第4章

简答题
简答题
1.在数据预处理的过程中会根据数据的实际情况选择合适处理方法,常用的预处理操作有数据清洗、数据合并、数据重塑、数据转换等,在这几种操作中又分别含有不同的数据处理方法,例如在数据清洗过程中含有空值和缺失的检测、重复值的处理、异常值的处理等。
2.在Pandas中常用的数据合并操作有:concat()函数表示沿着一条轴将多个对象进行堆叠、merge()函数表示根据一个或多个键将不同的对象进行合并、join()方法表示根据索引或指定的列来合并数据、combine_first()方法表示填充合并数据。
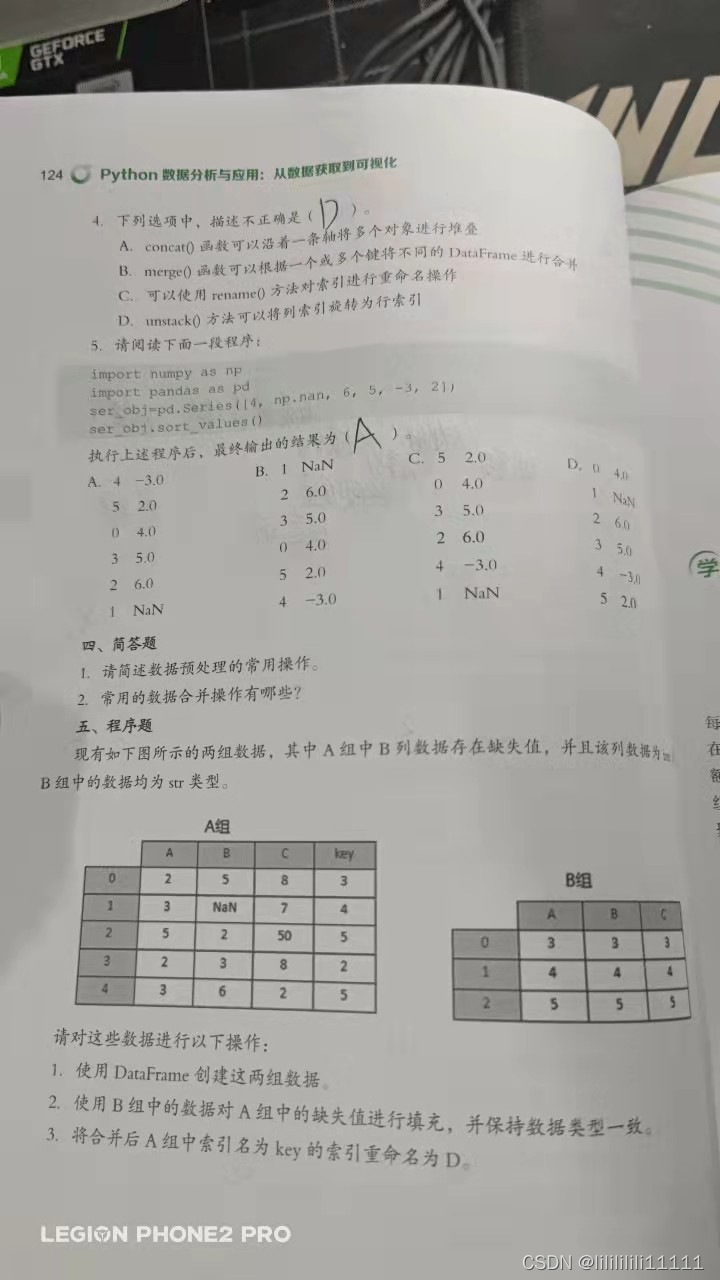
程序题
1.答案:
import pandas as pd
import numpy as np
group_a = pd.DataFrame({‘A’: [2,3,5,2,3],
'B': ['5',np.nan,'2','3','6'],
'C': [8,7,50,8,2],
'key': [3,4,5,2,5]})
group_b = pd.DataFrame({‘A’: [3,3,3],
'B': [4,4,4],
'C': [5,5,5]})
print(group_a)
print(group_b)
2.答案:
group_a = group_a.combine_first(group_b)
group_a
3.答案:
group_a.rename(columns={‘key’:‘D’})
第5章


简答题
1.分组聚合的流程一般为拆分、应用、合并。拆分是将数据集按照一定规则分成若干组;应用是对这些分组的数据进行一系列操作的过程;合并是将这些执行操作后的结果进行整合。
2.常用的分组方式主要有4种,分别为:列表或数组,列表或数组的长度需要与带分组轴的长度一致、DataFrame中某列的名称、字典或Series对象、函数。
程序题
1.答案:
import pandas as pd
studnets_data = pd.DataFrame({‘年级’:[‘大一’,‘大二’,‘大三’,
'大四','大二','大三',
'大一','大三','大四'],
'姓名':['李宏卓','李思真','张振海',
'赵鸿飞','白蓉','马腾飞',
'张晓凡','金紫萱','金烨'],
'年龄':[18,19,20,21,
19,20,18,20,21],
'身高':[175,165,178,175,
160,180,167,170,185],
'体重':[65,60,70,76,55,
70,52,53,73]})
data = studnets_data.groupby(‘年级’)
Freshman = dict([x for x in data])[‘大一’]
print(Freshman)
2.答案:
data = data.apply(max)
del data[‘年级’]
print(data)
3.答案:
Junior = dict([x for x in data])[‘大三’]
print(Freshman[‘体重’].apply(‘mean’))
print(Junior[‘体重’].apply(‘mean’))