DataWhale AI夏令营——机器学习
学习记录一
已配置环境,跑通baseline,并在此基础上对数据进行了简单的分析。
1. 异常值分析
对训练集中的缺失值和异常值进行分析
train_data.info()
train_data.describe()
观察到数据中不存在缺失值,存在异常值train_dataset['下部温度9'] == -32768.000000]。删除该缺失值。
train_dataset.drop(train_dataset[train_dataset['下部温度9'] == -32768.000000].index).reset_index(drop=True)
2. 单变量箱线图可视化
对训练集和测试集中的流量、上部设定温度和下部设定温度的数据分布进行了箱线图可视化
观察到上部和下部温度设定数据中存在一些异常值,对应数据中2023/1/7、2023/1/8,2023/1/9 三日的数据。
在Baseline(6.29551)基础上进行了两处改动:
- 删除了数据中存在的一处错误值(6.72811)
- 删除2023/1/7、2023/1/8,2023/1/9 三日的数据(6.73844)

3. 特征重要性分析
接着尝试了分析对于单个预测变量的有效特征分析
- 计算相关性矩阵
df = pd.concat([X, y.iloc[:,0]], axis = 1) # X是处理后的训练数据,y是标签
corr_matrix = df.corr()
corr_matrix['上部温度1'].sort_values(ascending=False)
- 对于
lightgbm的特征重要性
feature_importance = model.feature_importance()
sorted_features = sorted(zip(X.columns, feature_importance), key=lambda x: x[1], reverse=True)
# 打印按照feature_importance值降序排列的特征列表
for feature, importance in sorted_features:
print(f"{
feature}: {
importance}")
相关性矩阵计算的是线性相关性,所以结果观察到和lightgbm的特征重要性的结果是有些不同的。
下一步打算在针对每个预测输出的结果构建衍生不同的特征并进行特征筛选。
学习记录2 (2023.07.27更新)
