SpringBoot+Vue+PdfJS实现大文件分片加载 后端实现
在企业开发中,我们经常会用到大文件显示的问题,比如一个100M的PDF文件,我们想要把它加载到浏览器的页面或者APP上,如果我们用全加载的话,就有可能出现加载慢,甚至报内存溢出的错误,所以这时候我们就需要使用分片加载的技术了
分片加载需要浏览器的支持,像谷歌和火狐都默认支持分片加载,当我们使用PdfJS的时候,我们可以通过PdfJS的配置项去开启浏览器分片加载功能
当然,服务器端也需要开启支持分片的功能,具体是通过几个响应头参数进行配置的,这样,当前端浏览器需要加载分片时,就会从服务器端拉取分片信息,这些操作可以看做为网络协议为我们封装的,自然不用我们来实现,我们需要做的只是按照规则进行配置即可,但是后端需要对文件流进行切片,下面就来看看具体是如何实现
技术栈:SpringBoot,Vue,PdfJS
后端实现
一般来讲,后端会获取一个PDF文件流,然后我们会根据Request请求头里的Range参数去截取文件流的分片,然后将分片写入Response的输出流里,返回给前端加载展示,做到按需展示
注意,如果使用pdfjs工具的话,则不需要我们指定range,pdfjs会帮我们封装好每次请求的range范围,一般情况下是不需要我们手动指定分片range范围
项目结构
因为测试,所以只需要新建一个Controller即可,来指定分片加载的后端接口
代码实现
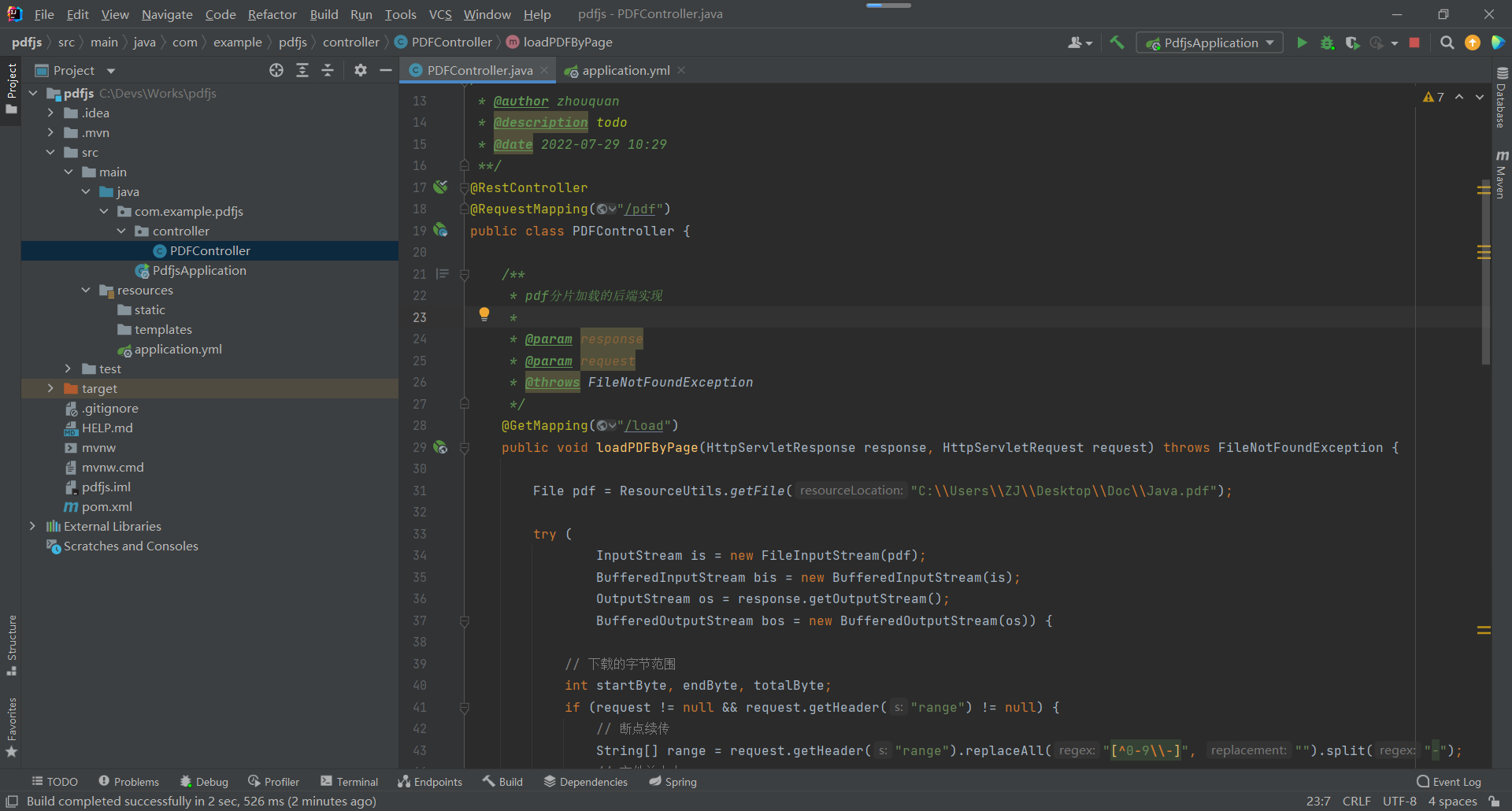
PDFController的具体实现,这里我们只使用本地的一个Pdf文件作为测试,将它转成文件流的形式,然后分片流写入Http的Response流,返回给客户端,注意响应头的设置是为了开启服务端分片加载的功能,因此不能省去,具体配置可以查看代码中的说明信息
package com.example.pdfjs.controller;
import org.springframework.util.ResourceUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
/**
* @author zj
* @description pdf分片加载
* @date 2023-07-06 10:29
**/
@RestController
@RequestMapping("/pdf")
public class PDFController {
/**
* pdf分片加载的后端实现
*
* @param response
* @param request
* @throws FileNotFoundException
*/
@GetMapping("/load")
