coat net论文链接
https://paperswithcode.com/paper/coatnet-marrying-convolution-and-attention#code
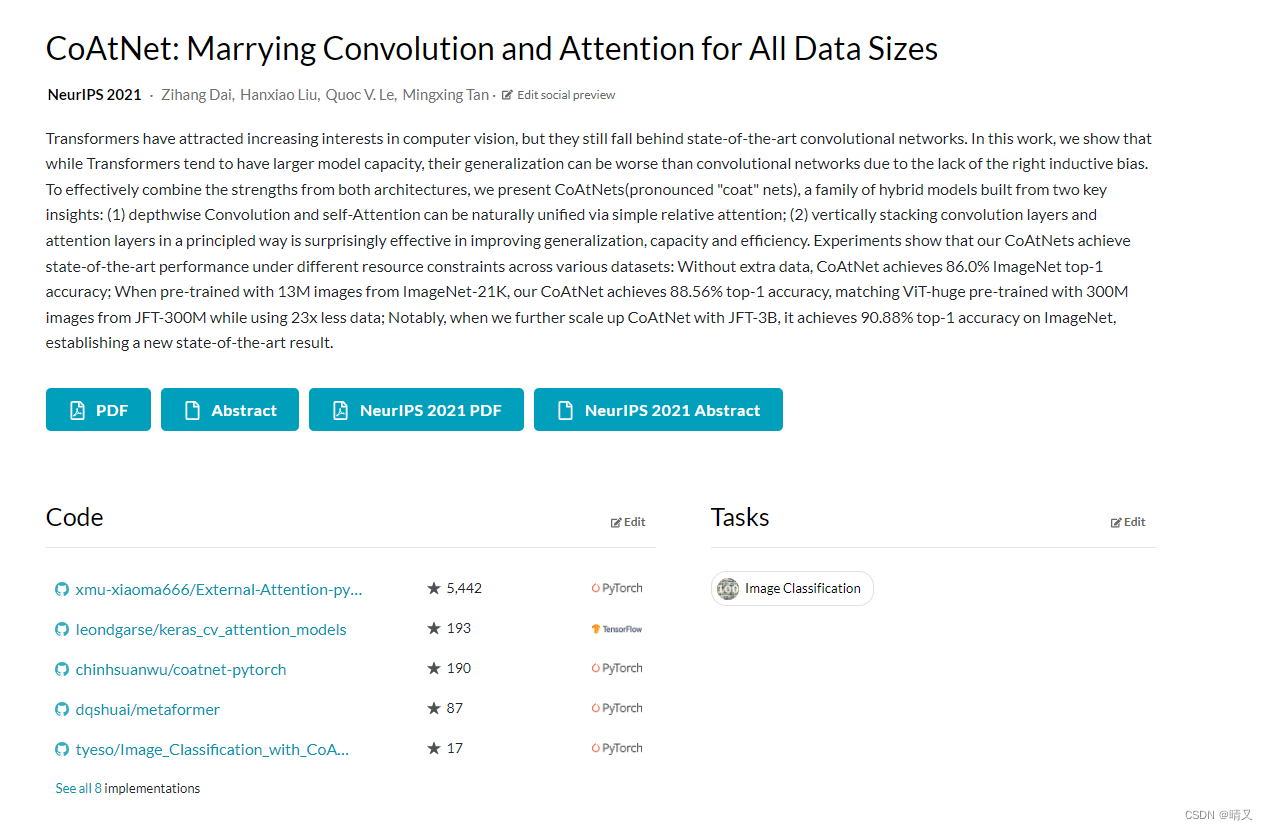
我选的是第三个chinhsuanwu/coatnet-pytorch 他复现的网络框架,我们后续用他的coatnet.py(框架)去写我们自己的train.py和detect.py
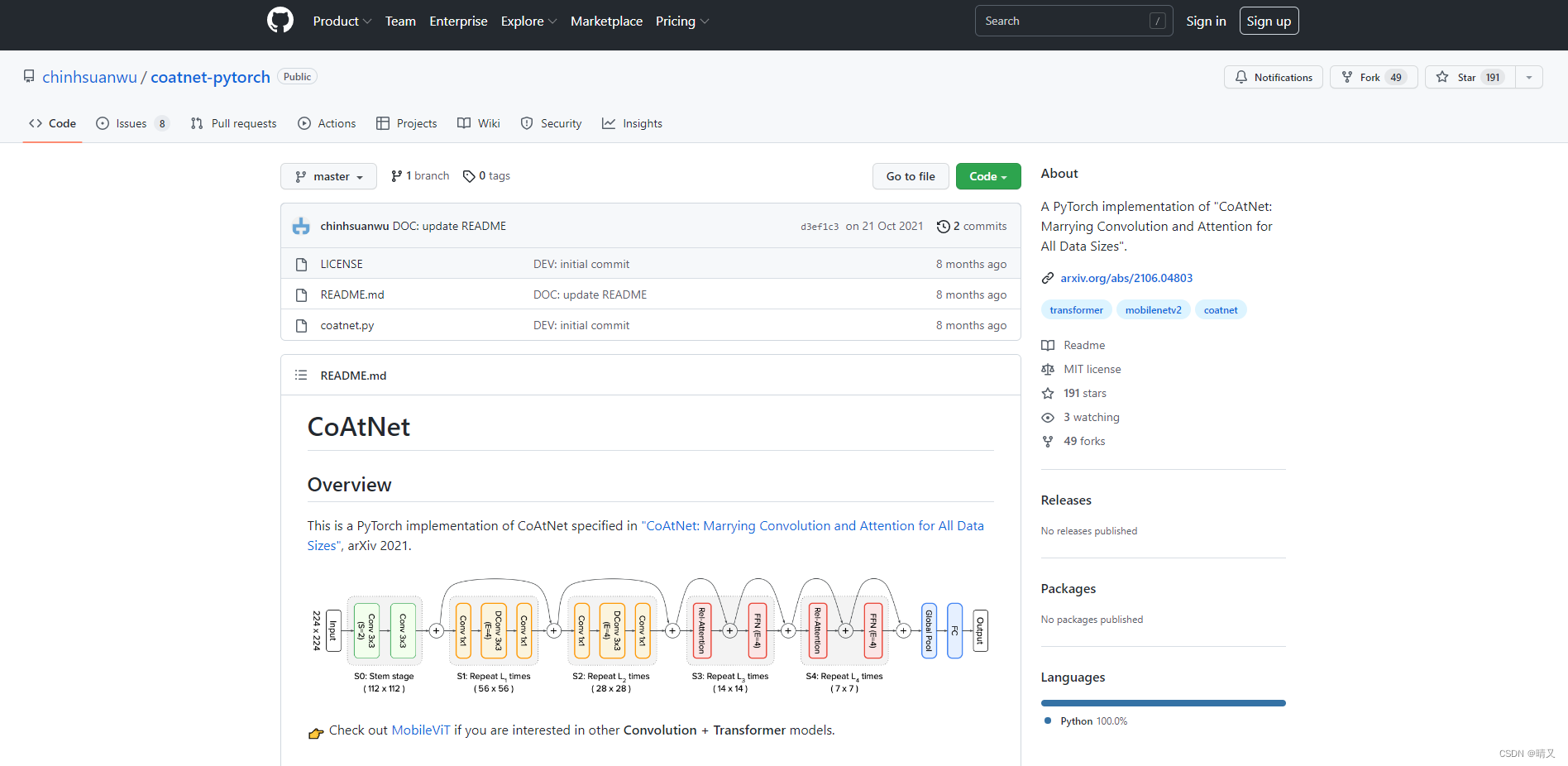
网络框架就在coatnet.py文件里
我们组的工程就是掉这个模型coatnet.py
分为cpu版本和gpu版本的两个train
其余文件都是自己写的
有用的就只有coat net.py(github那作者写的)
train.py(或者train-cpu.py)
config.yml(放训练参数的)
其余都是或多或少自己加的测试文件,比如看看网络模型多大之类的,
train.py(train-cpu.py)里暂时没加什么技巧,就只有加载数据,调用模型,训练,测试,计算loss并保存这些功能
看一下train.py
import torch
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from read_cifar_dataset import MyDataset
from coatnet import CoAtNet
import numpy as np
from read_config import load_cfg
import torchvision
from torchvision import transforms,datasets
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("device:",device)
cfg = load_cfg('config.yml')
n_epochs = cfg['n_epochs']
batch_size_train = cfg['batch_size_train']
batch_size_test = cfg['batch_size_test']
learning_rate = cfg['learning_rate']
momentum = cfg['momentum']
log_interval = cfg['log_interval']
random_seed = 1
torch.manual_seed(random_seed)
# train_cifar10 = MyDataset('train_data.txt')
# val_cifar10 = MyDataset('val_data.txt')
# train_loader = DataLoader(
# dataset=train_cifar10,
# batch_size=batch_size_train,
# shuffle=True,
# )
# test_loader = DataLoader(
# dataset=val_cifar10,
# batch_size=batch_size_test,
# shuffle=True,
# )
transform = transforms.Compose([
transforms.ToTensor(), # numpy -> Tensor
