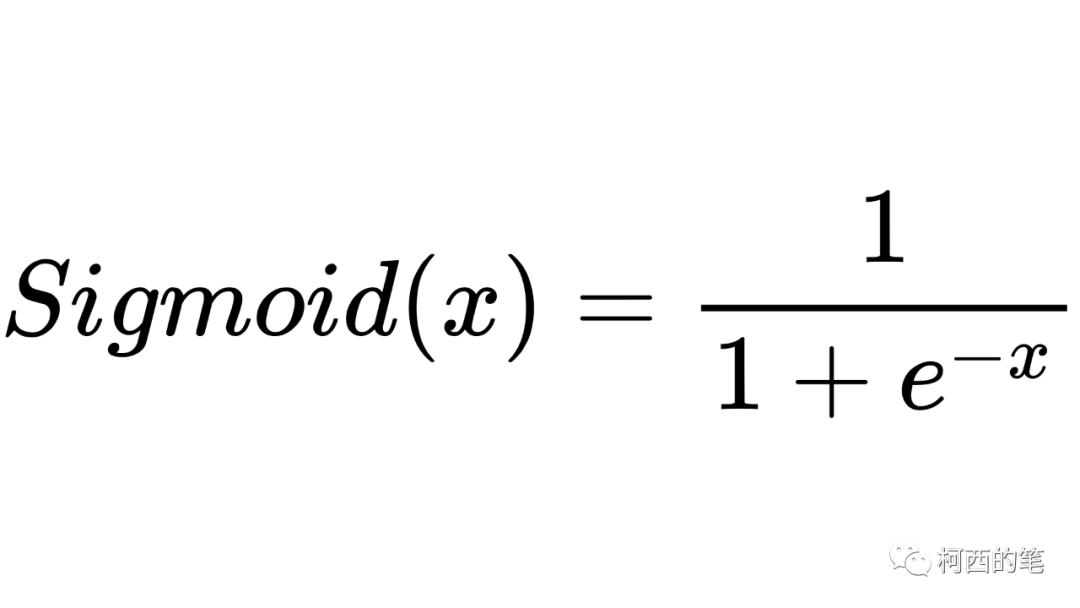
其图示如下:

优点:
Sigmoid函数的输出在(0,1)之间,输出范围有限,优化稳定,可以用作输出层。
连续函数,便于求导。
缺点:
需要幂运算,计算成本高。
输出不是以0为均值的,导致收敛速度下降。
容易出现梯度弥散,在反向传播时,当梯度接近于0,权重基本不会更新,从而无法完成深层网络的训练。
2.LogSigmoid
其计算公式如下所示:
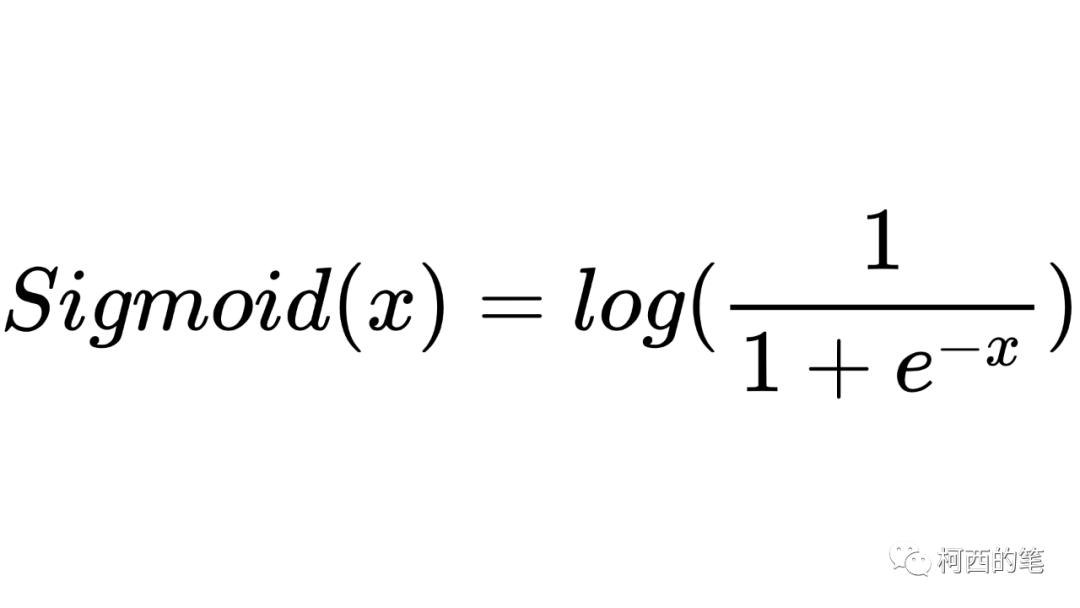
其图示如下:
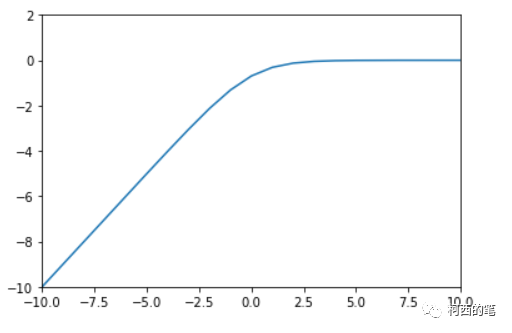
3.Relu
