实验6 数据挖掘分类入门实验
1. 实验数据
该数据集包含1439条训练数据,存放于“data-train.csv”文件;另有160条未知标签的测试数据,保存在“data-test.csv”文件中。
训练集数据共含与某种酒品质相关的11个(匿名)特征属性(f1~f11)和1个目标属性(target),具体字段如下: #data-train.csv
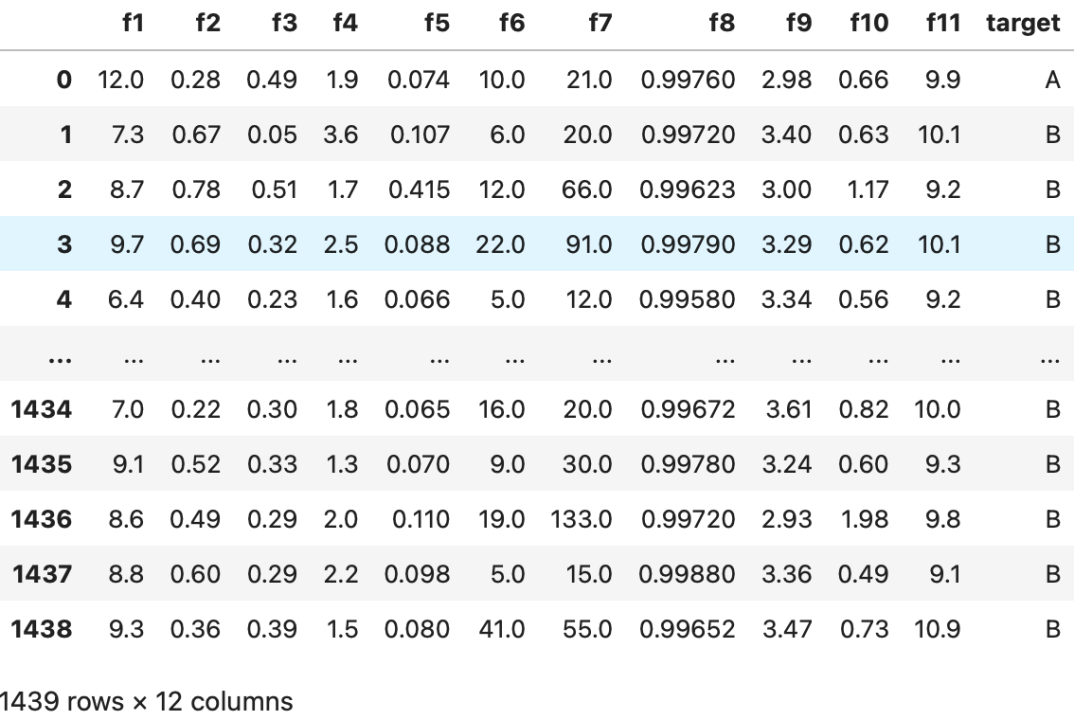
测试数据的具体字段如下: #data-test.csv
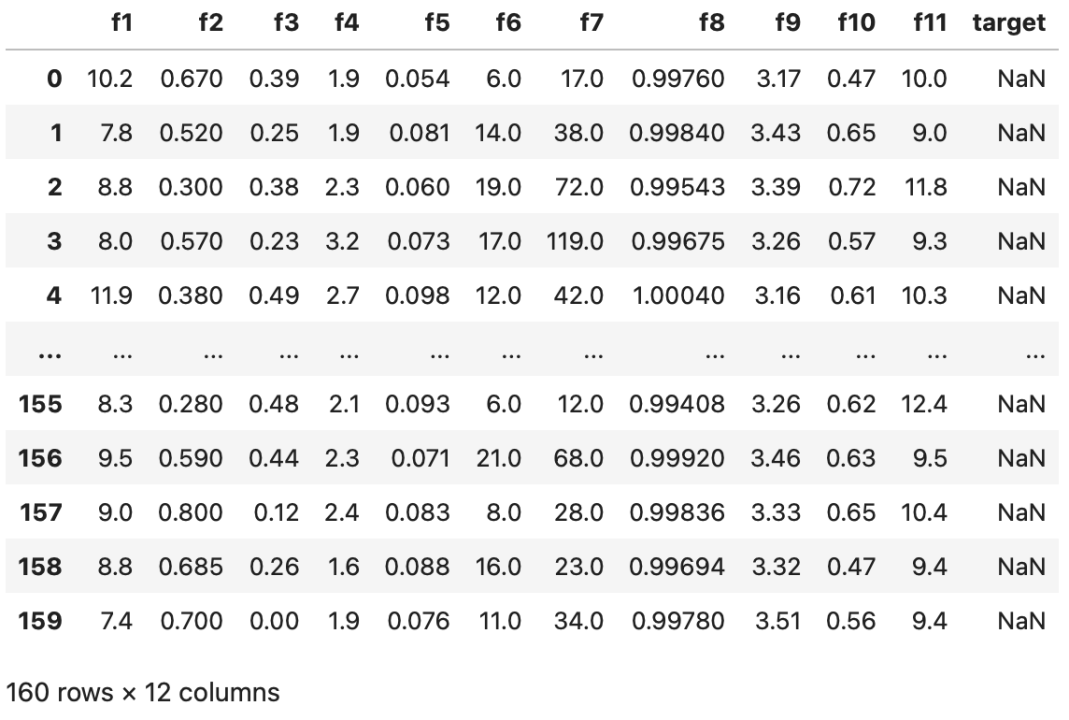
其中目标属性,即target字段未知,待建模预测。
扫描二维码关注公众号,回复:
16415239 查看本文章

2. 实验目的
本次实验的目的是利用机器学习分类算法,基于训练集构建分类器模型,进而预测测试集中全体样本的分类结果,即测试样本的target 值:A、B