public void loadPDFByPage(HttpServletResponse response, HttpServletRequest request) throws FileNotFoundException {
File pdf = ResourceUtils.getFile("C:\\Users\\ZJ\\Desktop\\Doc\\Java.pdf");
try (
InputStream is = new FileInputStream(pdf);
BufferedInputStream bis = new BufferedInputStream(is);
OutputStream os = response.getOutputStream();
BufferedOutputStream bos = new BufferedOutputStream(os)) {
// 下载的字节范围
int startByte, endByte, totalByte;
if (request != null && request.getHeader("range") != null) {
// 断点续传
String[] range = request.getHeader("range").replaceAll("[^0-9\\-]", "").split("-");
// 文件总大小
totalByte = is.available();
// 下载起始位置
startByte = Integer.parseInt(range[0]);
// 下载结束位置
if (range.length > 1) {
endByte = Integer.parseInt(range[1]);
} else {
endByte = totalByte - 1;
}
// 返回http状态
response.setStatus(206);
} else {
// 正常下载
// 文件总大小
totalByte = is.available();
// 下载起始位置
startByte = 0;
// 下载结束位置
endByte = totalByte - 1;
// 返回http状态
response.setHeader("Accept-Ranges", "bytes");
response.setStatus(200);
}
// 需要下载字节数
int length = endByte - startByte + 1;
//表明服务器支持分片加载
response.setHeader("Accept-Ranges", "bytes");
//Content-Range: bytes 0-65535/408244,表明此次返回的文件范围
