您是否知道标记文本的方式可以成就或破坏您的语言模型?您是否曾经想过用一种罕见的语言或专门的领域来标记文档?将文本分割成标记,这不是一件苦差事;它是将语言转化为可操作的情报的门户。这个故事将教你关于标记化所需了解的一切,不仅适用于 BERT,也适用于任何法学硕士。
在我的上一篇文章中,我们讨论了BERT,探讨了它的理论基础和训练机制,并讨论了如何对其进行微调并创建问答系统。现在,当我们进一步探讨这一开创性模型的复杂性时,是时候关注一下无名英雄之一了:标记化。
我得到它; 标记化似乎是您和令人兴奋的模型训练过程之间的最后一个无聊的障碍。相信我,我以前也是这么想的。但我在这里告诉你,代币化不仅仅是一种“必要的罪恶”——它本身就是一种艺术形式。
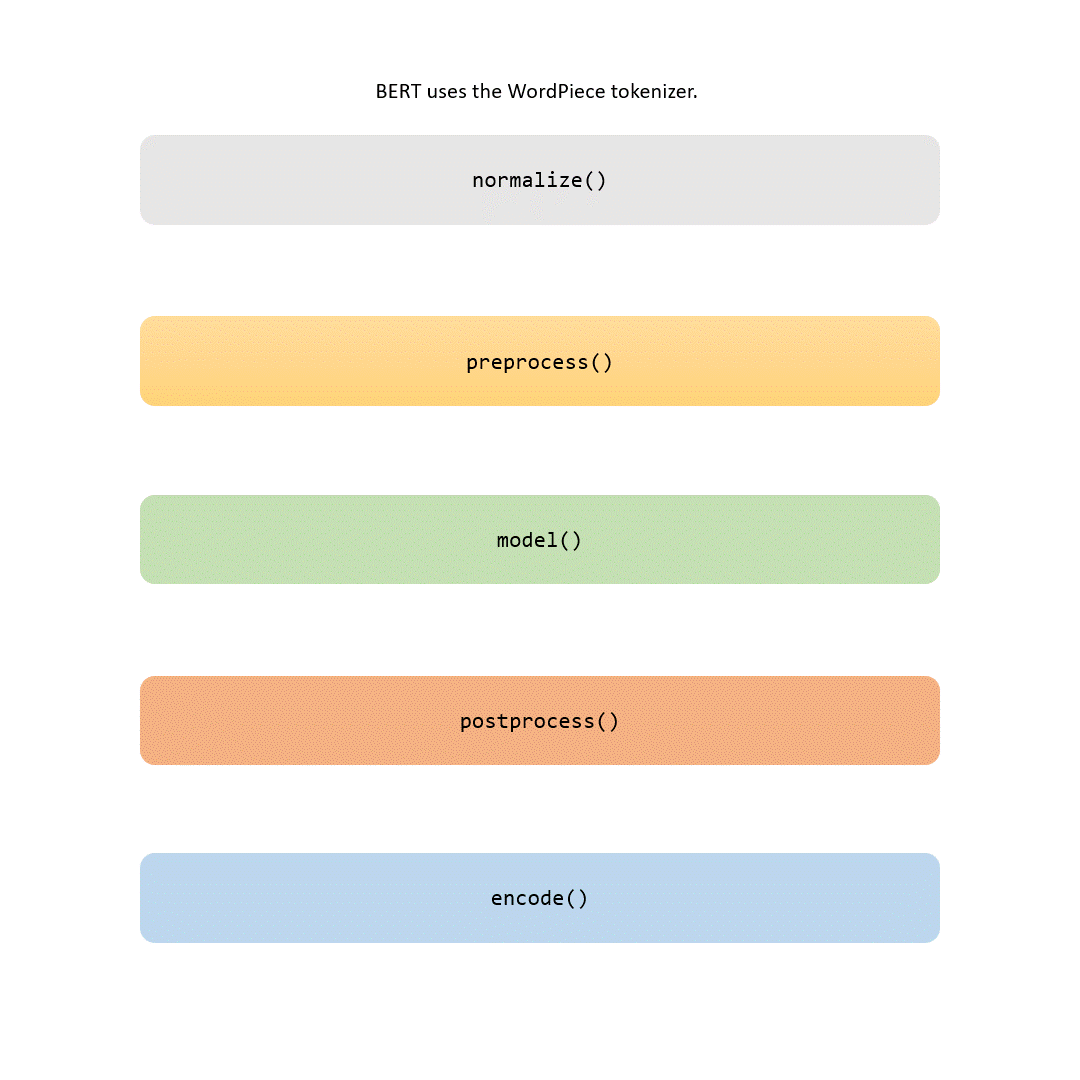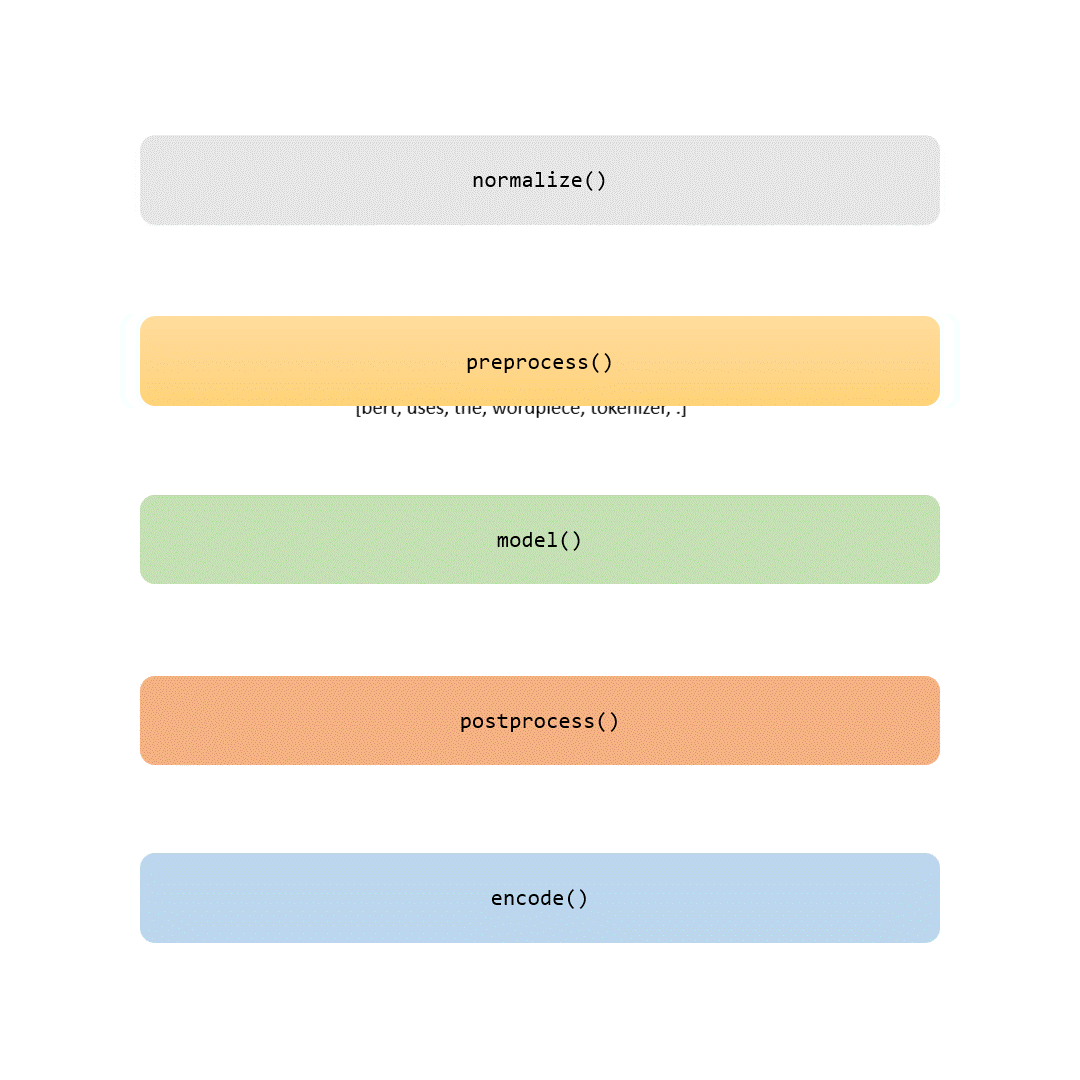