
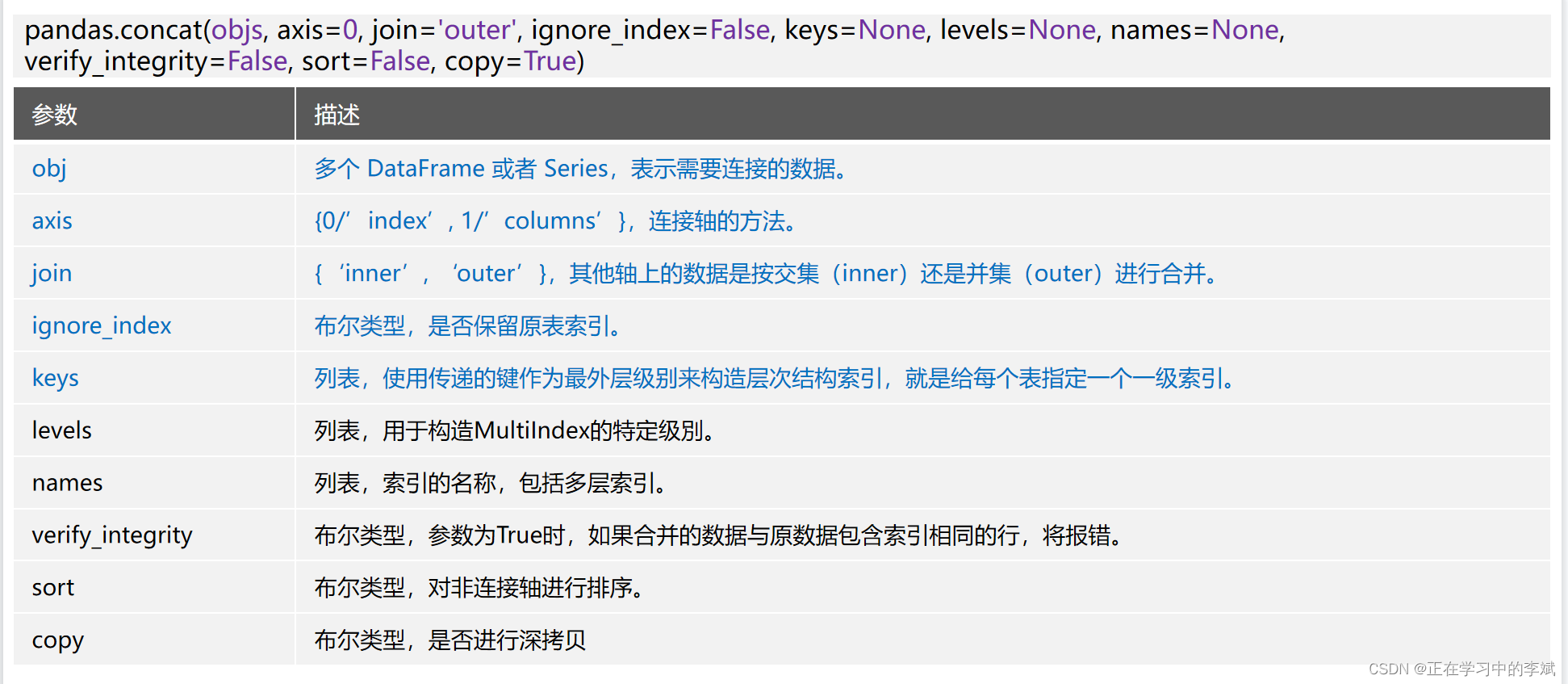
pd.concat 数据拼接、绑定或堆叠。
一、参数详解
join_axes已弃用,如果需要使用此功能,建议用 merge

二、实例代码
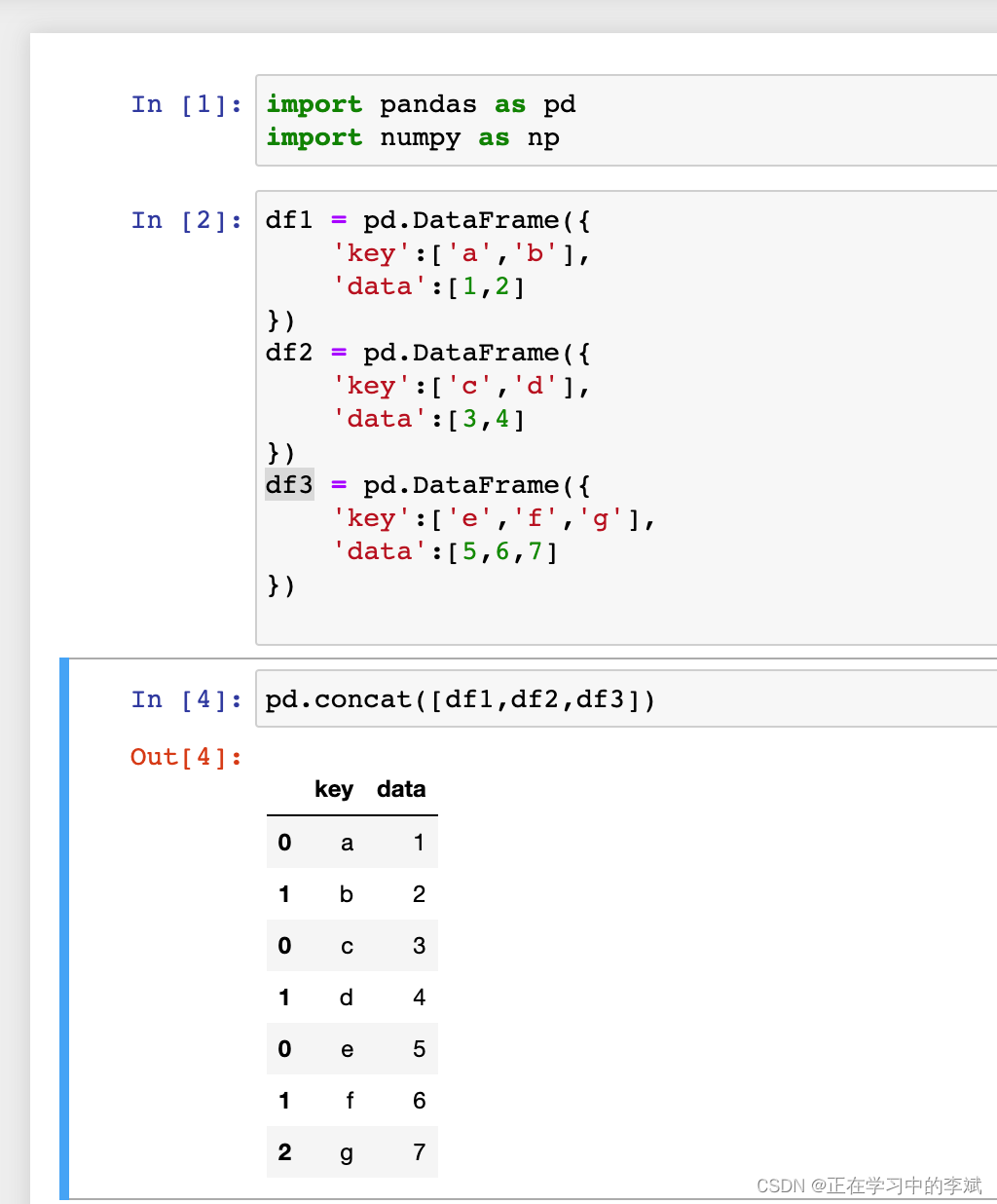
1. 简单拼接。
1.1 初始化数据及运行结果。
- concat 默认是
axis=0方向连接的。(竖向 / 上下 拼接)。
pd.concat([df1,df2,df3],axis=1) # 横向 / 左右拼接
- join 用来指定拼接的方式,可选
inner 和 outer(类似于 merge 的 how 参数)
inner 取交集,舍弃部分,只拼接都存在的列(或者行),数据量可能变小。
outer 取并集。
pd.concat([df1,df2,df3],join='inner')
1.2 代码。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'key':['a','b'],