深度神经网络中最常用的激活函数之一,其计算公式如下所示:
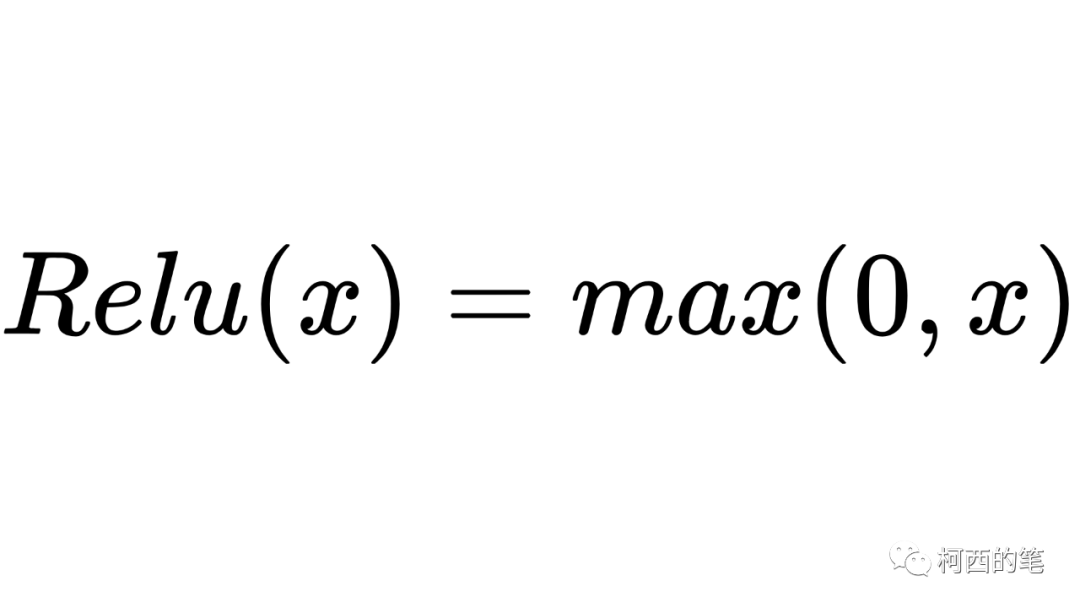
其图示如下:
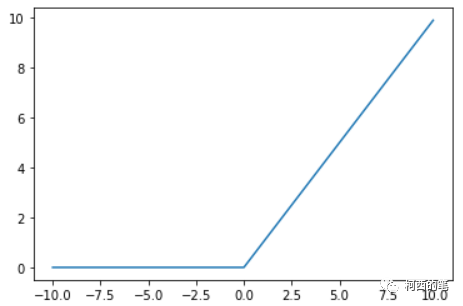
优点:
在x>0区域上,不会出现梯度饱和、梯度消失的问题,收敛速度快。
不需要进行指数运算,因此运算速度快,复杂度低。
缺点:
输出的均值非0.
存在神经元死亡,在x<0时,梯度为0。这个神经元及之后的神经元梯度永远为0,不再对任何数据有所响应,导致相应参数永远不会被更新。
4.LeakyRelu
上述的Relu对x小于0的情况均输出0,而LeakyRelu在x小于0时可以输出非0值,其计算公式如下所示:
