Linpack之HPL(High Performence Linpack)测试实验
一. 实验环境
软件环境:Linux(CentOS 7.8)、GCC和GFortran(编译器)、BLAS(用来做矩阵计算或者向量计算的库)、MPICH2(用于并行运算的工具)、HPL
二. 环境搭建
-
安装配置GCC和GFortran
检查环境:
gfortran -v gcc -v安装GCC和Fortran
sudo yum install gcc sudo yum install gcc-gfortran -
安装MPI
-
下载安装BLAS
-
下载并解压blas-3.8.0
wget http://www.netlib.org/blas/blas-3.8.0.tgz tar -xzf blas-3.8.0.tgz -
编译生成blas_LINUX.a文件:make命令
cd BLAS-3.8.0 make -
链接.o文件生成libblas.a文件
ar rv libblas.a *.o -
下载cblas.tgz并解压
wget http://www.netlib.org/blas/blast-forum/cblas.tgz tar -xzf cblas.tgz -
拷贝文件
cd CBLAS cp ~/prepare/BLAS-3.8.0/blas_LINUX.a ./ -
修改 Makefile.in 文件中的 BLLIB文件
vim Makefile.in BLLIB = ~/prepare/BLAS-3.8.0/blas_LINUX.a -
编译并运行

-
-
搭建并行开发环境MPICH2
-
下载并解压mpich-3.2.1.tar.gz
wget http://www.mpich.org/static/downloads/3.2.1/mpich-3.2.1.tar.gz tar xzf mpich-3.2.1.tar.gz -
设置安装路径
./configure --disable-cxx --prefix=/home/$(USERNAME)/mpich-install 2>&1 | tee c.txt -
编译
make 2>&1 | tee m.txt -
安装
sudo make install 2>&1 | tee mi.txt -
配置环境变量
vim ~/.bashrc export PATH=/home/mpich-install/bin:$PATH source ~/.bashrc -
查看前面工作是否成功
which mpicc && which mpiexec mkdir machinefile mpiexec -f machinefile -n 3 hostname && mpiexec -n 5 -f machinefile ./examples/cpi

-
-
-
安装配置HPL
-
复制文件到库中