这几天主要是和Baseline的斗争,然后全部失败。从数据层面,特征工程,数据划分方式,后处理都做了尝试。
1. 数据层面
之前上一次发现的数据中存在缺失值(为0)和异常值,采用了查找筛选出然后改动。而最近通过可视化发现,几乎每个特征都存在异常值。尤其体现在流量特征中。
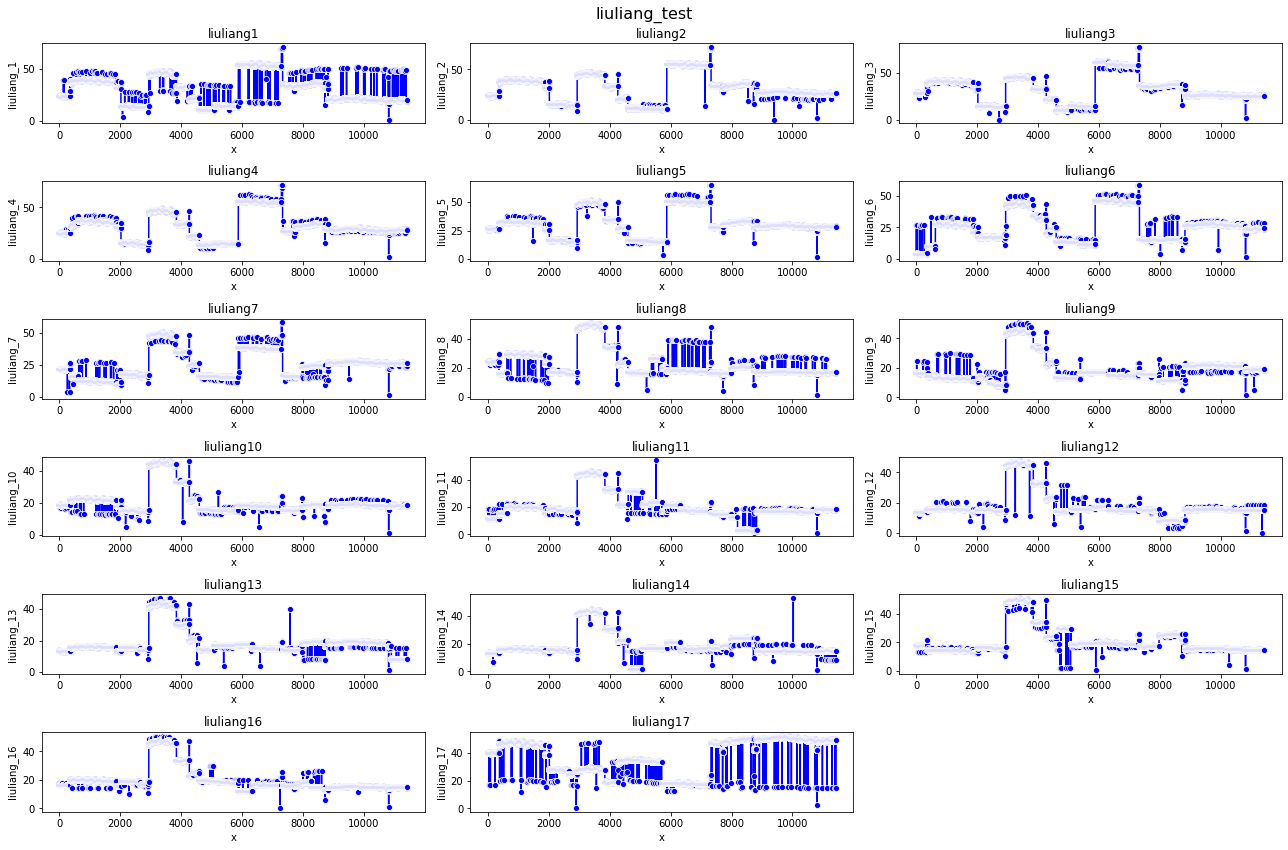
上图是17个流量特征在训练数据中的折线图,可以看到还是有很大的波动。
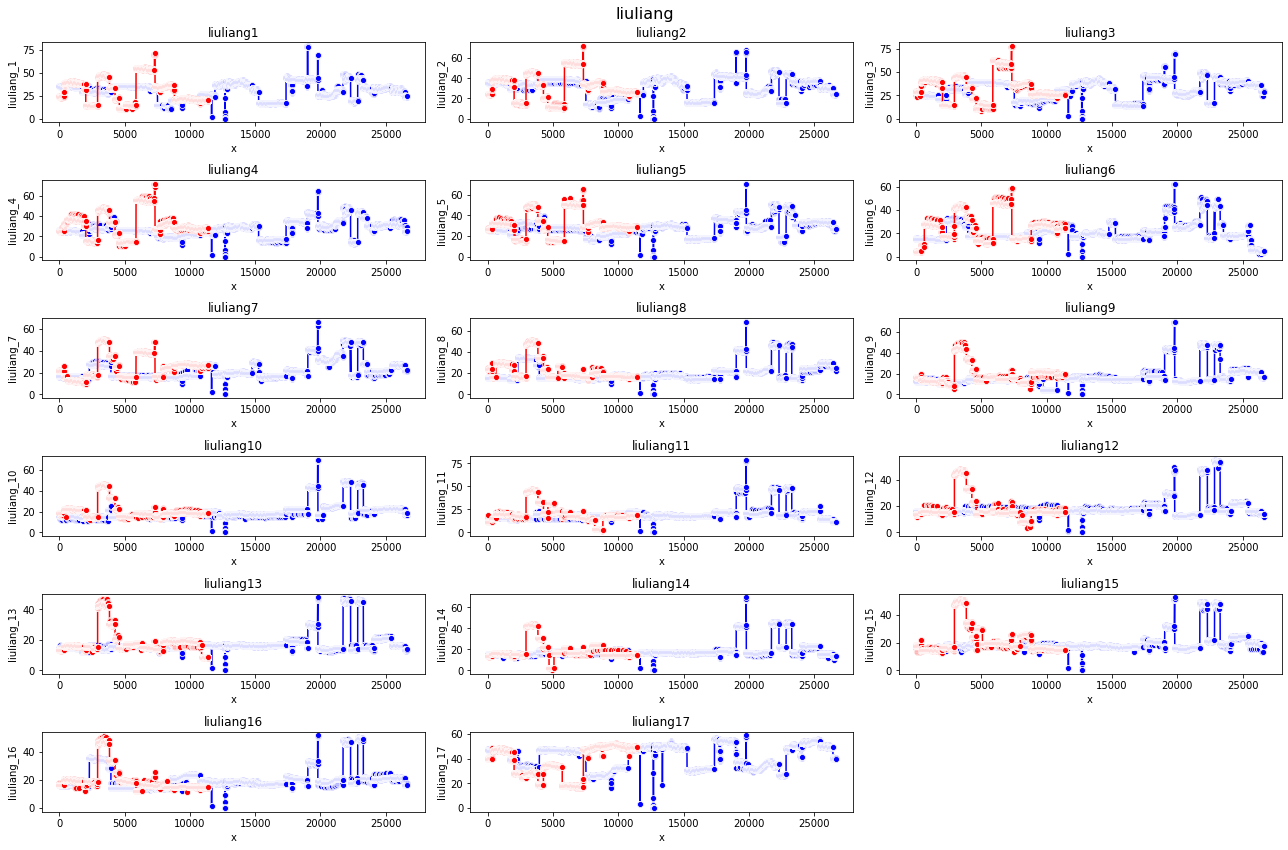
通过利用中位数进行滑动窗口滤波后得到的结果,其中红色曲线是测试集滤波后的结果。
滤波采用的代码:
def smooth_t(df, cols):
df = df.copy()
window_size = 5
for col in cols:
df[f'smoothed_{
col}'] = df[col].rolling(window=window_size, center=True).median()
outlier_threshold = 5.0
df['absolute_diff'] = abs(df[col] - df[f'smoothed_{
col}'])
outliers = df['absolute_diff'] > outlier_threshold
df.loc[outliers, col] = df.loc[outliers, f'smoothed_{
col}']
df.drop(columns=[f'smoothed_{
col}', 'absolute_diff'], inplace=True)
return df
结果:滤波后的数据在测试集上MAE并没有减少。
2. 特征工程
主要从三个方面进行:
- 流量特征:构造了一定时间范围内(一天中)的方差、均值和变异系数。其中变异系数表现较好,在树模型的特征重要性中得分高于原始的流量特征,但用该特征训练后在测试集上的表现并没有更好,该怎样保留和删除特征仍有些疑惑。
- 温度设定特征:这些特征在corr相关性中和target的线性相关性较强,但在树模型的特征重要性评价中表现很差,而且值比较平稳,不容易构建衍生特征。我尝试了构建成离散特征,分别用最多的n 个值代替所有值,同时用1,0,-1构建其前后的变化。但这些特征表现都很差。
- 接着尝试了使用全自动特征生成器openFE。效果也一般。
from openfe import OpenFE, transform, tree_to_formula
