目录

前言
作为排序界的兰博基尼,快速排序某种程度上可以秒杀所有排序方法,之所以敢在名字中带上快速二字,是因为其整体的综合性能和使用场景都是较好的,这也正是排序所需要的,当然,对于普通的快排,有些情况下会不如其他排序方法,但经过优化之后,称之为兰博基尼真的是当之无愧,下面来看一下快排的详解吧。

简介
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。---百度百科
由上可知,快速排序本身是个递归,将某元素放到相应位置后,元素左右将数组分为两部分,递归进行左右两个部分,显然递归停止条件就是当分割后只剩下一个元素。所以,将整个快排程序分为递归框架与核心成分两个部分,见下方详细介绍。
快排QS()在main函数中的环境如下代码块,Test()函数用来测试是否可以成功完成排序,二TestOP()函数是用来将快排与其他排序相比较,通过程序实现排序100万个数的时间来展现,具体实现不再赘述。
// 测试排序的性能对比
void TestOP()
{
srand((unsigned int)time(0));
const int N = 1000000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
for (int i = 0; i < N; ++i)
{
a1[i] = rand();
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
}
int begin1 = clock();
DIS(a1, N);
int end1 = clock();
int begin2 = clock();
SS(a2, N);
int end2 = clock();
int begin3 = clock();
HS(a3, N);
int end3 = clock();
int begin4 = clock();
QS(a4, 0, N - 1);
int end4 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("HeapSort:%d\n", end3 - begin3);
printf("QuickSort:%d\n", end4 - begin4);
free(a1);
free(a2);
free(a3);
free(a4);
}
//自身测试
void Test()
{
int arr[] = { 45,26,88,51,90,32,6,11,26 };
int sz = sizeof(arr) / sizeof(arr[0]);
printf("排序前:\n");
PrintArr(arr, sz);
QS(arr, 0, sz-1);
printf("排序后:\n");
PrintArr(arr, sz);
return 0;
}
int main()
{
Test();
//TestOP();
}详细介绍
-
递归框架
递归框架也就是整个排序实现的框架,传入的arr是整个数组的首地址,left、right是数组所操作部分的方位的下标,核心成分的实现有partion1、2、3三种方法,下面会一一实现。
代码:
void QS(int* arr, int left, int right)
{
if (right <= left) //递归结束条件
return;
//核心成分
int mid = partition1(arr, left, right);
//int mid = partition2(arr, left, right);