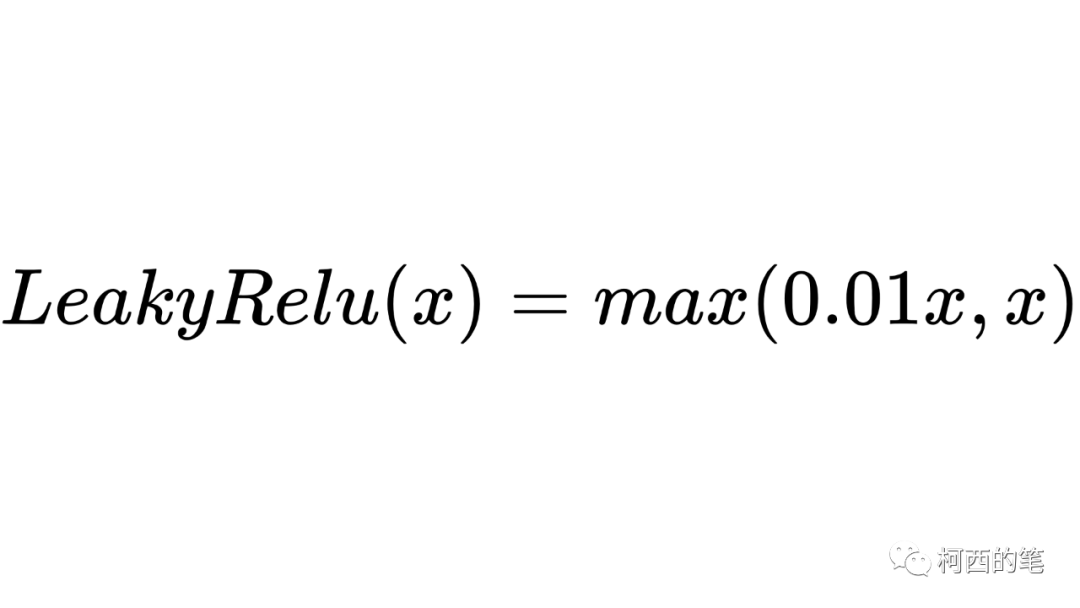
其图示如下:
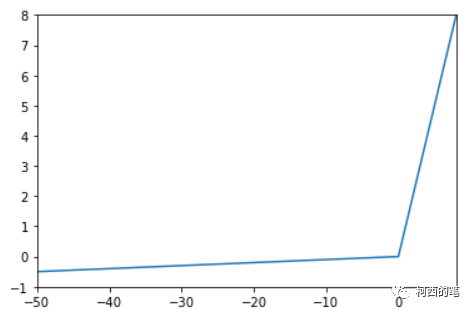
优点:
解决了Relu的神经元死亡问题问,在负区域具有小的正斜率,因此即使对于负输入值,它也可以进行反向传播。
具有Relu函数的优点。
缺点:
结果不一致,无法为正负输入值提供一致的关系预测
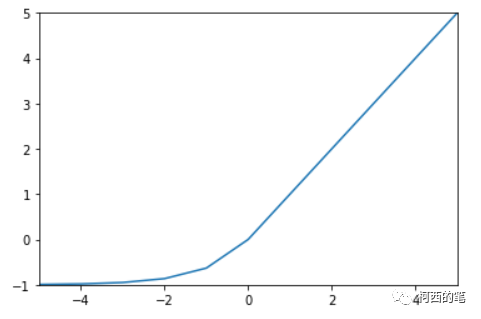
5.Elu
同样是针对ReLU的负数部分进行的改进,ELU激活函数对x小于零的情况采用类似指数计算的方式进行输出,其计算公式如下所示:
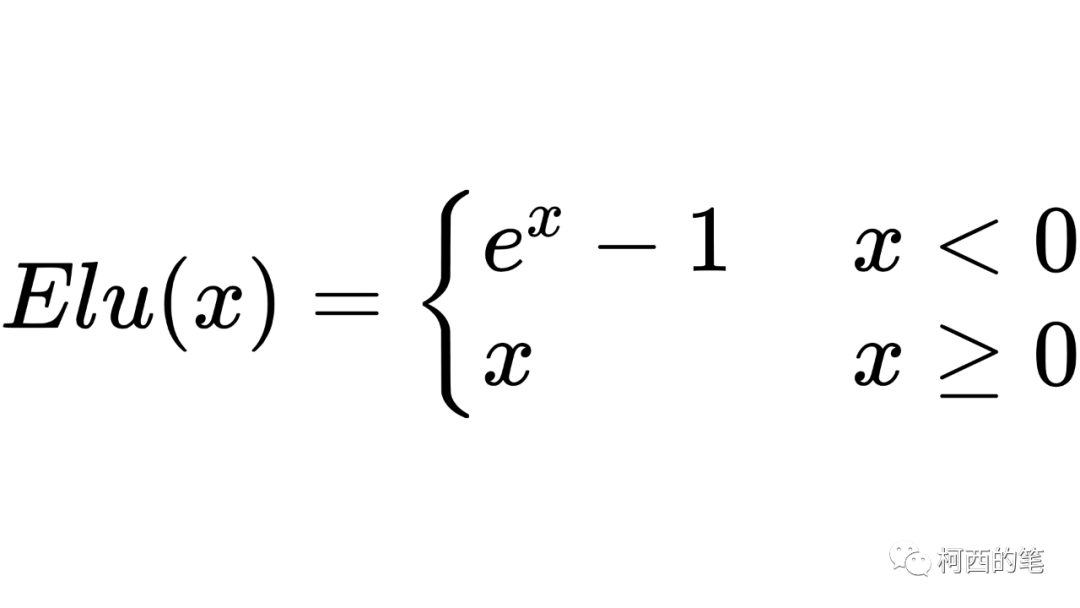