ofe = OpenFE()
features = ofe.fit(data = train_x, label = train_y, n_jobs=12) # n_jobs:指定CPU内核数
train_x_feature, test_dataset_feture = transform(train_x, test_x, features[:20], n_jobs = 12)
# 查看前20个高分特征
for feature in ofe.new_features_list[:20]:
print(tree_to_formula(feature))
3. 数据划分方式
因为是时间序列数据,直接使用train_test_split有穿越,所以使用了针对时序数据的TimeSeriesSplit,效果很差,使用了KFold表现也不如train_test_split。
4. 后处理
- Hillclimbing库 —— 用于模型融合
找到的一个用于模型融合的库,但因为目前只用了lightgbm,所以还未尝试。
!pip install hillclimbers
from hillclimbers import climb, partial
def climb_hill(
train=None,
oof_pred_df=None,
test_pred_df=None,
target=None,
objective=None,
eval_metric=None,
negative_weights=False,
precision=0.01,
plot_hill=True,
plot_hist=False
) -> np.ndarray: # Returns test predictions resulting from hill climbing
- 后处理技巧
发现的一个有意思的处理技巧,但在这个数据集上不适用,但借鉴这个思路我用来构建了温度设定特征的离散编码,虽然效果也很差。
# 1. 存储target唯一值
unique_targets = np.unique(trian['yield'])
# 2. 完成对训练和测试数据的预测
off_preds = model.prdict(X_val[features])
test_preds += model.predict(test[features]) / n_splits
# 四舍五入到最接近的唯一目标值
off_preds = [min(unique_targets, key = lambda x: abs(x-pred)) for pred in oof_preds]
