Lab1缓冲池管理器
概览
实验的目标系统 BusTub 是一个面向磁盘的 DBMS,但磁盘上的数据不支持字节粒度的访问。这就需要一个管理页的中间层,但 Andy Pavlo 教授坚持不使用 mmap 将页管理权力让渡给操作系统,因此实验一 的目标便在于主动管理磁盘中的页(page)在内存中的缓存,从而,最小化磁盘访问次数(时间上)、最大化相关数据连续(空间上)。
该实验可以分解为相对独立的两个子任务:
-
维护替换策略的: LRU replacement policy
-
管理缓冲池的: buffer pool manager
两个组件都要求线程安全。
本文首先从基本概念、核心数据流总体分析下实验内容,然后分别对两个子任务进行梳理。
实验分析
刚开始写实验代码的时候,感觉细节很多,实现时很容易丢三落四。但随着实现和思考的深入,渐渐摸清了全貌,发现只要明确几个基本概念和核心数据流 ,便能够提纲挈领 。
基本概念
buffer pool 的操作的基本单位为一段逻辑连续的字节数组,在磁盘上表现为页(page) ,有唯一的标识 page_id ;在内存中表现为帧(frame) ,有唯一的标识 frame_id 。为了记下哪些 frame 存的哪些 page,需要使用一个页表(page table) 。
下边行文可能会混用 page 和 frame,因为这两个概念都是 buffer pool 管理数据的基本单位 ,一般为 4k,其区别如下:
-
page id 是这一段单位数据的全局标识,而 frame id 只是在内存池(frame 数组)中索引某个 page 下标
-
page 在文件系统中是一段逻辑连续的字节数组;在内存中,我们会给其附加一些元信息:
pin_count_,is_dirty_
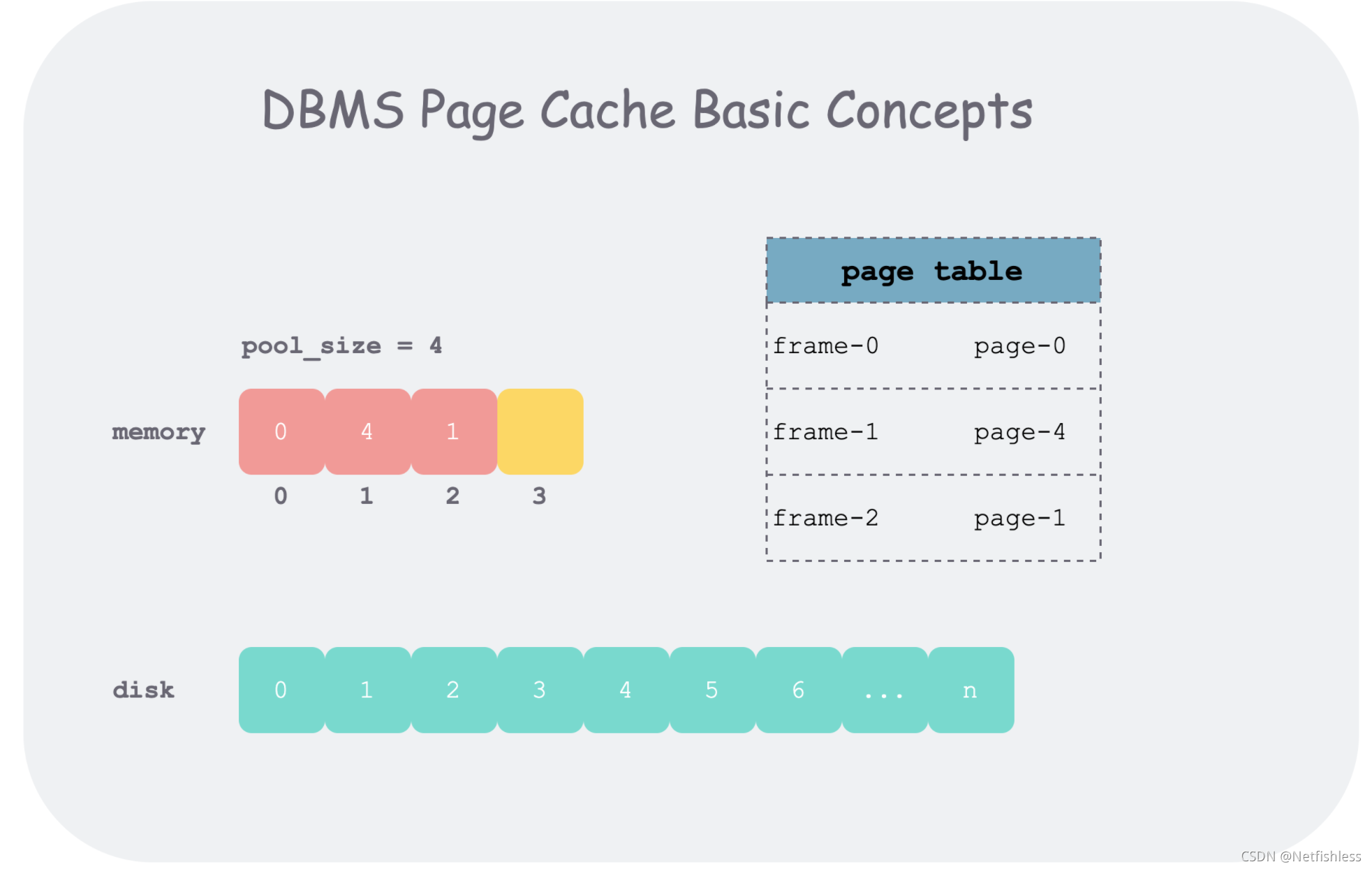
而管理帧的内存池大小一般来说是远小于磁盘的,因此在内存池满了后,再从磁盘加载新的页到内存池,需要某种替换策略(replacer)将一些不再使用的页踢出内存池以腾出空间。
CPU对内存中的数据进行操作时,传入参数为
page id。磁盘写回脏页时,传入参数也为page id。而frame id只是在内存池中索引某个page的下标。
核心数据流
先说结论,buffer pool manager 的实现核心 ,在于对内存池中所有 frame 的状态的管理。因此,如果我们能梳理出 frame 的状态机,便可以把握好核心数据流。
buffer pool 维护了一个 frame 数组,每个 frame 有三种状态:
-
free :初始状态,没有存放任何 page
-
pinned :存放了 thread 正在使用的 page
-
unpinned :存放了 page,但 page 已经不再为任何 thread 所使用
而待实现函数:
FetchPageImpl(page_id)
NewPageImpl(page_id)
UnpinPageImpl(page_id, is_dirty)
DeletePageImpl(page_id)
便是驱动状态机中上述状态发生改变的动作(action),状态机如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OF1UkhsS-1635842055915)(https://i.loli.net/2021/02/19/VOH78FybK96IcSq.png)]](https://img-blog.csdnimg.cn/8583664076a74443919cd224ecdded46.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATmV0ZmlzaGxlc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
对应到实现时数据结构上:
-
保存 page 数据的 frame 数组为
pages_ -
所有 free frame 的索引(frame_id)保存在
free_list_中 -
所有 unpinned frame 的索引保存在
replacer_中 -
