笔记@MySQL——————备份实验:mysqldump
其他
2018-06-19 19:25:11
阅读次数: 2
mysqldump简单的备份,用的是root身份,用户、密码省略
#mysqldump (-uroot -p111111) 数据库D
上面的命令实际是把整个数据库D,查询了一遍,在屏幕上显示一遍。
#mysqldump 数据库D > D.sql
把查询数据库D的结果存储到.sql后缀的文件里,
xxx.sql整个文件里,存储的内容是SQL语句,比如:
如果存在表1,就删除表1
创建表1,并加写锁
插入表1的内容
接锁,
如果存在表2,就删除表2
创建表2,并加锁
插入表2 的内容
解锁
依次操作……
这样操作存在漏洞,如果表内容大,表与表操作存在时间差,在实际生产中,无法确保数据时间统一,会存在错误,
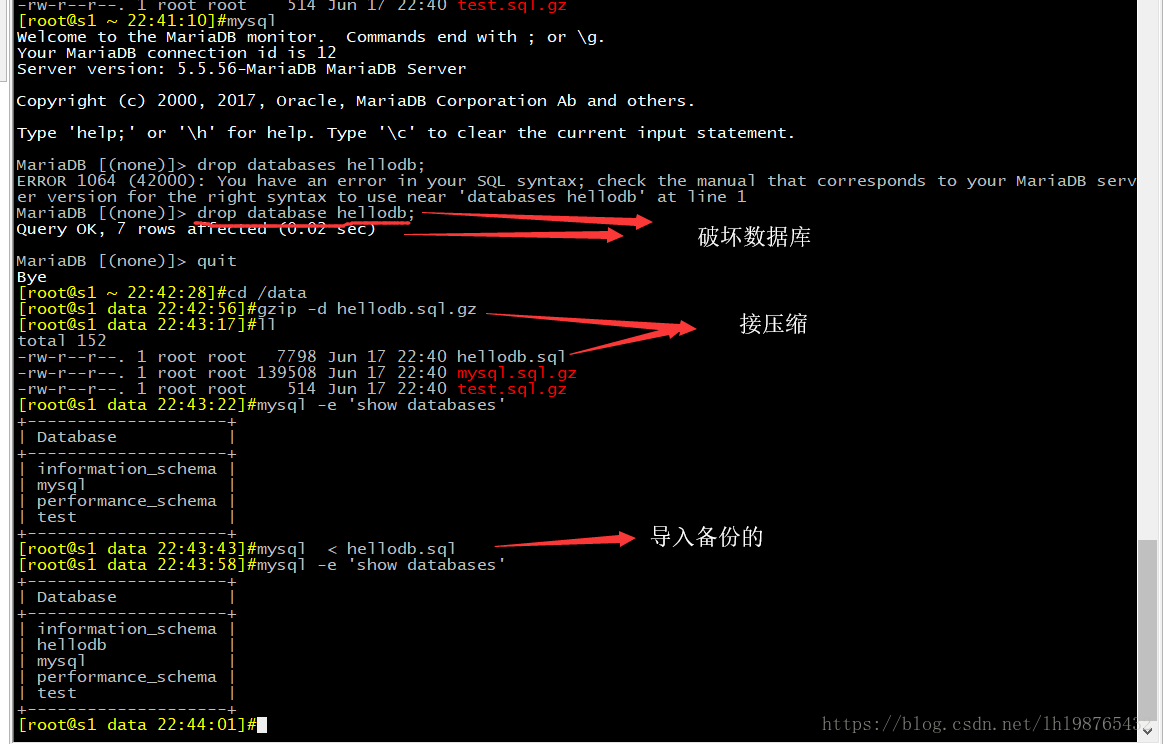
在上面的命令里不存在创建数据库的命令,如果后期操作没有这个数据库,直接操作会报错,原来的数据库被破坏,无法得知,就无法直接操作,所以要把xx.sql文件定向到一个数据库里,
#mysql 库名 < /d/xx.sql ,如果没有原数据库要指定一个数据库
挑表备份
#mysqldump database名 table名 > /d/xxx.sql
加-B选项,
#mysqldump -B database名 (db名...) > /d/xxB.sql
加-B选项就会把对应数据库的定义结构备份到xxB.sql里
加载xxB.sql文件可以直接操作,不用指定数据库
#mysql < /d/xxB.sql
mysqldump 的常用选项
-A
-B
-E ,--events:把调度任务,计划任务也备份下来
-R, --routines:把存储过程中可执行的备份下来,比如函数、存储过程
一般情况:函数,用户数据等都放在mysql里,把mysql备份,
备份加压缩
#mysqldump -A |gzip > /d/xxx.sql.gz
解压缩。会把压缩文件解到当前文件夹里,如果有同名的要移走再解压缩
#gzip -d xxx.sql.gz
把解压后的xxx.sql文件导入mysql就可以
#mysql < xxx.sql
#mysql -e 'show databases'
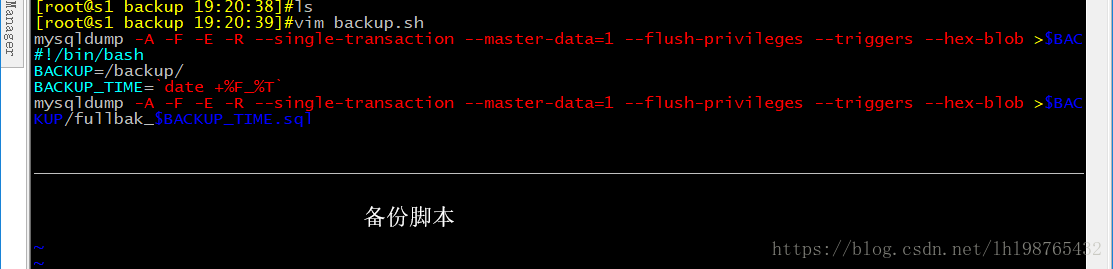
写脚本:分库备份
先把库名取出,用mysqldump -B 取出的库名 ,放到循环里
不用循环,写脚本取备份

还缺-uroot -p111

也可以生成带时间的。
--master-data【=#】:此选项必须开启二进制日志,#为1或2
1:所备份的数据之前加一条记录为change master to 语句,非注释,不指定#,默认为1
2:记录为注释的change master to语句
此选项会自动关闭--lock-tables功能,自动打开--lock-all-tables功能(除非开启--single-transaction)
mysqldump的常见选项:
-F, --flush-logs :备份前滚动日志,锁定表完成后,执行flush logs命令,生成新的二进制日志文件,配合-A 或 -B 选项时,会导致刷新多次数据库。建议在同一时刻执行转储和日志刷新,可通过和--single-transaction或-x,--master-data 一起使用实现,此时只刷新一次日志
--compact 去掉注释,适合调试,生产不使用
-d, --no-data 只备份表结构
-t, --no-create-info 只备份数据,不备份create table
-n,--no-create-db 不备份create database,可被-A或-B覆盖
--flush-privileges 备份mysql或相关时需要使用
-f, --force 忽略SQL错误,继续执行
--hex-blob 使用十六进制符号转储二进制列(例如,“abc”变为0x616263),受影响的数据类型包括BINARY, VARBINARY,BLOB,BIT
-q, --quick 不缓存查询,直接输出,加快备份速度
,

。
转载自blog.csdn.net/lhl98765432/article/details/80721151