test_preds = [min(unique_targets, key = lambda x: abs(x-pred)) for pred in test_preds]
学习记录3 (2023.07.30更新)
看了鱼佬的直播后收获颇丰,之前在特征筛选上花了很多工夫,后来才发现构造的特征量远远还达不到特征筛选的量。此外,在分数一直没有改进时,多从数据分析上入手。因此,这两天又仔细分析了一下数据,然后有了新的发现。
先统计了在训练集上从 2022-11-06 09:00:00 到2023-03-01 04:00:00间每个小时数据的记录情况。
数据示例如下:
2022-11-06 09:00:00,40
2022-11-06 10:00:00,47
2022-11-06 11:00:00,46
2022-11-06 12:00:00,47
2022-11-06 13:00:00,47
2022-11-06 14:00:00,48
2022-11-06 15:00:00,47
......
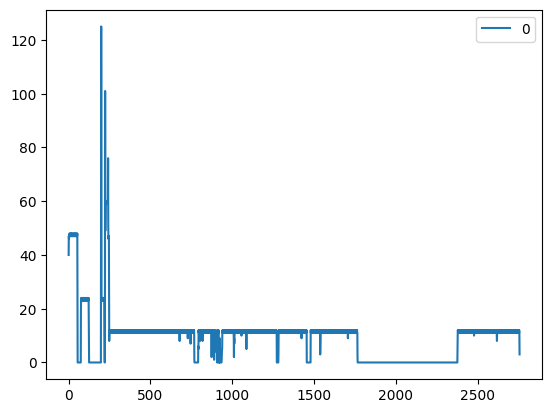
根据数据在每个小时的采样频率将训练集划分了五份。例如2022-11-7和2022-11-8的数据每小时采样了约48次,然后对数据用四步长再划分为4份,这样就得到了每小时约12次的采样。其余份的训练集进行类似的操作,使得整体的数据都保持每小时约12次采样。
这样做的目的是因为,测试集全部维持着每小时11或12次的采样频率。
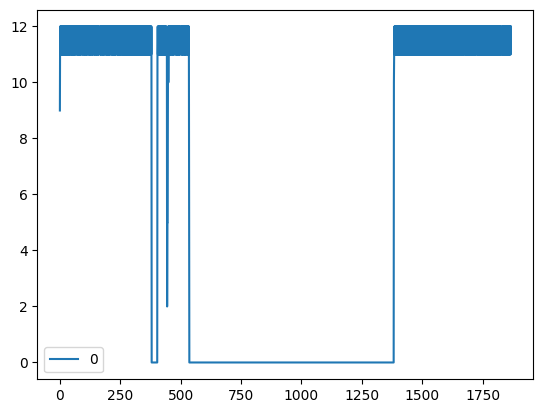
经过这样的处理后,就实现了训练集和测试集上的相等的时间步长。方便后续构建时序特征。
此外,将训练集进行拆分后也有效的避免了空缺时间的影响。
另外,手动选取验证集保证验证集和测试集分布的一致性,使得线上线下更好的 拟合。
接着利用处理后的等时间步长的数据重新构建了之前尝试的时序相关特征。并采用baseline的方法进行的简单的验证。这次换了台速度快点的机器,最后MAE7.52,反而更差了,然后我又重跑了一遍baseline,发现这次baseline变成了8.51,之前baseline的得分还是6.29。
总结:这两天的尝试在处理数据花费了太多时间,而且也不容易评估方案的好坏,感觉结果受到很多因素影响很不容易做到控制变量,整个编程过程也比较混乱,后面需要加强练习。从鱼佬直播中学习到的一些思路也还没来得及实践,之后利用最后几天再尝试一下。