//int mid = partition3(arr, left, right);
QS(arr, left, mid - 1);
QS(arr, mid + 1, right);
}-
核心成分
1.方法一
第一种方法就是发明快排的大牛hoare老师,称为hoare法。
思路过程:
1)选定L为关键字下标keyi,
2)R--,即R向左走,遇到比arr[keyi]小的值停下,L++,即L向右走,遇到比arr[keyi]大的值停下,交换L、R所在的值,此为一个循环,
3)循环2)至L与R相遇,此时将相遇下标所在的值与arr[keyi]交换。
图解:
注意:
① 在2)中要保证一定是R先走,或者R做keyi,L先走,否则相遇点就不是keyi的相应位置
② 代码中的两个标记处一定要加等于号,否则遇到相等的两个值会陷入死循环
代码:
int partition2(int* arr, int left, int right)
{
int tmpi = left;
while (left < right)
{
while (left < right && arr[right] >= arr[tmpi])//标记
right--;
while (left < right && arr[left] <= arr[tmpi])//标记
left++;
Swap(&arr[left], &arr[right]);
}
Swap(&arr[tmpi], &arr[left]);
return left;
}2.方法二
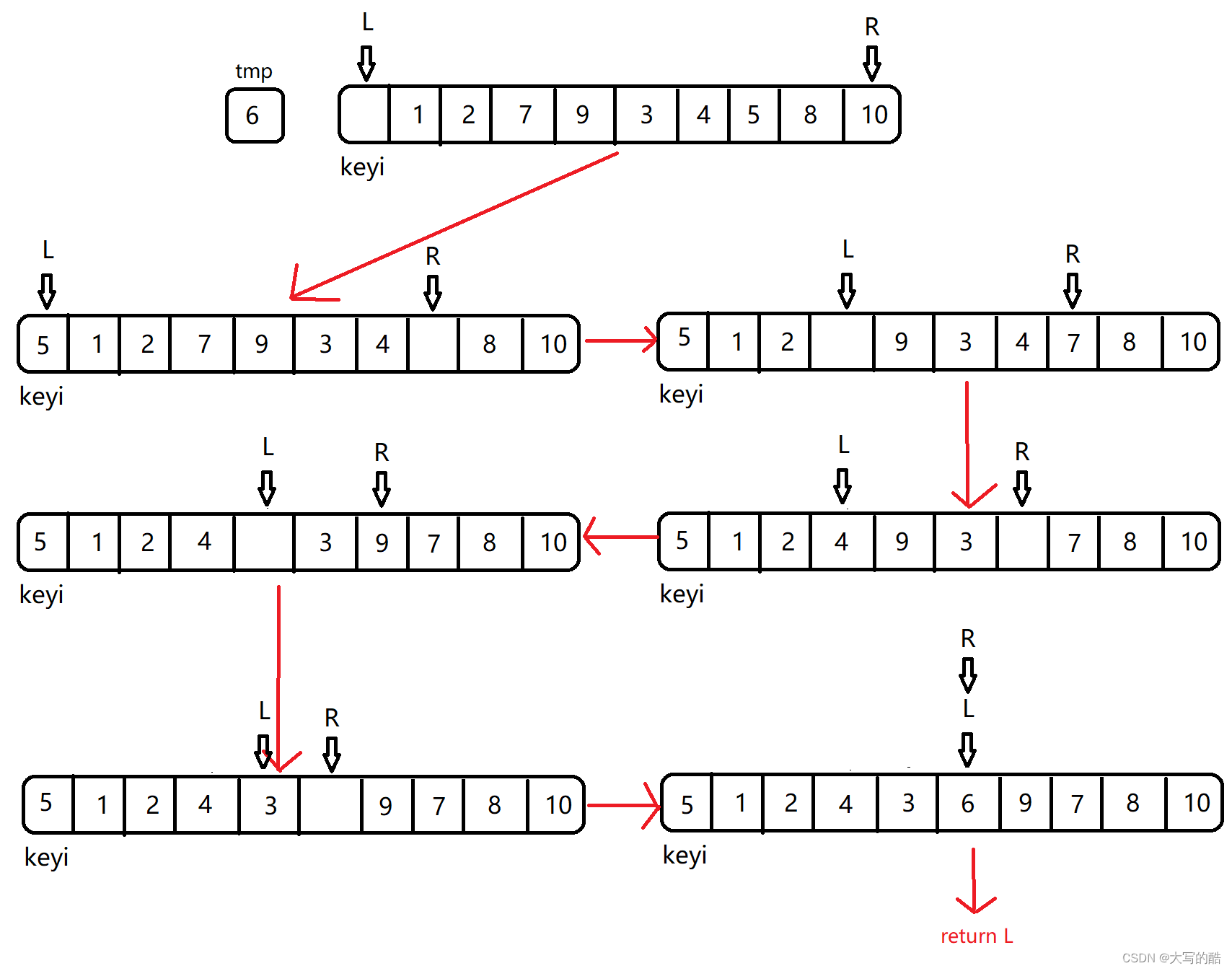
第二种方法就是大部分书籍上会写到的方法---挖坑法。
思路过程:
1)选定L为关键字下标keyi,将arr[keyi]存放在临时变量tmp中,此时keyi就形成了一个坑位,
2)R--,即R向左走,遇到比arr[keyi]小的值停下,将此值放入到坑位中,此时此值所在位就形成了一个坑位,将其L++,即L向右走,遇到比arr[keyi]大的值停下,将此值放入到坑位中,此时此值所在位就形成了一个坑位,此为一个循环,
3)循环2)至L与R相遇,将tmp的值放入最后一个坑位中。
图解:
注意:
① 此方法不规定谁先走
②两个循环中的等于号一定要加
代码:
int partition2(int* arr, int left, int right)
{
int tmp = arr[left];
while (left < right)
{
while (left < right && arr[right] >= tmp) //这里两个while的arr[]>=tmp不加等于号,在数组中存在两个相等的值时,会死循环
//因为纯大于的话,两个数相等就会出循环然后赋值,导致两个数赋值来赋值去,导致死循环
right--;
arr[left] = arr[right];
while (left < right && arr[left] <= tmp)
left++;
arr[right] = arr[left];
}
arr[left] = tmp;
return left;
}3.方法三
第三个方法就是前后指针法。
思路过程:
1)选定left为关键字下标keyi,定义两个伪指针front和rear在left处
2)front从头遍历数组元素,若此元素比关键字小,就让rear++,然后交换arr[rear]与arr[front],直至front遍历所有元素结束,
3)交换arr[keyi]与arr[rear],此时关键字到了相应位置,即下标为rear的位置。
图解:

