一、PyTorch基本操作
1,导包
import torch
2,查看版本号
torch.__version__
"""
'2.0.1+cpu'
"""
3,初始化(全零)矩阵
x = torch.empty(3,2)
x
"""
tensor([[7.2868e-44, 8.1275e-44],
[6.7262e-44, 7.5670e-44],
[8.1275e-44, 6.7262e-44]])
"""
4,随机创建初始化矩阵
4.1 符合正态分布
x_1 = torch.randn(3,4)
x_1
"""
tensor([[ 0.1605, -0.9290, -0.0501, -0.0723],
[ 0.6792, 0.1977, -0.7773, 0.6927],
[ 0.7576, -1.4204, 0.1976, -2.2545]])
"""
4.2 符合均匀分布
x_2 = torch.rand(3,4)
x_2
"""
tensor([[0.5876, 0.5991, 0.9678, 0.8188],
[0.2934, 0.4345, 0.1316, 0.8469],
[0.0042, 0.3754, 0.3141, 0.8362]])
"""
5,初始化全零矩阵
x1 = torch.zeros(5,2,dtype=torch.long)
x1
"""
tensor([[0, 0],
[0, 0],
[0, 0],
[0, 0],
[0, 0]])
"""
6,初始化全一矩阵
x2 = torch.ones(3,4)
x2
"""
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
"""
7,查看矩阵大小规格
x2.size()
"""
torch.Size([3, 4])
"""
8,改变矩阵维度
y = torch.randn(3,4)
y
"""
tensor([[-1.3152, 0.2621, -0.7739, 0.1728],
[-1.3887, 1.0964, 0.7797, 2.0587],
[ 0.4726, -0.2367, 0.8845, 0.9405]])
"""
y1 = y.view(12)
y1
"""
tensor([-1.3152, 0.2621, -0.7739, 0.1728, -1.3887, 1.0964, 0.7797, 2.0587, 0.4726, -0.2367, 0.8845, 0.9405])
"""
y2 = y.view(2,6)
y2
"""
tensor([[-1.3152, 0.2621, -0.7739, 0.1728, -1.3887, 1.0964],
[ 0.7797, 2.0587, 0.4726, -0.2367, 0.8845, 0.9405]])
"""
y3 = y.view(6,-1)
y3
"""
tensor([[-1.3152, 0.2621],
[-0.7739, 0.1728],
[-1.3887, 1.0964],
[ 0.7797, 2.0587],
[ 0.4726, -0.2367],
[ 0.8845, 0.9405]])
"""
9,Numpy和Tensor格式互转
9.1 Numpy转Tensor
z1 = torch.ones(2,5)
z1
"""
tensor([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]])
"""
z2 = z1.numpy()
z2
"""
array([[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]], dtype=float32)
"""
9.2 Tensor转Numpy
import numpy as np
a1 = np.ones([2,4])
a1
"""
array([[1., 1., 1., 1.],
[1., 1., 1., 1.]])