其图示如下:
优点:
在所有点上都是连续可微的。
与其他线性非饱和激活函数(如Relu及其变体)相比,有着更快的训练时间。
没有神经元死亡的问题。
作为非饱和激活函数,它不会遇到梯度爆炸或消失的问题,并且拥有更高的准确性。
缺点:
涉及到幂运算,计算速度较慢。
6.PRelu
其中a不是固定的,是通过反向传播学习出来的。其计算公式如下所示:
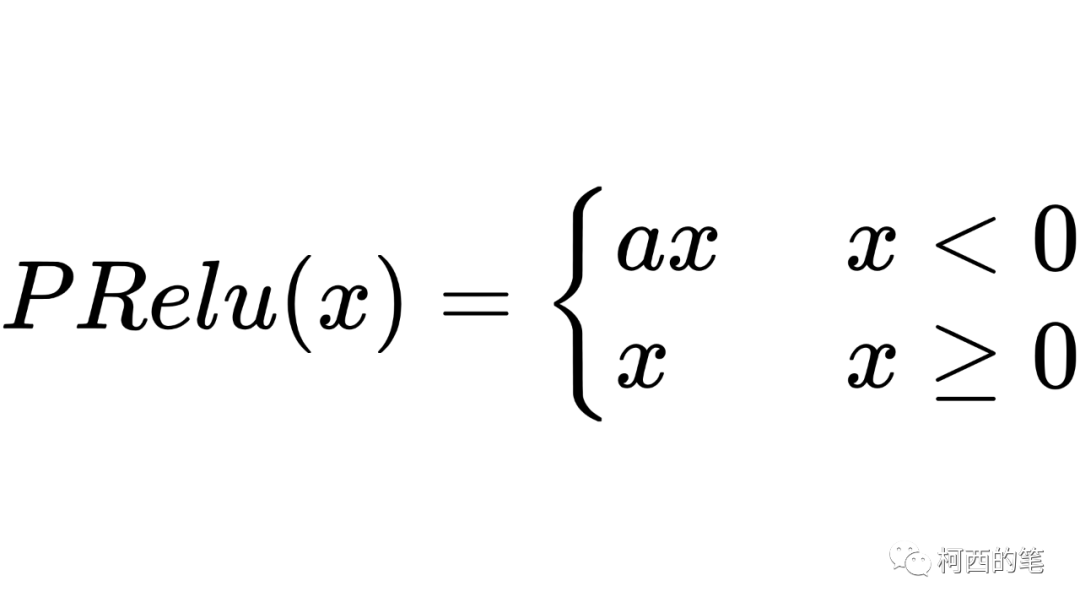
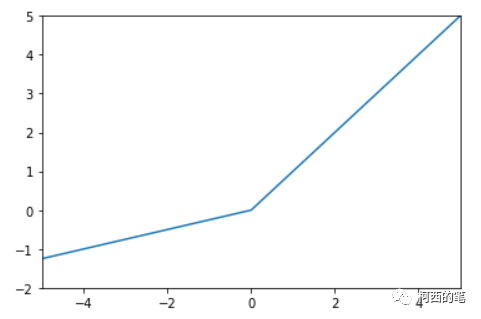
其图示如下:
7.Relu6
Relu6限制Relu的的输出不超过6,其计算公式如下所示:
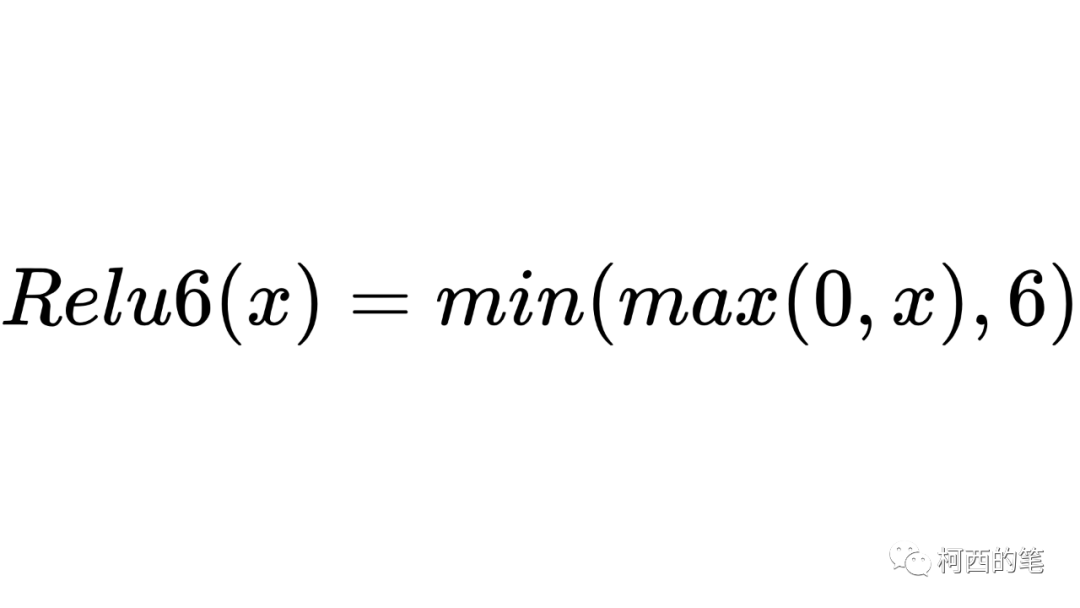
