表结构
employee

department
CREATE TABLE `department` (
`id` int(0) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
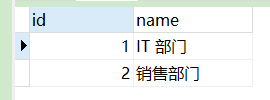
INSERT INTO `department` VALUES (1, 'IT 部门');
INSERT INTO `department` VALUES (2, '销售部门');
CREATE TABLE `employee` (
`id` int(0) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT NULL,
`salary` int(0) NULL DEFAULT NULL,
`departmentId` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic;
INSERT INTO `employee` VALUES (1, 'joe', 70000, 1);
INSERT INTO `employee` VALUES (2, 'jim', 90000, 2);
INSERT INTO `employee` VALUES (3, 'heney', 80000, 2);
INSERT INTO `employee` VALUES (4, 'sam', 70000, 2);
INSERT INTO `employee` VALUES (5, 'kity', 60000, 1);
INSERT INTO `employee` VALUES (6, 'hellen', 68000, 1);
INSERT INTO `employee` VALUES (7, 'hym', 68000, 1);
INSERT INTO `employee` VALUES (8, 'liliy', 72000, 2);
1.如果是只查询第一名,则可以用最简单的办法
查询各个部门第一名的部门Id和薪资
1.查询各个部门第一名的部门Id和薪资
SELECT departmentId,MAX(salary) departmentId FROM employee GROUP BY departmentId;
+--------------+--------------+
| departmentId | departmentId |
+--------------+--------------+
| 1 | 70000 |
| 2 | 90000 |
+--------------+--------------+
2.使用in
SELECT * FROM employee JOIN department on employee.departmentId = department.id
WHERE #双条件in
(employee.departmentId,employee.salary)
in #各部门第一名
(SELECT departmentId,MAX(salary) departmentId FROM employee GROUP BY departmentId) ;
+----+------+--------+--------------+----+--------------+
| id | name | salary | departmentId | id | name |
+----+------+--------+--------------+----+--------------+
| 1 | joe | 70000 | 1 | 1 | IT 部门 |
| 2 | jim | 90000 | 2 | 2 | 销售部门 |
+----+------+--------+--------------+----+--------------+
2.查询前三名
1.先介绍三个函数,mysql中的排名函数rank()、dense_rank()、row_number()
rank() 排序为1,2,2,4 。(并列第2名中有一个是第三名,因此,第三名则跳过。下图中ranks为排
名,详见id=6、7、5三条数据的ranks)
partition by 在函数排序中相当于group by
SELECT *,rank() over(partition by departmentId ORDER BY salary desc) ranks FROM employee;
+----+--------+--------+--------------+-------+
| id | name | salary | departmentId | ranks |
+----+--------+--------+--------------+-------+
| 1 | joe | 70000 | 1 | 1 |
| 6 | hellen | 68000 | 1 | 2 |
| 7 | hym | 68000 | 1 | 2 |
| 5 | kity | 60000 | 1 | 4 |
| 2 | jim | 90000 | 2 | 1 |
| 3 | heney | 80000 | 2 | 2 |
| 8 | liliy | 72000 | 2 | 3 |
| 4 | sam | 70000 | 2 | 4 |
+----+--------+--------+--------------+-------+
row_number() 排序为1,2,3,4 根据行号来排序
SELECT *,row_number() over(partition by departmentId ORDER BY salary desc) ranks FROM employee;
| id | name | salary | departmentId | ranks |
+----+--------+--------+--------------+-------+
| 1 | joe | 70000 | 1 | 1 |
| 6 | hellen | 68000 | 1 | 2 |
| 7 | hym | 68000 | 1 | 3 |
| 5 | kity | 60000 | 1 | 4 |