response.setHeader("Content-Range", "bytes " + startByte + "-" + endByte + "/" + totalByte);
//告知浏览器这是一个字节流,浏览器处理字节流的默认方式就是下载
response.setContentType("application/octet-stream");
//表明该文件的所有字节大小
response.setContentLength(length);
//需要设置此属性,否则浏览器默认不会读取到响应头中的Accept-Ranges属性,因此会认为服务器端不支持分片,所以会直接全文下载
response.setHeader("Access-Control-Expose-Headers", "Accept-Ranges,Content-Range");
// 响应内容
bis.skip(startByte);
int len = 0;
byte[] buff = new byte[1024 * 64];
while ((len = bis.read(buff, 0, buff.length)) != -1) {
if (length <= len) {
bos.write(buff, 0, length);
break;
} else {
length -= len;
bos.write(buff, 0, len);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
接口请求
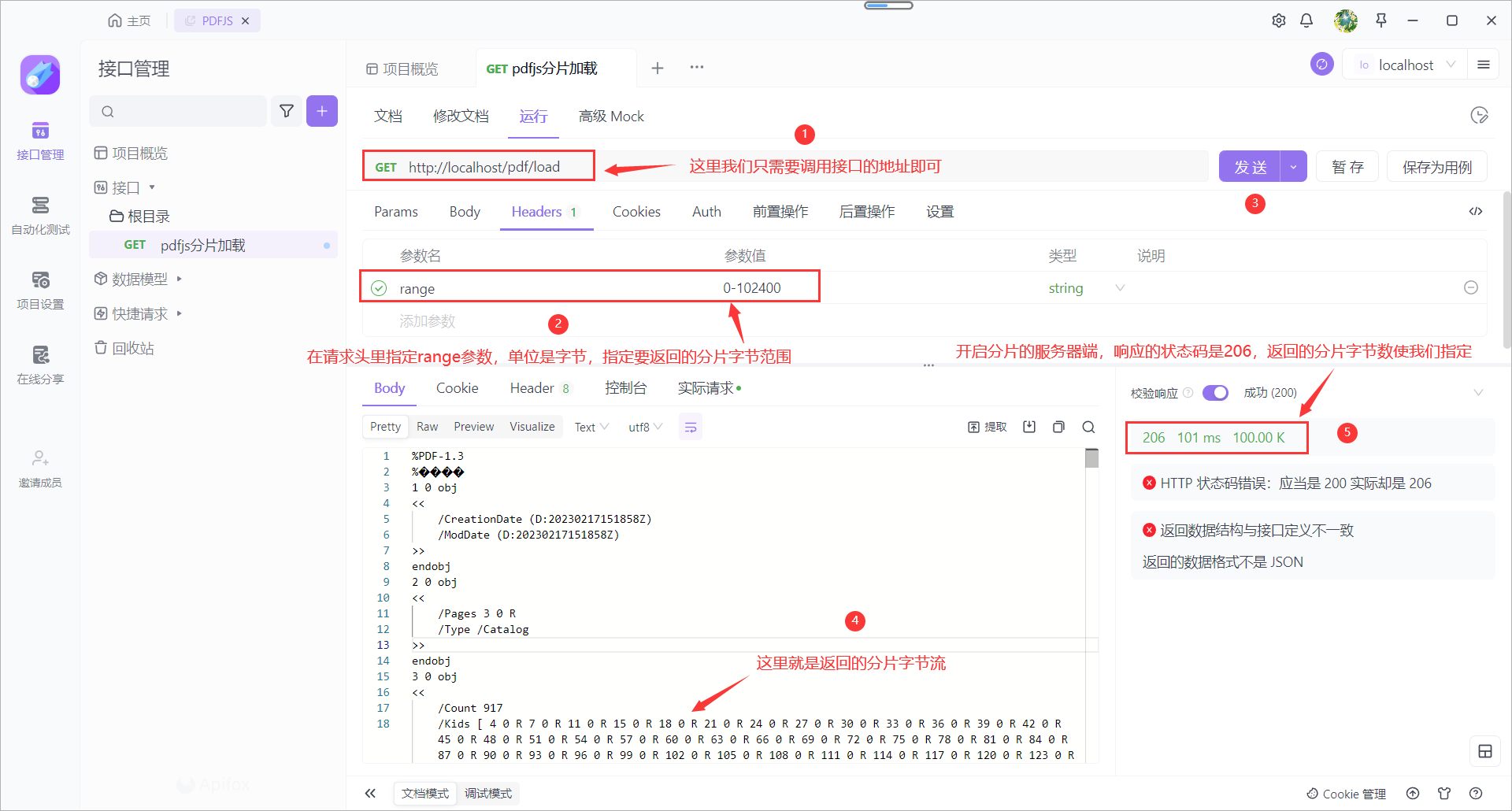
我们使用ApiFox请求,查看接口返回的数据
注意:可以通过响应头配置流的类型
//文件流
response.setContentType("application/octet-stream");
//Pdf文件
response.setContentType("application/pdf");
这样,我们就可以在ApiFox中查看返回的字节流信息了,如下:
注意:这里我们只是测试所以在请求头里加了range参数,实际在项目中当我们使用PdfJS时,是不需要手动添加range参数,PdfJS会根据需要自动计算range值传给后台,如果我们手动添加range请求头参数,我们会发现下载的数据是损坏的,这是因为,PdfJS分片加载文件流时,会先发送一个200的请求用以获取文件的元数据和目录等信息,然后再发送206请求获取分片再去元数据和目录中查找对应的分片信息,所以能正常显示文件内容,而如果我们直接指定请求字节范围,请求就不会去发送200请求获取Pdf文件的元数据和目录等先驱数据,这时虽然正常获取了分片数据流,但是浏览器无法解析就会报文件格式损坏的错误