sudo cp CBLAS/lib/* /usr/local/lib sudo cp BLAS-3.8.0/blas_LINUX.a /usr/local/lib -
下载并解压hpl测试包
wget http://www.netlib.org/benchmark/hpl/hpl-2.3.tar.gz tar -xzf hpl-2.3.tar.gz -
修改Make.Linux_PII_CBLAS文件
vim Make.Linux_PII_CBLAS


-
编译
make arch=Linux_PII_CBLAS -
运行测试,生成测试文件
cd bin/Linux_PII_CBLAS mpirun -np 4 ./xhpl > HPL-Benchmark.txt
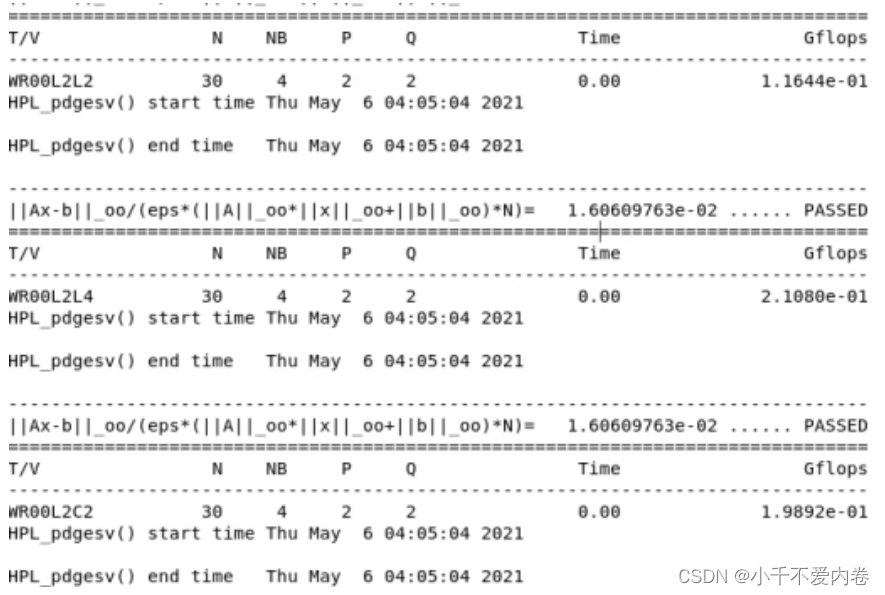
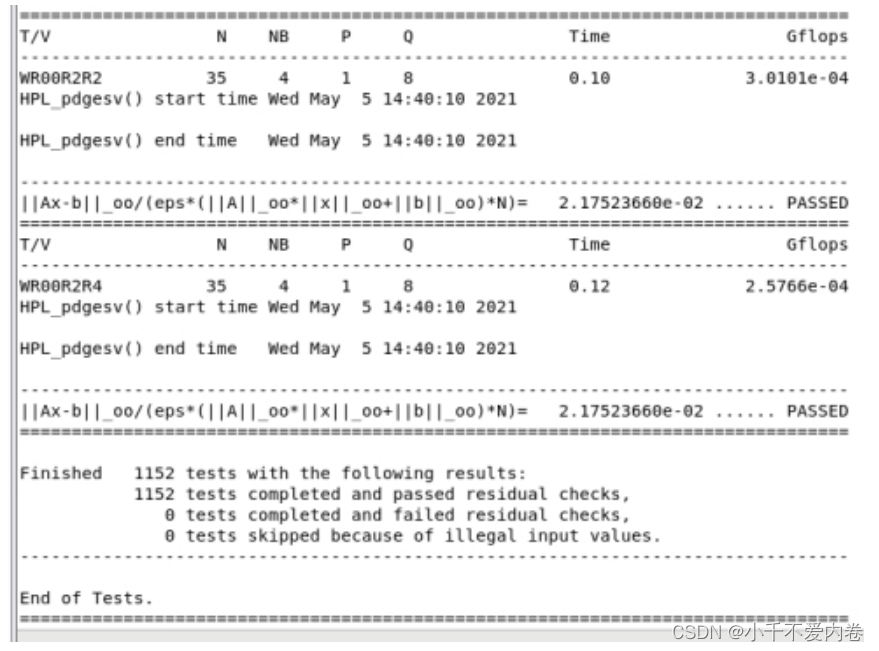
-
三. HPL配置文件参数说明
HPLinpack benchmark input file
Innovative Computing Laboratory, University of Tennessee
HPL.out output file name (if any) // 输出文件名字
8 device out (6=stdout,7=stderr,file) //输出结果文件的形式,为“6”时,测试结果输出至标准输出(stdout),为“7”时,测试结果输出至标准错误输出(stderr),为其它值时,测试结果输出至第3行所指定的文件中
1 # of problems sizes (N) // 求解问题(矩阵)的个数
80000 Ns // 矩阵的阶,参数个数要与上一行值相等
1 # of NBs // 求解问题时采用的分块方式的种数
1024 NBs // 每一种分块的大小,参数个数要与上一行值相等,为提高数据的局部性,从而提高整体性能,HPL采用分块矩阵的算法。NB值的选择主要是通过实际测试得到最优值。
0 PMAP process mapping (0=Row-,1=Column-major) // 选择处理器阵列是按列的排列方式还是按行的排列方式。
1 # of process grids (P x Q)
1 Ps
1 Qs // 以上三行说明二维处理器网格(P×Q)。要遵循以下几个要求:P×Q=进程数。
16.0 threshold // 测试精度
1 # of panel fact
1 PFACTs (0=left, 1=Crout, 2=Right)
1 # of recursive stopping criterium
4 NBMINs (>= 1)
1 # of panels in recursion
2 NDIVs
1 # of recursive panel fact.