'data':[1,2]
})
df2 = pd.DataFrame({
'key':['c','d'],
'data':[3,4]
})
df3 = pd.DataFrame({
'key':['e','f','g'],
'data':[5,6,7]
})
pd.concat([df1,df2,df3])
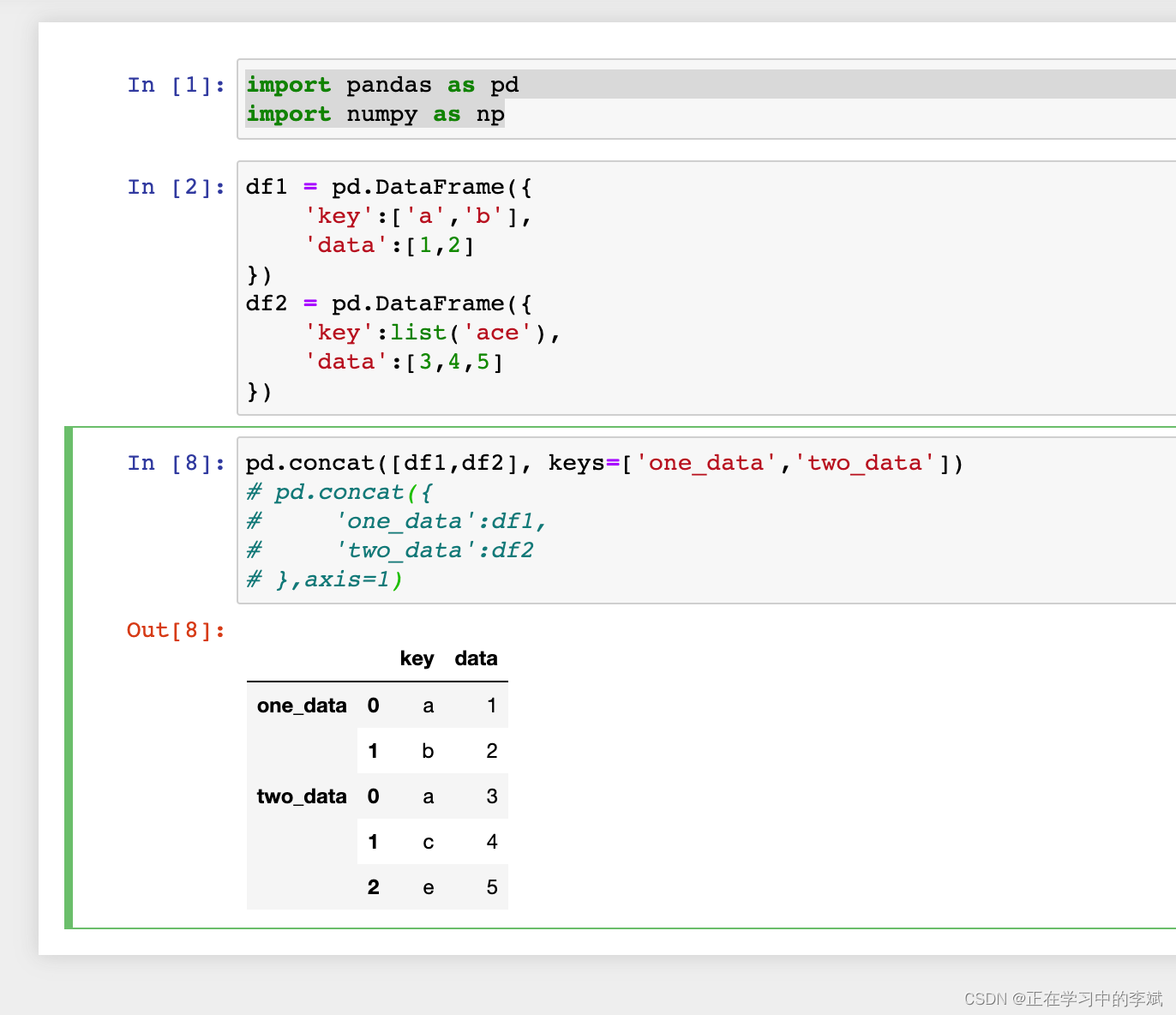
2. 简单拼接。
2.1 初始化数据及运行结果。
- concat 可以用 keys 来标明数据的来源。
- 也可以用字典形式。如图注释部分。
- 如图,此时我们的索引是
0 1 0 1 2。我们可以用ignore_index = True重新排序。索引就会变为0 1 2 3 4
pd.concat([df1,df2], keys=['one_data','two_data'],ignore_index = True)
2.2 代码。
- 小tip:可以用
list('abcdefg')直接产生一个对应的数组。
import pandas as pd
import numpy as np
df1 = pd.DataFrame({
'key':['a','b'],
'data':[1,2]
})
df2 = pd.DataFrame({
'key':list('ace'),
'data':[3,4,5]
})
pd.concat([df1,df2], keys=['one_data','two_data'])
# pd.concat({
# 'one_data':df1,
# 'two_data':df2
# },axis=1)
ignore_index 忽视原来的索引
pd.concat(dfl, ignore_index=True)
读取文件夹下所有文件
import pandas as pd
import glob
files = list(glob.glob('./data/C3.6 数据的拼接与合并/*'))
dfl = []
for f in files:
df = pd.read_csv(f)
dfl.append(df)
pd.concat(dfl, join='inner')