"""
a2 = torch.from_numpy(a1)
a2
"""
tensor([[1., 1., 1., 1.],
[1., 1., 1., 1.]], dtype=torch.float64)
"""
10,Tensor常见形式
import torch
from torch import tensor
10.1 scalar
只要是个数或者单一的值,就成为scalar
x = tensor(22)
x
"""
tensor(22)
"""
x.dim() # 0
2*x # tensor(44)
x.item() # 22
10.2 vector
vector向量,表示某一个特征。例如:[年龄,身高,体重],[25,178,60]
向量不是一个值,而实多个值的集合
我的理解是:多个scalar构成了vector
y = tensor([25,178,60])
y
"""
tensor([ 25, 178, 60])
"""
y.dim() # 1
y.size() # torch.Size([3])
10.3 matrix
matrix矩阵,通常是多个维度的。
例如:有三个学生,张三、李四、王二麻子,他们也都有各自的特征([年龄,身高,体重]),[[25,178,60], [22,180,62], [21,177,61]],组合到一块就成了matrix矩阵。
我的理解是:多个vector构成了matrix

m = tensor([[1,2,3], [2,1,3], [3,1,2]])
m
"""
tensor([[1, 2, 3],
[2, 1, 3],
[3, 1, 2]])
"""
m.matmul(m)
"""
tensor([[14, 7, 15],
[13, 8, 15],
[11, 9, 16]])
"""
tensor([1,0,1]).matmul(m)
"""
tensor([4, 3, 5])
"""
tensor([1,2,1]).matmul(m)
"""
tensor([ 8, 5, 11])
"""
m*m
"""
tensor([[1, 4, 9],
[4, 1, 9],
[9, 1, 4]])
"""
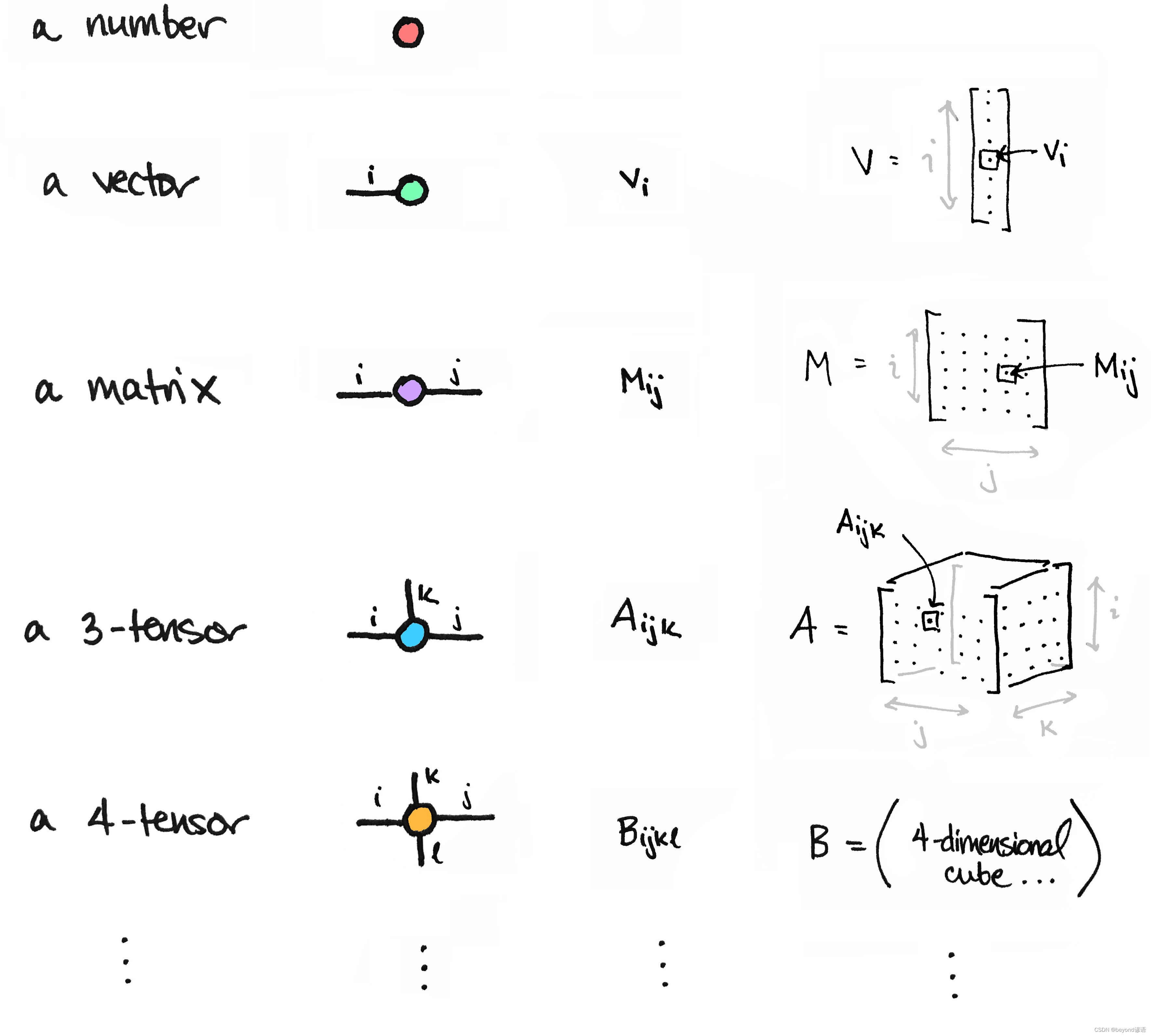
10.4 n-dimensional tensor
pytorch在处理图像中常用到[N,C,H,W]四维tensor进行处理
N:每一个batch中的图像数量
C:每一张图像中的通道数
H:每一张图像垂直维度的像素数个数(高)
W:每一张图像水平维度的像素数个数(宽)
11,Model Zoo
调用别人训练好的网络架构以及权重参数,最终通过一行代码就可以搞定。
方便懒人进行调用,Pytorch中成为hub模块
Github上相关链接
pytorch官网API链接
例如,打开pytorch官网中的随便一个项目,复制粘贴即可运行,下载相关权重参数文件的时候需要科学上网。
二、autograd自动求导机制
案例一:反向传播求导,函数表达式为y = w*x*x + b*x + c,其中w=2,x=3,b=5,c=4

import torch
w = torch.tensor(2, dtype = torch.float32, requires_grad = True)
x = torch.tensor(3, dtype = torch.float32, requires_grad = True)
b = torch.tensor(5, dtype = torch.float32, requires_grad = True)
c = torch.tensor(4, dtype = torch.float32, requires_grad = True)
w,x,b,c
"""
(tensor(2., requires_grad=True),
tensor(3., requires_grad=True),
tensor(5., requires_grad=True),
tensor(4., requires_grad=True))
"""
y = w * x**2 + b * x + c
y
"""
tensor(37., grad_fn=<AddBackward0>)
"""
y.backward() #反向传播
w.grad
"""
tensor(9.)
"""
x.grad
"""
tensor(17.)
"""
b.grad
"""
tensor(3.)
"""
c.grad
"""
tensor(1.)
"""
三、最基础的模型训练完整步骤演示
需求:监督学习,训练模型符合y = 2*x + 5
import torch
import numpy as np
1,标签数据准备
① x样本
Ⅰ、0-9,10个数
这里为了简单起见,x样本为0-9,10个数,用列表存储
x = [i for i in range(10)]
x # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Ⅱ、转换成array格式方便操作
x_arr = np.array(x,dtype=np.float32)
x_arr # array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.], dtype=float32)
Ⅲ、转换成一列数据,方便后续操作
x_train = x_arr.reshape(-1,1)
x_train
"""
array([[0.],
[1.],
[2.],
[3.],
[4.],
[5.],
[6.],
[7.],
[8.],
[9.]], dtype=float32)
"""
x_train.shape # (10, 1)
② y样本
Ⅰ、通过函数y=2*x+5生成对应的结果y
y = [2*x+5 for x in range(10)]
y # [5, 7, 9, 11, 13, 15, 17, 19, 21, 23]
Ⅱ、转换成array格式方便操作
y_arr = np.array(y,dtype=np.float32)
y_arr # array([ 5., 7., 9., 11., 13., 15., 17., 19., 21., 23.], dtype=float32)
Ⅲ、转换成一列数据,方便后续操作
y_train = y_arr.reshape(-1,1)
y_train
"""
array([[ 5.],
[ 7.],
[ 9.],
[11.],
[13.],
[15.],
[17.],
[19.],
[21.],
[23.]], dtype=float32)
"""
y_train.shape # (10, 1)
2,设计模型
这里使用一个最简单的两层线性层进行搭建模型,训练的数据都是单一一个
第一层输入维度为1,输出维度为2
第二层输入维度是2,输出维度是1
class Linear_yy(torch.nn.Module):
def __init__(self,in_dim,media_dim,out_dim):
super(Linear_yy,self).__init__()
self.linear_1 = torch.nn.Linear(in_dim,media_dim)
self.linear_2 = torch.nn.Linear(media_dim,out_dim)
def forward(self,x):
x = self.linear_1(x)
x = self.linear_2(x)
return x
in_dim = 1
media_dim = 2
out_dim = 1
model = Linear_yy(in_dim=in_dim,media_dim=media_dim,out_dim=out_dim)
model
"""
Linear_yy(
(linear_1): Linear(in_features=1, out_features=2, bias=True)
(linear_2): Linear(in_features=2, out_features=1, bias=True)
)
"""
3,指定epoch、学习率、优化器、损失函数等参数
epochs = 1000 #epoch
learning_rate = 0.0001 # 学习率
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate) # 优化器选择Adam
loss_faction = torch.nn.MSELoss() # 损失函数选择MSE
4,训练模型
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = loss_faction(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0: # 每50次输出一次损失值
print('epoch {}, loss {}'.format(epoch, loss.item()))
5,模型预测
predicted = model(torch.from_numpy(x_train).requires_grad_()).data.numpy()
predicted
"""
array([[0.6956282 ],
[0.75930536],
[0.82298255],
[0.88665974],
[0.9503369 ],
[1.014014 ],
[1.0776913 ],
[1.1413685 ],
[1.2050457 ],
[1.2687228 ]], dtype=float32)
"""
6,模型权重保存
torch.save(model.state_dict(), 'model.pth')

7,模型权重加载