所有 pinned frame 索引和 unpinned frame 的索引 保存在
page_table_中,并通过 page 中pin_count_字段来区分两个状态。std::unordered_map<page_id_t, frame_id_t> page_table_;
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QfbKIMMN-1635842055916)(image/image.png)]](https://img-blog.csdnimg.cn/4bbadbeea8ab414f94ffa4ae02f6aaac.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBATmV0ZmlzaGxlc3M=,size_20,color_FFFFFF,t_70,g_se,x_16)
上图中,NewPage1 和 NewPage2 表示在 NewPage 函数中,每次获取空闲 frame 时,会先去空闲列表(freelist_)中取一个 free frame,如果取不到,才会去 replacer_ 中驱逐一个 unpinned 的 frame 后使用。这体现了 buffer pool manager 实现的一个目标:最小化磁盘访问,原因后面分析。
实验组件
把握了本实验的基本概念和核心数据流后,再来分析两个子任务。
TASK 1 - LRU REPLACEMENT POLICY
以前在 LeetCode 上写过相关实现,因此很自然的带入之前经验,但随后发现这两个接口有一些不同。
LeetCode 上提供的是 kv store 接口 ,在 get/set 的时候完成新老顺序的维护,并在内存池满后自动替换最老的 KV。
但本实验提供的是 replacer 接口 ,维护一个 unpinned 的 frame_id 列表 ,在调用 Unpin 时将 frame_id 加入列表并维护新老顺序、在调用 Pin 时将 frame_id 从列表中摘除、在调用 Victim 的时候将最老的 frame_id 返回。
当然,本质上还是一样,因此本实验我也是采用 unordered_map 和 doubly linked list 的数据结构,实现细节不再赘述。需要注意的是,如果 Unpin 时发现 frame_id 已经在 replacer 中,则直接返回,并不改变列表的新老顺序。因为逻辑上来说,同一个 frame_id,并不能被 Unpin 多次,因此我们只需要考虑 frame_id 第一次 Unpin。
放到更大的语境中,本质上,replacer 就是一个维护了回收顺序的回收站 ,即我们将所有 pin_count_ = 0 的 page 不直接从内存中删除,而是放入回收站中。根据数据访问的时间局部性原理,刚刚被访问的 page 很可能再次被访问,因此当我们不得不从回收站中真删(Victim)一个 frame 时,需要删最老的 frame。当之后我们想访问一个刚加入回收站的数据时, 只需要将 page 从这个回收站中捞出来,从而省去一次磁盘访问,这也就达到了最小化磁盘访问的目标。
1.1 数据结构设计
std::mutex latch; // thread safety
int capacity; // max number of pages LRUReplacer can handle
std::list<frame_id_t> lru_list;
std::unordered_map<frame_id_t, std::list<frame_id_t>::iterator> lruMap;
这里我们用了链表 + hash表。主要是为了删除和插入均为0(1)的时间复杂度。引入hash表就是可以根据frame_id快速找到其在list中对应的位置。否则的话你需要遍历链表这就不是o(1)了
TASK 2 - BUFFER POOL MANAGER
在实验分析部分已经把核心逻辑说的差不多了,这里简单罗列一下我实现中遇到的问题。