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) # 归一化 ,范围[-1,1]
])
# 训练集
trainset = datasets.CIFAR10(root='./CIFAR10',train=True,download=True,transform=transform)
# 测试集
testset = datasets.CIFAR10(root='./CIFAR10',train=False,download=True,transform=transform)
train_loader = DataLoader(trainset,batch_size=batch_size_train,shuffle=True,num_workers=8,pin_memory=True)
test_loader = DataLoader(testset,batch_size=batch_size_test,shuffle=True,num_workers=8,pin_memory=True)
num_blocks = [2, 2, 12, 28, 2] # L
channels = [192, 192, 384, 768, 1536] # D
network = CoAtNet((32, 32), 3, num_blocks, channels, num_classes=10).to(device)
# 这是之前试了一下resnet模型
# network = torchvision.models.resnet18(pretrained=True).to(device)
# 不知道这里为啥变黄色了,将就看吧
print('load success')
# 自己想加别的就自己加
if cfg['optimizer'] == 'SGD':
optimizer = optim.SGD(network.parameters(), lr=learning_rate, momentum=momentum)
elif cfg['optimizer'] == 'Adam':
optimizer = optim.Adam(network.parameters(), lr=learning_rate)
# 这个也是 可以自己加
if cfg['scheduler'] == 'CosineAnnealingLR':
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=20)
# 后续想保存的参数
train_losses = []
train_accuracy = []
test_losses = []
test_accuracy = []
# 开始训练
def train(epoch):
network.train()
correct = 0
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data.to(device))
loss = F.cross_entropy(output, target.to(device))
loss.backward()
optimizer.step()
train_losses.append(loss.item()/batch_size_train)