其图示如下:
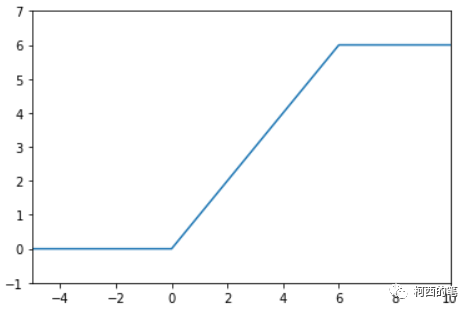
Relu在x>0的区域使用x进行线性激活,有可能造成激活后的值太大,影响模型的稳定性,为抵消ReLU激励函数的线性增长部分,可以使用Relu6函数。
8.RRelu
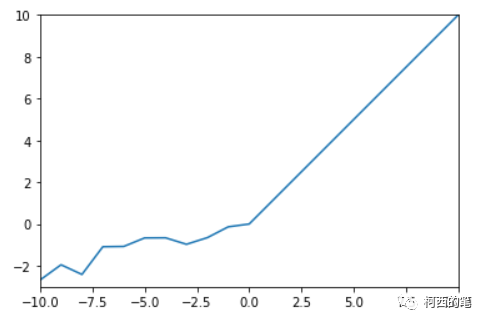
“随机纠正线性单元”RRelu也是LeakyRelu的一个变体。在RRelu中,负值的斜率在训练中是随机的,在之后的测试中就变成了固定的了。其计算公式如下所示:
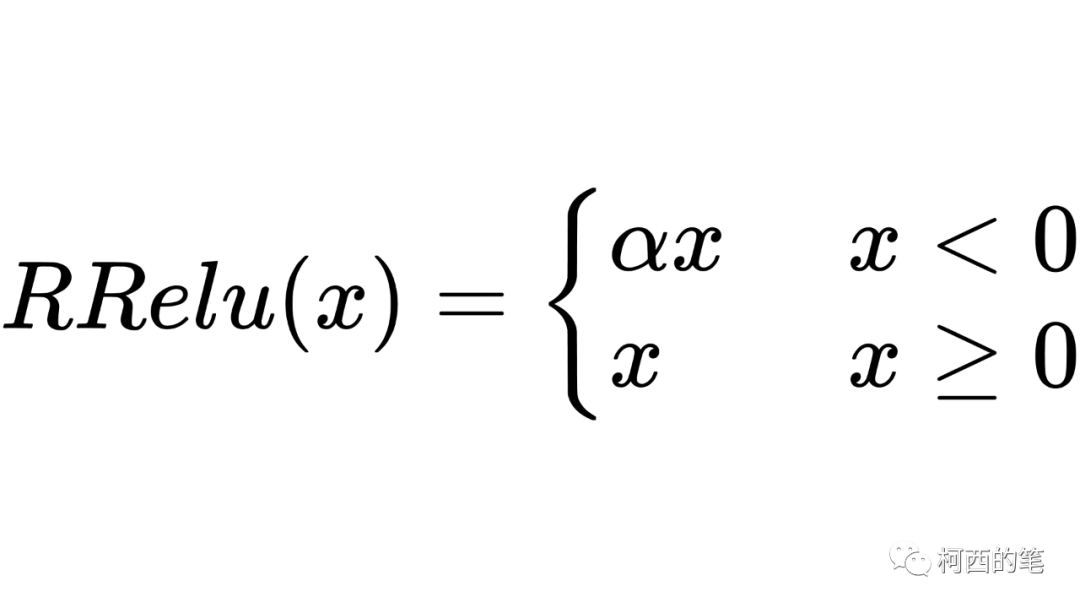
其图示如下:
9.SElu