page_table_ ** 的范围** 。在最初实现时,画出 frame 的状态机之后,感觉 page_table_ 中只放 pinned frame id 很完美:可以使 frame id 按状态互斥的分布在 free_list_ 、 replacer_ 和 page_table_ 中。但后来发现,如果不将 unpinned frame id 保存在 page_table_ 中,就不能很好地复用 pin_count_ = 0 的 page 了,replacer 也就没有了意义。
dirty page 的刷盘时机 。有两种策略,一种是每次 Unpin 的时候都刷,这样会刷比较频繁,但能保证异常掉电重启后内容不丢;一种是在 replacer victimized 的时候 lazily 的刷,这样能保证刷的次数最少。这是性能和可靠性取舍,仅考虑本实验,两者肯定都能过。
复用 frame 时清空元信息 。在复用一个从 replacer 中驱逐的 frame 时尤其要注意,使用前一定要将 pin_count_\is_dirty_ 这些字段清空。当然,在 DeletePage 的时候,也需要注意将 page_id_ 置为 INVALID_PAGE_ID 、清空上述字段。否则,再次使用时, 如果 pin_count_ 在 Unpin 后,数值不为 0,会导致 DeletePage 时删不掉该 page。
锁的粒度 。最粗暴的就是每个函数范围粒度加锁即可,后期如果需要优化,再将锁的粒度变细。
2.1 find_replace()函数
- 如果空闲链表非空,则不需要进行替换算法。直接返回一个空闲frame就okay啦。这个情况是buffer pool未满
- 如果空闲链表为空,则表示当前buffer pool已经满了,这个时候必须要执行LRU算法
寻找替换frame过程
- 调用前面实现的
Victim函数获取牺牲帧的frame id<br />2. 在pages_中找到对应的牺牲页,如果该页dirty则需要写回磁盘,并且reset pin count - 然后在page_table中删除对应映射关系 [page_id --> frame_id]
2.2 FetchPageImpl 实现
这个函数就是我们要拿到一个page。这个函数可以分为三种情况分析
- 如果该页在缓冲池中直接访问并且记得把它的
pin_count++,然后把调用Pin函数通知replacer<br />2. 否则调用find_replace函数,无论缓冲池是否有空闲,都可以获得可用的frame_id<br />3. 当然如果替换页为空,择要 - 然后建立新的
page_table映射关系
2.3 UnpinPageImpl 实现
这个函数就是如果我们这个进程已经完成了对这个页的操作。我们需要unpin操作
- 如果这个页的
pin_couter>0我们直接– - 如果这个页的
pin _couter==0我们需要给它加到Lru_replacer中。因为没有人引用它。所以它可以成为被替换的候选人
2.4 FlushPageImpl 实现
这个函数是要把一个page写入磁盘。
- 首先找到这一个页在缓冲池之中的位置
- 写入磁盘
2.5 NewPageImpl 实现
分配一个新的page。
- 利用
find_replace函数在我们的缓冲池找到合适的地方建立page_id --> frame_id的映射 - 更新 新页的元数据这里注意新创建的页要写回磁盘
2.6 DeletePageImpl 实现
这里是要我们把缓冲池中的page移出
- 如果这个
page根本就不在缓冲池则直接返回 - 如果这个
page的引用计数大于0(pin_counter>0)表示我们不能返回 - 如果这个
page被修改过则要写回磁盘 - 否则正常移除就好了。(在hash表中erase)
测试
cd build
make lru_replacer_test
./test/lru_replacer_test --gtest_also_run_disabled_tests
cd build
make buffer_pool_manager_instance_test
./test/buffer_pool_manager_instance_test --gtest_also_run_disabled_tests