1 RFACTs (0=left, 1=Crout, 2=Right)
// 指明L分解的方式。在消元过程中,zHPL采用每次完成NB列的消元,然后更新后面的矩阵。这NB的消元就是L的分解。每次L的分解只在一列处理器中完成。对每一个小矩阵作消元时,都有3种算法:L、R、C,分别代表Left、Right和Crout。在LU分解中,具体的算法很多,测试经验,NDIVs选择2比较理想,NBMINs 4或8都不错。而对于RFACTs和PFACTs,对性能的影响不大。
1 # of broadcast
0 BCASTs (0=1rg,1=1rM,2=2rg,3=2rM,4=Lng,5=LnM)
1 # of lookahead depth
2 DEPTHs (>=0)
2 SWAP (0=bin-exch,1=long,2=mix)
64 swapping threshold
0 L1 in (0=transposed,1=no-transposed) form
0 U in (0=transposed,1=no-transposed) form
1 Equilibration (0=no,1=yes)
8 memory alignment in double (> 0)
四. 运行结果分析
测试中所使用的参数对性能的影响
问题规模N:N时要求解的线性方程Ax=b中的维数。N的选取要考虑内存容量的制约关系,计算公式如下:含义是大约80%的内存容量来进行Linpack测试,另外20%左右用于其他进程。
N ≈ ( 节点数 × M e m / 8 ) × 80 % N\approx \sqrt{(节点数\times Mem/8)\times 80\%} N≈(节点数×Mem/8)×80%
矩阵分块大小NB:系数矩阵被分为NB*NB的循环快被分配到各个进程中去处理,这里的NB也是计算粒度,粒度过粗或者过细都会导致性能下降,所以要选择合适的粒度值。
进程网格的分布P*Q:P表示水平方向处理器个数,Q表示垂直方向处理器个数。P×Q表示二维处理器网格。P×Q=系统CPU数=进程数。一般情况下一个进程对应一个CPU,可以得到最佳性能。进程网格的分布会影响到数据在各个处理器上的分布情况,从实验结果来看,P和Q越接近测试结果越好,而在同样的分解方式下P<Q比P>Q效果要好。
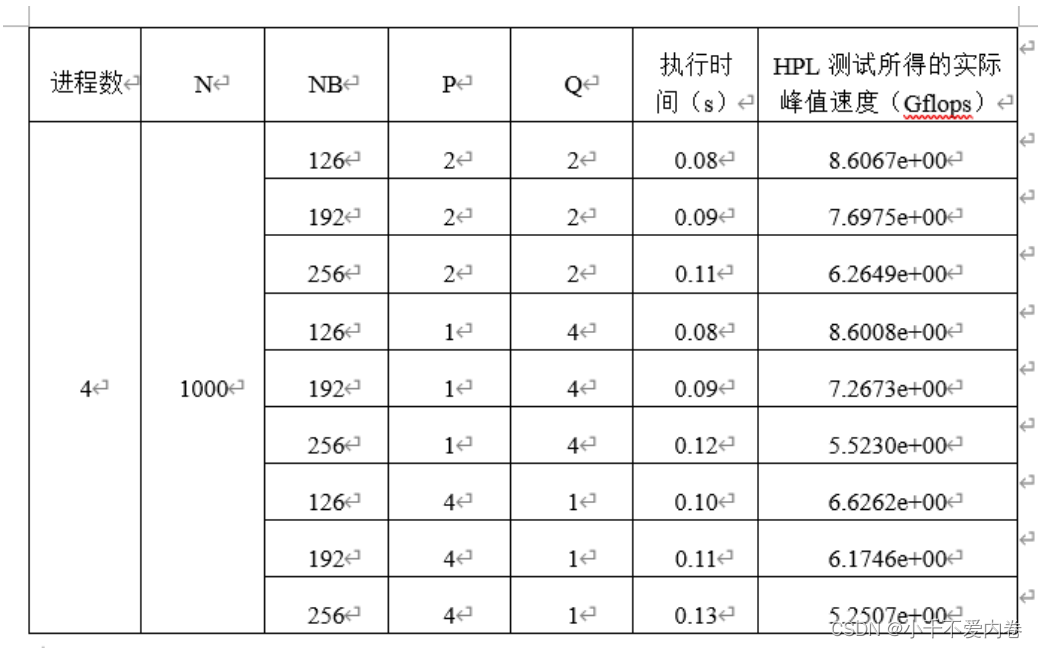
就实验结果来看,当NB(矩阵分块大小)为126时,性能最佳。当P*Q(二维处理器网格)相等性能最好,若不相等,则P<Q比P>Q效果要好。
参考:
https://blog.csdn.net/dianling3902/article/details/101267854
https://blog.csdn.net/cocoonyang/article/details/63068108?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166521161416782414962554%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166521161416782414962554&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-2-63068108-null-null.142^v51^pc_rank_34_queryrelevant25,201^v3^add_ask&utm_term=BLAS&spm=1018.2226.3001.4187
https://blog.csdn.net/fengyunlijie/article/details/109401828?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166521165716781432911434%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166521165716781432911434&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-109401828-null-null.142^v51^pc_rank_34_queryrelevant25,201^v3^add_ask&utm_term=MPICH2&spm=1018.2226.3001.4187
https://blog.csdn.net/duchenhe/article/details/104861020?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166521351316782417072088%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166521351316782417072088&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-104861020-null-null.142^v51^pc_rank_34_queryrelevant25,201^v3^add_ask&utm_term=HPL%E6%98%AF%E4%BB%80%E4%B9%88&spm=1018.2226.3001.4187