代码:
int partition3(int* arr, int left, int right)
{
int front = left;
int rear = left;
int tmpi = left;
while (front <= right)
{
if (arr[front] < arr[tmpi])
{
rear++;
Swap(&arr[rear] , &arr[front]);
}
front++;
}
Swap(&arr[rear], &arr[tmpi]);
return rear;
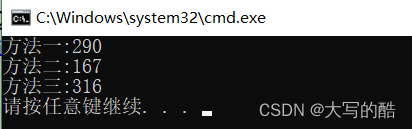
}三种方法对比(1000000个元素):
由下图可见,第二种方法最快,第一、三种方法差不多。
未优化版(第三种方法)与其他排序方法对比(100000个元素):
由下图可见,插入排序的性能最拉,堆排序、希尔排序和快排差不多。

-
过程优化
1.优化一
第一中优化就是针对上述三种方法中思路过程的第一步中的选择关键字,原本只是简单粗暴的选择第一个元素作为关键字,这里优化为三数取中选关键字,即left、right、(left+right)/2为下标的三个数中选择中间大的数作为关键字。
通过getMidIndex函数实现找到三数中中间大的数的下标,这里使用第三种方法举例,找到之后,将其与第一个元素交换。
代码:
int getMidIndex(int* arr, int left, int right)
{
int midi = (left + right) / 2;
if (arr[left] < arr[midi])
{
if (arr[midi] < arr[left])
{
return midi;
}
else
{
if (arr[left] > arr[right])
return left;
else
return right;
}
}
else //arr[left]>=arr[midi]
{
if (arr[left] < arr[right])
{
return left;
}
else
{
if (arr[midi] > arr[right])
return midi;
else
return right;
}
}
}
int partition3(int* arr, int left, int right)
{
int front = left;
int rear = left;
int tmpi = left;
//三数取中法优化
int midi = getMidIndex(arr, left, right);
Swap(&arr[tmpi], &arr[midi]);
while (front <= right)
{
if (arr[front] < arr[tmpi])
{
rear++;
Swap(&arr[rear] , &arr[front]);
}
front++;
}
Swap(&arr[rear], &arr[tmpi]);
return rear;
}基于方法三加上优化一对比(1000000个元素):
由图可见,优化前后性能明显提高。

2.优化二
我们知道,快排的实现是个递归,越向下递归,递归的次数越多,当元素个数非常之多时,下面的递归可以说是爆炸多,这里就会遇到栈溢出的问题,所以设置 在操作的子序列长度来到10之内时,整个数组就进行一次插入排序。
代码:
void QS(int* arr, int left, int right)
{
if (right <= left) //递归结束条件
return;
if (right - left < 10)
{
DIS(arr + left, right - left + 1);
}
else
{
int mid = partition3(arr, left, right);
QS(arr, left, mid - 1);
QS(arr, mid + 1, right);
}
}基于优化一加上优化二对比(1000000个元素):
由下图可知,优化二之后性能也有明显提高。

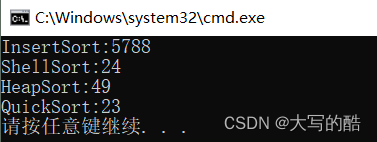
优化版与其他排序方法对比(100000个元素):
由下图可知,在两次优化后,快排的性能依然最高,而且这只是优化了方法三的基础上比较的数据,若是方法二优化之后,定会凌驾于希尔排序、堆排序之上。
以上就是快速排序的详解了,注意上述比较的数据仅为参考,结果应当多次比较取平均才较为准确,有实现过程不懂或者有疑问的小伙伴可以私我或者评论区,记得三连支持哦!