SElu和Elu的形式比较类似,但是多出一个scale参数。其计算公式如下所示:
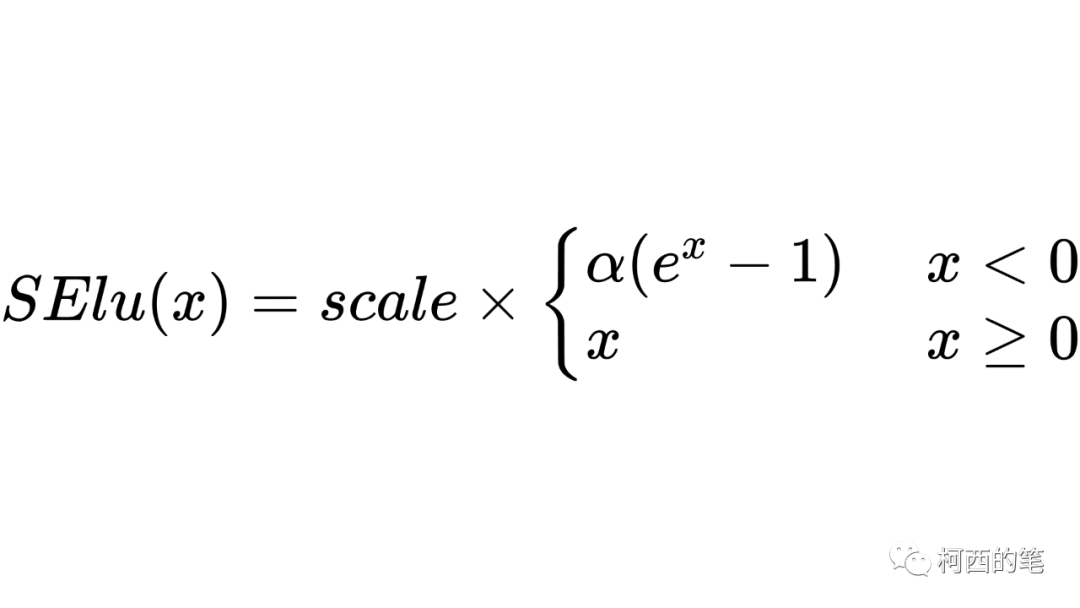
其图示如下:
pytorch中acale=1.0507009873554804934193349852946。
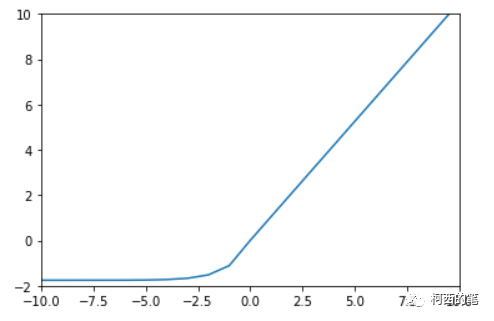
10.CElu
与上述的SElu类似,CElu同样采用负数区间为指数计算,整数区间为线性计算,其计算公式如下所示:
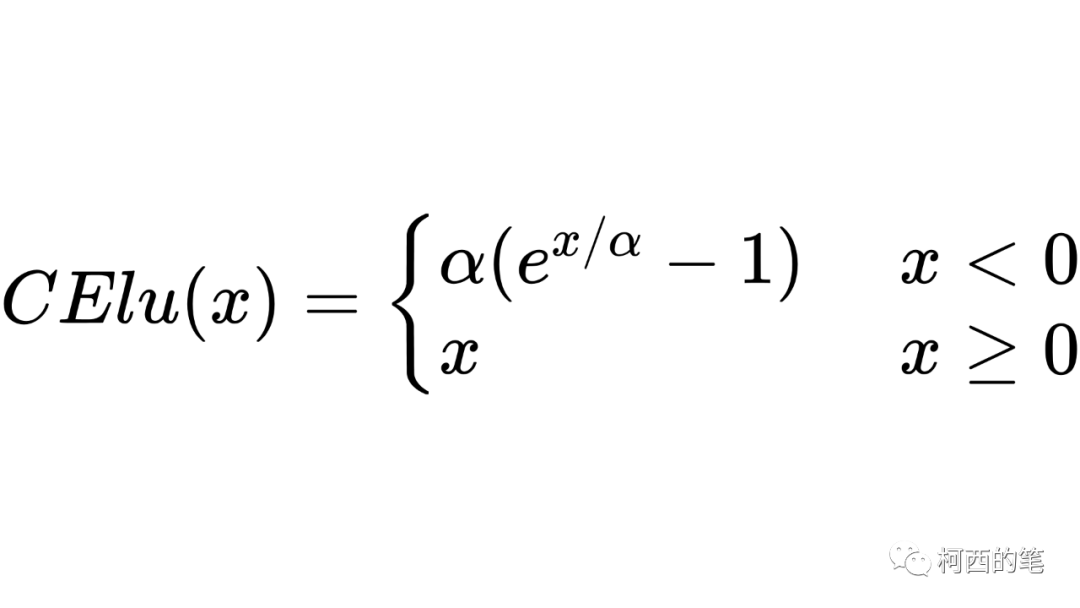
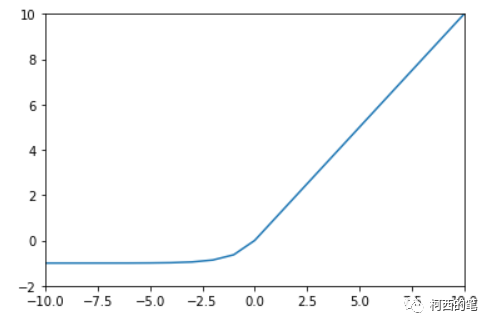
其图示如下:
11.GElu
在激活函数中加入正则化的方式,其计算公式如下所示:
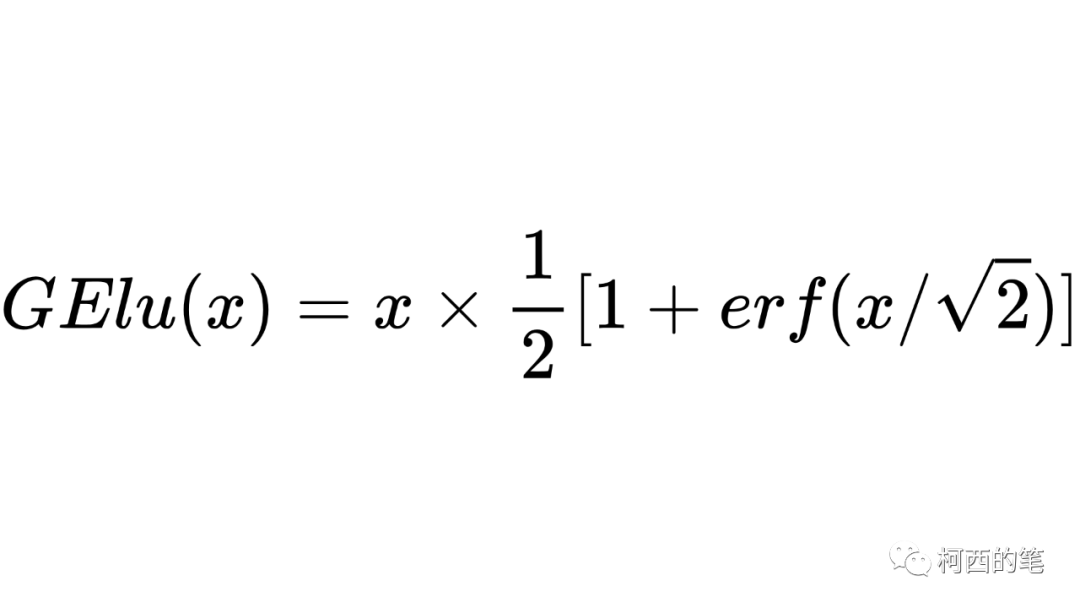
因为erf无解析表达式,原论文给出了近似解。
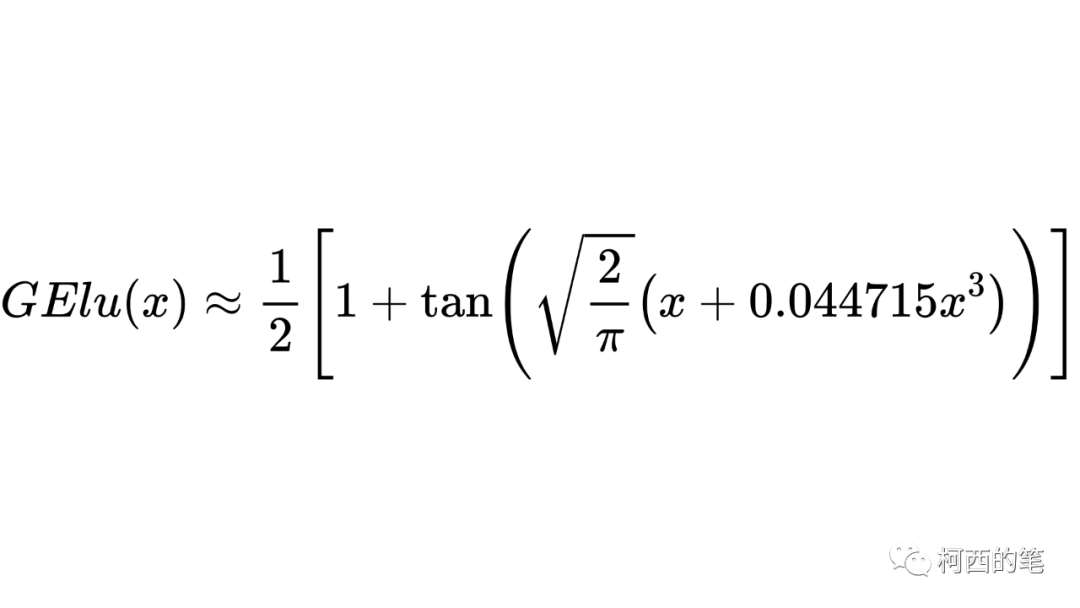
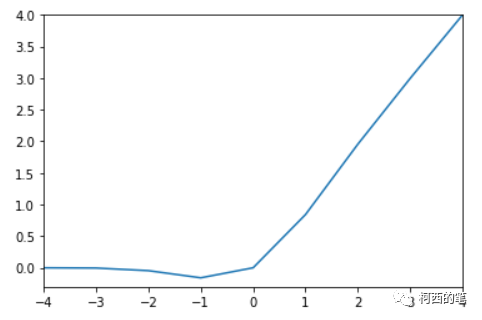
其图示如下:
12.Tanh
数学中的双曲正切函数Tanh也是一种神经网络常用的激活函数,尤其是用于图像生成任务的最后一层,其计算公式如下所示:
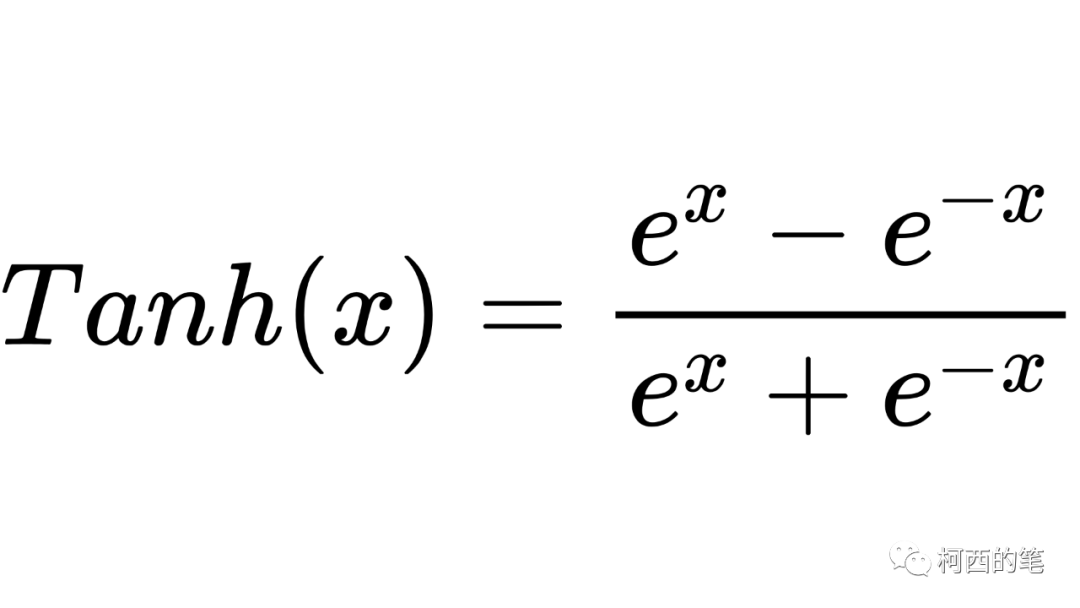
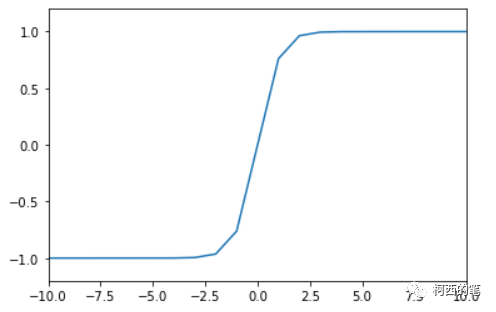
