Attention(注意力机制)
直白的理解:注意力机制,对于数据,我们有重要的数据和不重要的数据。在模型处理数据的过程中,我们如果只关注较为重要的数据部分,忽略不重要的部分,那训练的速度、模型的精度就会变得更好。
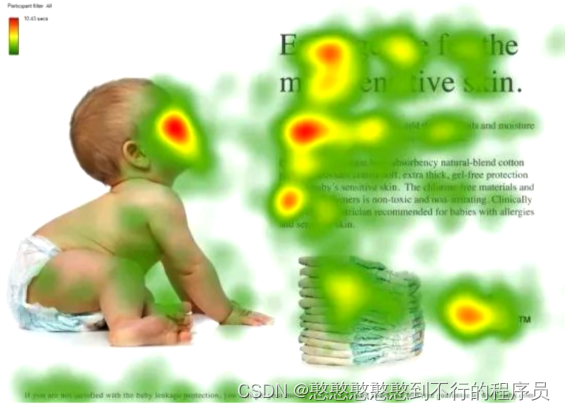
由图可知:我们作为人类,常常会聚焦于较为重要的内容上。
由此,Attention的主要目的,就是要模仿人类一样,学会聚焦重要的内容部分,查找到目标,并计算被查找目标的相似度。
计算过程
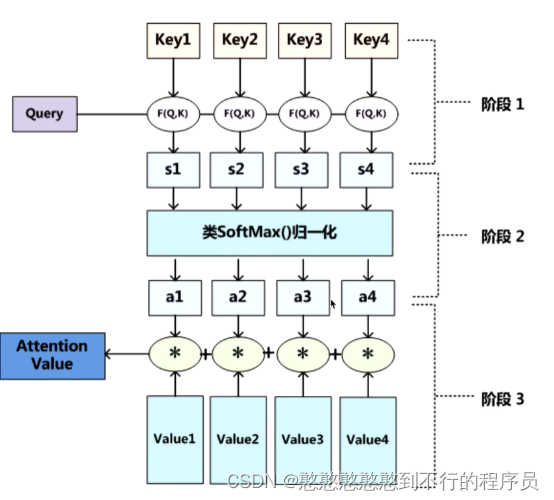
我们设立三个参数,Q,V,K。整个注意力机制的过程如下:
1.Q是最适合查找目标的
2.K是最适合接收查找的
3.V就是内容
4.Q(查找的目标), K = k 1 , k 2 . . . . . , k n K=k_1,k_2.....,k_n K=k1,k2.....,kn ,一般使用点乘Q,K,拿到Q和每一个K的相似值 Q ∗ k n = s n Q*k_n=s_n Q∗kn=sn 。
5.做一层 s o f t m a x ( s 1 , s 2 , ⋯ , s n ) = a n softmax(s_1,s_2,\cdots,s_n)=a_n softmax(s1,s2,⋯,sn)=an 得到每一个查询对象的概率。
6.计算 a n ∗ V = V ′ a_n*V=V' an∗V=V′ 事物的重要度,相似度计算,找到Q最相 似的对象。
总结出的公式为: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q ∗ K i d k ) ∗ V i Attention(Q,K,V)=softmax(\frac{Q*K_i}{\sqrt d_k})*V_i Attention(Q,K,V)=softmax(dkQ∗Ki)∗Vi
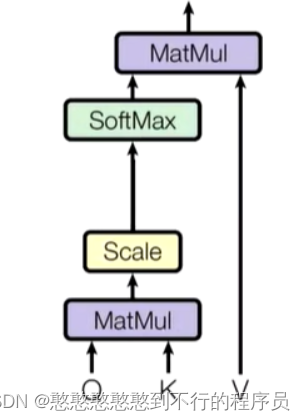
PS:为什么softmax中需要除以一个 d k \sqrt d_k dk
softmax()作为归一化的处理,当得到的概率差距较大时如(0.05,0.95),最后所点乘出的V的差距就会过大。
一般在注意力机制中,我们常常使用 512 8 \frac{512}{8} 8512 作为处理。