序言
引用百度百科上的文字,hash 值一般是指将任意长度的输入通过散列函数转换成固定长度输出的值,hash函数一般是指散列函数。而java 中基于此产生了hashMap数据类型。那么redis中的hash数据类型是指什么?是否和java的hashMap有相似之处?
什么是redis的Hash类型?
Redis 的hash类型组成:key { field1: value1, field2: value2, field3: value3 ….}
Redis的Hash类型实现结构和java中的hashMap一样都是链表数组,以键值对的形式进行存储,又可以和java中的类进行类比以便于理解。Key为类名,field 为成员变量名称,value 为成员变量的值。例如:当我们想要存储一个用户的购物车列表时,我们可以设置key为用户id,field 为商品id,value为商品数量,由此可以形成一个小型的购物车存储类型。
Redis的hash类型结构
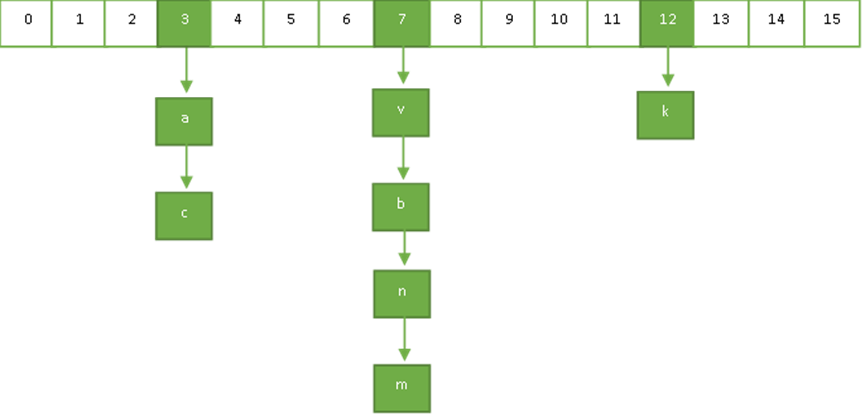
先来看一下java 的hashmap数据类型,该存储方式如下:
- 映射存储:根据key使用hash映射函数获取hash表中的位置,如果该位置上存在值就以链表的形式进行连接,如图所示。一开始是以链表形式存储,当链表长度为8时转换成红黑树进行存储以提高查找、存储速度。
Ps: 为何是8? 这个是经过红黑树的平均查找长度(log(n))和链表平均查找长度(n/2)权衡后得到的值,即log(n) = n/2 - Hash扩容:hashMap中有个装填因子,该因子一般为0.75,还有一个初始长度为16,它的意思是如果hash表中至少有12 (16*0.75)个位置上有数据了,那么就要进行扩容。扩容的方式较为复杂,以jdk1.7为例:new一个hashMap对象时会初始化数组,其容量变为不小于指定容量的2的幂数。然后根据装载因子确定阈值。如果不是第一次put,则新数组容量=旧数组容量 * 2, 新阈值 = 新数组容量 * 装载因子。
详情请见程序猿成长之路之 hashmap。
再来看一下Redis的hash数据类型, - 映射存储:该存储方式与hashmap类似都是以“数组 + 链表”的形式存储数据。当hash数组上的数据产生碰撞时,会将碰撞元素以链表形式进行连接。
- Hash扩容:java jdk1.7版本 在进行扩容时会有一步将原来数组中的数据集放到新数组的操作,在这里就要涉及到rehash函数,详情请见程序猿成长之路之 hashmap。 但是当数据集数量很大时,rehash会是个耗时的操作,可能会出现堵塞。因此redis需要重新设计扩容机制——渐进式rehash。
为什么叫渐进式rehash?和普通的rehash一次全部完成不同,渐进式rehash是分多次渐进完成的。这样的好处在于hash结构中数据量很大的情况下避免服务堵塞。
触发rehash的条件: - 扩容
a) redis目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子(哈希表已保存节点数量 / 哈希表大小)大于等于 1。
