引入
java为啥需要解析XML的方法?
xml的优势:
它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。 它非常适合万维网传输,提供统一的方法来描述和交换独立于应用程序或供应商的结构化数据。是Internet环境中跨平台的、依赖于内容的技术,也是当今处理分布式结构信息的有效工具。早在1998年,W3C就发布了XML1.0规范,使用它来简化Internet的文档信息传输。
所以啊,java不得不爱。
DOM方式解析XML文件的步骤
1.从xml获得生成DOM对象树的解析器
语句:`
DocumentBuilderFactory docbf = DocumentBuilderFactory.newInstance();`- 1
2.获得Doucument的生成器,可以利用解析器的newDocumentBuilder()获得示例
语句:
DocumentBuilder docb = docbf.newDocumentBuilder();- 1
3.用DocumentBuilder的parse()解析xml文件获得Doucment对象。
语句:
Document doc = docb.parse("ProfessionalBooks.xml");- 1
4.获得当前节点的所有子节点
NodeList nodes = doc.getChildNodes();- 1
5.由于xml是是树状结构,所以要写个函数遍历树。
public static void ReadTreeStructure(NodeList nodes) {
// 遍历所有子节点
for (int i = 0; i < nodes.getLength(); i++) {
// 获得字节点名,判断子节点的类型,区分出text类型的node以及element类型的node
if (nodes.item(i).getNodeType() == Node.ELEMENT_NODE) {
System.out.print("该节点的名称为:" + nodes.item(i).getNodeName() + " ");
String value = ((Text) (nodes.item(i).getFirstChild())).getData().trim();
if (value.getBytes().length != 0) {
System.out.print("该节点的值为:" + value);
}
System.out.println();
System.out.println();
}
// 获得子节点的值,如果没有就不输出
// 如果子节点还有子节点就继续往下层读
if (nodes.item(i).getChildNodes().getLength() != 0) {
ReadTreeStructure(nodes.item(i).getChildNodes());
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
具体代码:
1.解析代码
package com.imooc.domtest.test;
import java.io.IOException;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.NamedNodeMap;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.w3c.dom.css.DocumentCSS;
import org.xml.sax.SAXException;
import org.w3c.dom.Text;
import com.sun.org.apache.xalan.internal.xsltc.dom.DocumentCache;
/**
* @author wangahifeng
*
*/
public class MyDOMTest {
/**
* @param args
*/
/*
* 写一个读取树的函数: 1:获得第一层子节点 2:获得子节点的属性 3:完成第一、二步后读取下一层回掉函数重复执行第一、二步后
*/
public static void ReadTreeStructure(NodeList nodes) {
// 遍历所有子节点
for (int i = 0; i < nodes.getLength(); i++) {
// 获得字节点名,判断子节点的类型,区分出text类型的node以及element类型的node
if (nodes.item(i).getNodeType() == Node.ELEMENT_NODE) {
System.out.print("该节点的名称为:" + nodes.item(i).getNodeName() + " ");
String value = ((Text) (nodes.item(i).getFirstChild())).getData().trim();
if (value.getBytes().length != 0) {
System.out.print("该节点的值为:" + value);
}
System.out.println();
System.out.println();
}
// 获得子节点的值,如果没有就不输出
// 如果子节点还有子节点就继续往下层读
if (nodes.item(i).getChildNodes().getLength() != 0) {
ReadTreeStructure(nodes.item(i).getChildNodes());
}
}
}
public static void main(String[] args) {
// TODO Auto-generated method stub
// 用DocumentBuilderFactory的newInstance()从xml获得生成DOM对象树的解析器
DocumentBuilderFactory docbf = DocumentBuilderFactory.newInstance();
try {
// 顾名思义DocumentBuilder是Doucument的生成器,可以利用解析器的newDocumentBuilder()获得示例
DocumentBuilder docb = docbf.newDocumentBuilder();
// 用DocumentBuilder的parse()解析xml文件获得Doucment对象下面就可以利用它获得xml文件的内容了
Document doc = docb.parse("ProfessionalBooks.xml");
System.out.println("该文档有" + doc.getChildNodes().getLength() + "个一层节点");
// 获得当前节点的所有子节点
NodeList nodes = doc.getChildNodes();
ReadTreeStructure(nodes);
// 下面决定写个方法一层一层剥开xml文件,由于xml是树的结构所以要用到读取树的方法
} catch (ParserConfigurationException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SAXException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
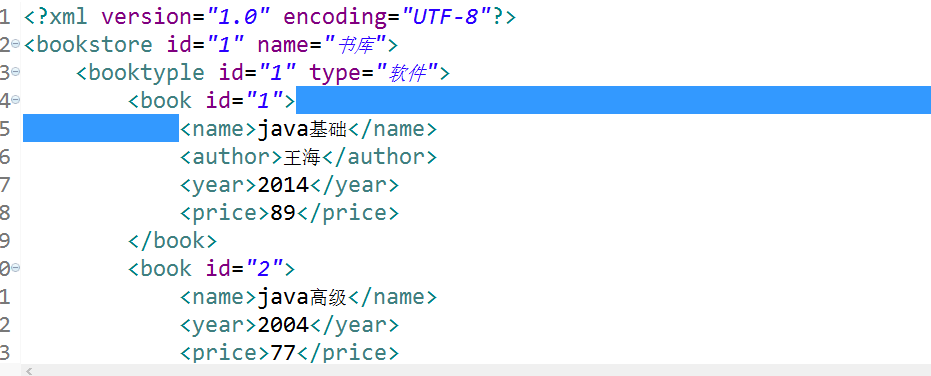
xml文件
<?xml version="1.0" encoding="UTF-8"?>
<bookstore id="1" name="书库">
<booktyple id="1" type="软件">
<book id="1">
<name>java基础</name>
<author>王大/author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>java高级</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</booktyple>
<booktyple id="2" type="数学">
<book id="1">
<name>高数一</name>
<author>王峰</author>
<year>2014</year>
<price>89</price>
</book>
<book id="2">
<name>高数二</name>
<year>2004</year>
<price>77</price>
<language>English</language>
</book>
</booktyple>
</bookstore>- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
结果图

注意:
1.函数里面,筛选了xml的节点类型,因为xml的节点除了标签外,还存在text类型的节点,它一般只用来存放文字,没有NodeName。所以不用获取。
2.这里的获得text类型的value是直接获得当前的子节点的value,但是element类型的node是没有value的,只有text类型的node才有,所以油用if语句筛选,至于为啥那样写,自己想,想想和用if (value.getBytes().length != null)的区别自己运行下。
3.下图蓝色区域也是一个text类型的节点。放文字的也是text类型的节点,所以算外面element类型的node的子节点。
- 1
- 2
- 3
- 4
- 5
- 6