| 2 | jim | 90000 | 2 | 1 |
| 3 | heney | 80000 | 2 | 2 |
| 8 | liliy | 72000 | 2 | 3 |
| 4 | sam | 70000 | 2 | 4 |
dense_rank() 排序为1,2,2,3 。(dense 英语中指“稠密的、密集的”。dense_rank()是的排序数字是连续的、不间断)
SELECT *,dense_rank() over(partition by departmentId ORDER BY salary desc) ranks FROM employee;
| id | name | salary | departmentId | ranks |
+----+--------+--------+--------------+-------+
| 1 | joe | 70000 | 1 | 1 |
| 6 | hellen | 68000 | 1 | 2 |
| 7 | hym | 68000 | 1 | 2 |
| 5 | kity | 60000 | 1 | 3 |
| 2 | jim | 90000 | 2 | 1 |
| 3 | heney | 80000 | 2 | 2 |
| 8 | liliy | 72000 | 2 | 3 |
| 4 | sam | 70000 | 2 | 4 |
+----+--------+--------+--------------+-------+
2.使用mysql函数查询出排名前三名的员工
1.先查询出薪资排名
SELECT *,rank() over(partition by departmentId ORDER BY salary desc) ranks FROM employee;
| id | name | salary | departmentId | ranks |
+----+--------+--------+--------------+-------+
| 1 | joe | 70000 | 1 | 1 |
| 6 | hellen | 68000 | 1 | 2 |
| 7 | hym | 68000 | 1 | 2 |
| 5 | kity | 60000 | 1 | 4 |
| 2 | jim | 90000 | 2 | 1 |
| 3 | heney | 80000 | 2 | 2 |
| 8 | liliy | 72000 | 2 | 3 |
| 4 | sam | 70000 | 2 | 4 |
2.再根据已查出的薪资排名,筛选出前三名员工
SELECT * FROM department
JOIN (
SELECT *,rank() over(partition by departmentId ORDER BY salary desc) ranks FROM employee) a
on department.id = a.departmentId WHERE a.ranks <=3 ;
| id | name | id | name | salary | departmentId | ranks |
+----+--------------+----+--------+--------+--------------+-------+
| 1 | IT 部门 | 1 | joe | 70000 | 1 | 1 |
| 1 | IT 部门 | 6 | hellen | 68000 | 1 | 2 |
| 1 | IT 部门 | 7 | hym | 68000 | 1 | 2 |
| 2 | 销售部门 | 2 | jim | 90000 | 2 | 1 |
| 2 | 销售部门 | 3 | heney | 80000 | 2 | 2 |
| 2 | 销售部门 | 8 | liliy | 72000 | 2 | 3 |
3.使用传统办法查询前三名
1.查询出每个薪资数,比其它薪资数高的数量
select * from employee a,employee b where a.departmentId=b.departmentId and a.salary<b.salary;这条语句的意思,翻译一下就是,
比70000低的薪资有3条记录
比68000低的薪资有2条记录
。。。。。为啥没得1条记录,因为有两个68000
比60000低的薪资有0条记录

select * from employee a JOIN department ON a.departmentId = department.id
where (
select count(1) from employee where a.departmentId=departmentId and a.salary<salary) <3
order by a.departmentId, a.salary desc;
# where中select count(1) from employee where a.departmentId=departmentId and a.salary<salary) <3
整体查询时a.salary<salary 的意思是,employee的薪资比a中的高(注意:和之前的单独查询是意思不一样哦)
那么
当a中是70000是,count出来薪资比它高的数量是0条,小于3条 满足
当a中是68000是,count出来薪资比它高的数量是1条,小于3条 满足
当a中是60000是,count出来薪资比它高的数量是3条,等于3条 不满足
| id | name | salary | departmentId | id | name |
+----+--------+--------+--------------+----+--------------+
| 1 | joe | 70000 | 1 | 1 | IT 部门 |
| 6 | hellen | 68000 | 1 | 1 | IT 部门 |
| 7 | hym | 68000 | 1 | 1 | IT 部门 |
| 2 | jim | 90000 | 2 | 2 | 销售部门 |
| 3 | heney | 80000 | 2 | 2 | 销售部门 |
| 8 | liliy | 72000 | 2 | 2 | 销售部门 |