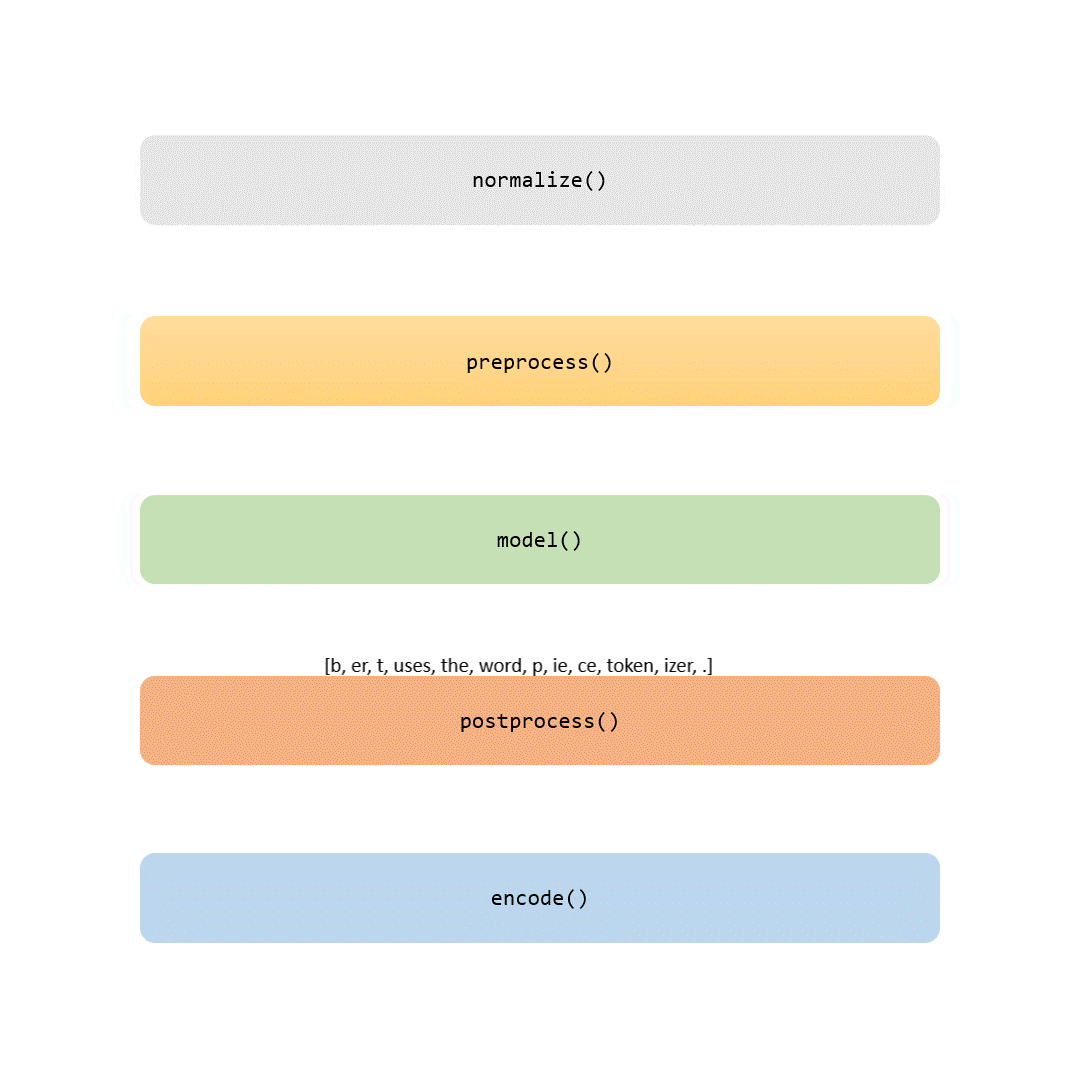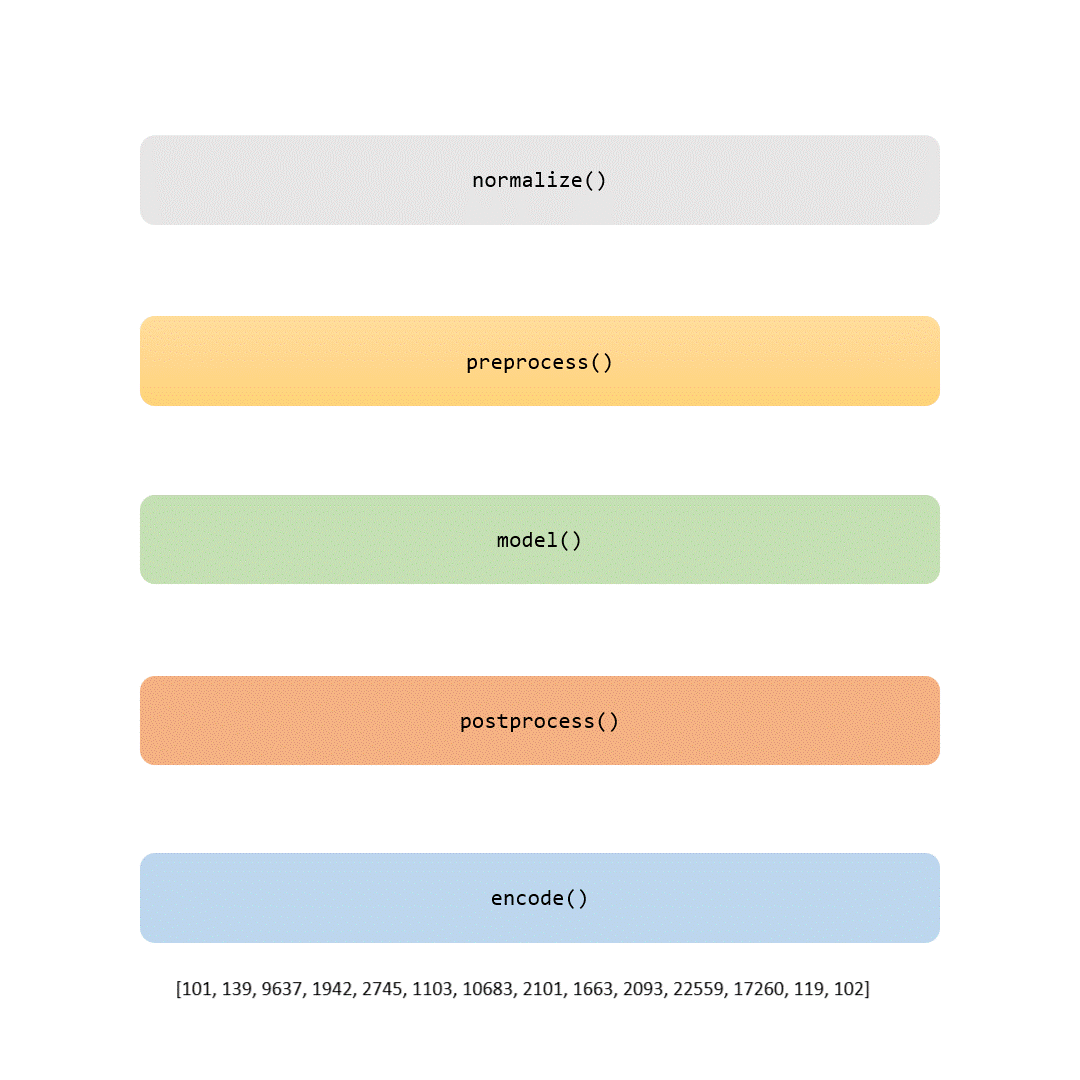
在这个故事中,我们将检查标记化管道的每个部分。有些步骤是微不足道的(如标准化和预处理),而其他步骤(如建模部分)则使每个标记生成器独一无二。
当您读完本文时,您不仅会了解 BERT 分词器的详细信息,而且还能够根据自己的数据对其进行训练。如果您喜欢冒险,您甚至可以使用工具在从头开始训练您自己的 BERT 模型时自定义这一关键步骤。
将文本分割成标记,这不是一件苦差事;它是将语言转化为可操作的情报的门户。
那么,为什么代币化如此重要?从本质上讲,标记化是一个翻译器;它接收人类语言并将其翻译成机器可以理解的语言:数字。但有一个问题:在这个翻译过程中,分词器必须保持关键的平衡,找到意义和计算