其图示如下:
优点:
输出均值为0,使其收敛速度要比sigmoid快,可以减少迭代次数。
缺点:
它的缺点是需要幂运算,计算成本高
同样存在梯度消失,因为在两边一样有趋近于0的情况。
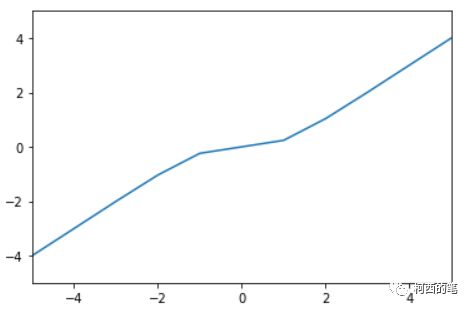
13.Tanhshrink
Tanhshrink直接采用输入减去双曲正切值,其计算公式如下所示:
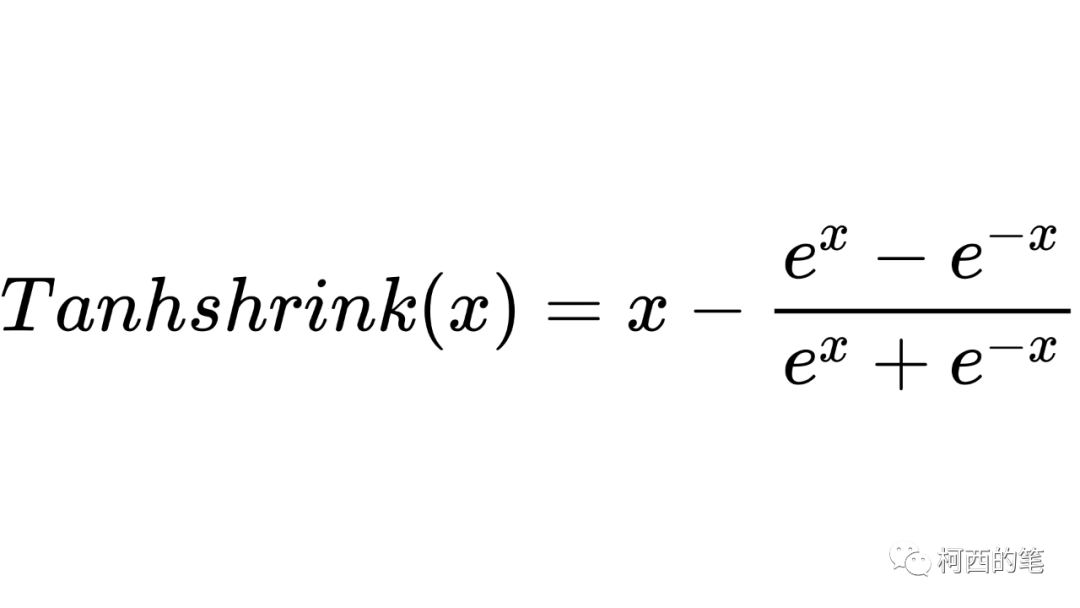
其图示如下:
总结:
首先使用ReLU,速度最快,然后观察模型的表现。
如果ReLU效果不是很好,可以尝试LeakyRelu等变种
在深度不是特别深的CNN中,激活函数的影响一般不会太大。