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.to(device).data.view_as(pred)).sum()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
# 如果想保存.pth就自己解注
# torch.save(network.state_dict(), './model.pth')
# torch.save(optimizer.state_dict(), './optimizer.pth')
train_accuracy.append(correct.cpu() / len(train_loader.dataset))
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data.to(device))
test_loss += F.cross_entropy(output, target.to(device), size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.to(device).data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
test_accuracy.append(correct.cpu() / len(test_loader.dataset))
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for n_epoch in range(1, n_epochs + 1):
train(n_epoch)#这个参数是在config.yml文件里定义的,下面会讲
test()
scheduler.step()
if n_epoch%50 == 0:
# 每50保存一次,名字这里用了一个比较笨的方法hhh
# 这里我把结果保存在result文件夹了,结束后可以确认下
torch.save(network.state_dict(), './result/model'+str(n_epoch)+'.pth')
torch.save(optimizer.state_dict(), './result/optimizer'+str(n_epoch)+'.pth')
# 保存这几个npy文件,后续用来自己download下来plt画个图
np.save('train_loss.npy', np.array(train_losses))
np.save('train_accuracy.npy', np.array(train_accuracy))
np.save('test_loss.npy', np.array(test_losses))
np.save('test_accuracy.npy', np.array(test_accuracy))
config.yml文件
里面写了一些参数
n_epochs = 400
batch_size_train = 64
batch_size_test = 1000
optimizer = SGD
learning_rate = 1e-3
momentum = 0.5
scheduler = CosineAnnealingLR
log_interval = 10
现在就结束了,可以在gpu上运行了
这是我的日志文件
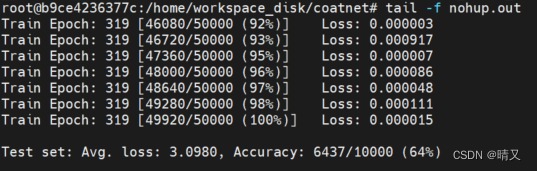
感觉效果好像不太好 或许是因为cifar的图都比较小
后续还在改进中。。。