b) redis目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且哈希表的负载因子大于等于 5。
注意:如果在执行BGSAVE 命令或者 BGREWRITEAOF 命令时执行扩容会导致内存页面的过多分离。 - 收缩(负载因子小于0.1)
渐进式rehash原理:
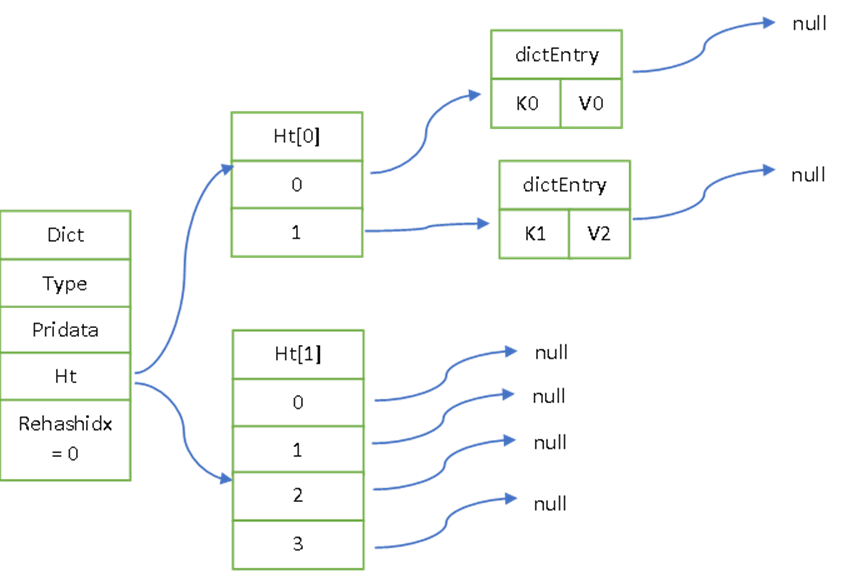
1、 渐进式rehash会分配新的空间,大小为ht[0](原hash结构)的容量的两倍【注意rehash伴随着扩容】,这样就能保存新旧两个hash结构,分别记做ht[0]和ht[1],ht[0]为旧的hash结构,ht[1]为新的hash结构。
2、 设置一个下标计数器rehashidx,初始化为0,准备进行rehash操作。如下图
3、 每次进行redis增删改查操作时,会顺带将ht[0] 中rehashinx索引里的链表上的所有数据都迁移到 ht[1] 表中的ht[0] .size + rehashinx 的位置,详情请见hashmap扩容机制。然后rehashidx的值加一, 指向下一个要迁移的链表。如下图所示。此外,当指令空闲时redis还会有定时任务实现字典的自动搬迁。
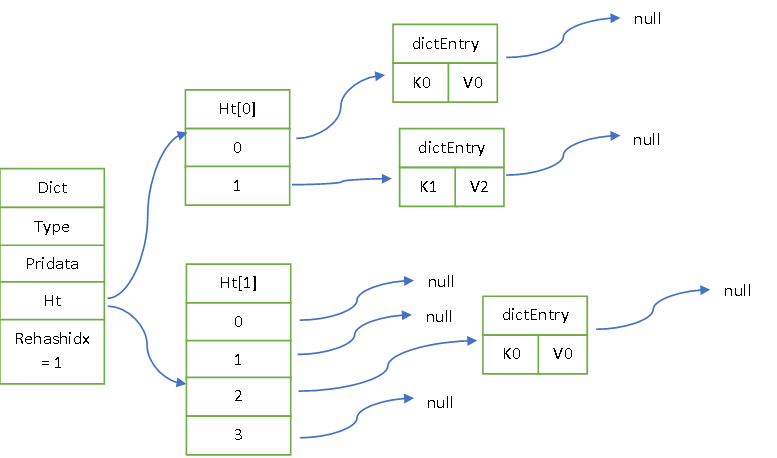
4、 当rehashidx == ht[0].size 时,说明ht[0]中的全部数据已经被迁移到了ht[1],这时候将rehashidx设置为-1。
redis在渐进式rehash过程中的增删改查:
- 增加数据:直接在ht[1]中增加数据,避免了ht[0]中增加数据后不能及时迁移到ht[1]中的问题
- 删除、更新和查询:字典的删除、查找、更新等操作会在两个哈希表上进行。先在ht[0]中查询如果没查到就在ht[1]中查询。
Hash数据结构优缺点
优点:
- 便于存储结构化的数据,不用像string类型一样先要序列化整个对象再存储,适合对象存储。
缺点: - 相比于string类型而言,存储开销更大。
常见的hash命令
- Hset key field value //存储结构化数据
- Hmset key field1 value1【field2 value2 …】 //存储结构化数据
- Hget key field // 获取某一结构化数据中的某一属性值
- Hgetall key // 获取某一结构化数据中的所有属性+属性值
- Hlen key // 获取长度
redis安装
https://blog.csdn.net/qq_31236027/article/details/121879741
redis介绍
https://blog.csdn.net/qq_31236027/article/details/121879604
redis 数据结构简介
https://blog.csdn.net/qq_31236027/article/details/121894713
redis数据结构之string类型介绍
https://blog.csdn.net/qq_31236027/article/details/122016881?spm=1001.2014.3001.5501