模型权重加载一般用于模型训练中断,需要使用上次的权重参数接着训练,此时就需要先保存模型,然后再加载权重参数即可
model.load_state_dict(torch.load('model.pth'))
8,完整代码(CPU)
当然,这只是训练模型的完整代码,最后的测试和保存模型权重,参考5,6,7即可
import torch
import torch.nn as nn
import numpy as np
class Linear_yy(torch.nn.Module):
def __init__(self,in_dim,media_dim,out_dim):
super(Linear_yy,self).__init__()
self.linear_1 = torch.nn.Linear(in_dim,media_dim)
self.linear_2 = torch.nn.Linear(media_dim,out_dim)
def forward(self,x):
x = self.linear_1(x)
x = self.linear_2(x)
return x
in_dim = 1
media_dim = 2
out_dim = 1
model = Linear_yy(in_dim=in_dim,media_dim=media_dim,out_dim=out_dim)
epochs = 1000
learning_rate = 0.0001
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
loss_faction = torch.nn.MSELoss()
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train)
labels = torch.from_numpy(y_train)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = loss_faction(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))
9,完整代码(GPU)
使用GPU训练只需要把训练数据、模型放入GPU中即可
指定是否使用GPU训练模型
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
模型放入GPU中
model.to(device)
数据放入GPU中
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
import torch
import torch.nn as nn
import numpy as np
class Linear_yy(torch.nn.Module):
def __init__(self,in_dim,media_dim,out_dim):
super(Linear_yy,self).__init__()
self.linear_1 = torch.nn.Linear(in_dim,media_dim)
self.linear_2 = torch.nn.Linear(media_dim,out_dim)
def forward(self,x):
x = self.linear_1(x)
x = self.linear_2(x)
return x
in_dim = 1
media_dim = 2
out_dim = 1
model = Linear_yy(in_dim=in_dim,media_dim=media_dim,out_dim=out_dim)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
epochs = 1000
learning_rate = 0.0001
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
loss_faction = torch.nn.MSELoss()
for epoch in range(epochs):
epoch += 1
# 注意转行成tensor
inputs = torch.from_numpy(x_train).to(device)
labels = torch.from_numpy(y_train).to(device)
# 梯度要清零每一次迭代
optimizer.zero_grad()
# 前向传播
outputs = model(inputs)
# 计算损失
loss = loss_faction(outputs, labels)
# 返向传播
loss.backward()
# 更新权重参数
optimizer.step()
if epoch % 50 == 0:
print('epoch {}, loss {}'.format(epoch, loss.item()))