一、Python—使用pytorch
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# 定义要逼近的函数
def f(x):
return np.sin(5*x) * (1 - np.tanh(x**2)) + np.random.randn(*x.shape) * 0.1
# 定义MLP模型
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 训练模型
def train_model(self, x_train, y_train, learning_rate, epochs):
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(self.parameters(), lr=learning_rate)
for epoch in range(epochs):
inputs = torch.from_numpy(x_train).float().unsqueeze(1)
targets = torch.from_numpy(y_train).float().unsqueeze(1)
optimizer.zero_grad()
outputs = self(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
# 评估模型
def evaluate_model(self, x_test, y_test):
self.eval()
with torch.no_grad():
inputs = torch.from_numpy(x_test).float().unsqueeze(1)
outputs = self(inputs)
y_pred = outputs.squeeze().numpy()
return y_pred
# 生成训练数据
x_train = np.linspace(-2, 2, 1000)
y_train = f(x_train)
# 训练模型
model = MLP(input_size=1, hidden_size=10, output_size=1)
model.train_model(x_train, y_train, learning_rate=0.01, epochs=1000)
# 生成测试数据
x_test = np.linspace(-2, 2, 1000)
y_test = f(x_test)
# 评估模型
y_pred = model.evaluate_model(x_test, y_test)
# 绘制结果
plt.plot(x_train, y_train, '.', label='Training data')
plt.plot(x_test, y_test, label='Test data')
plt.plot(x_test, y_pred, label='Predictions')
plt.legend()
plt.show()
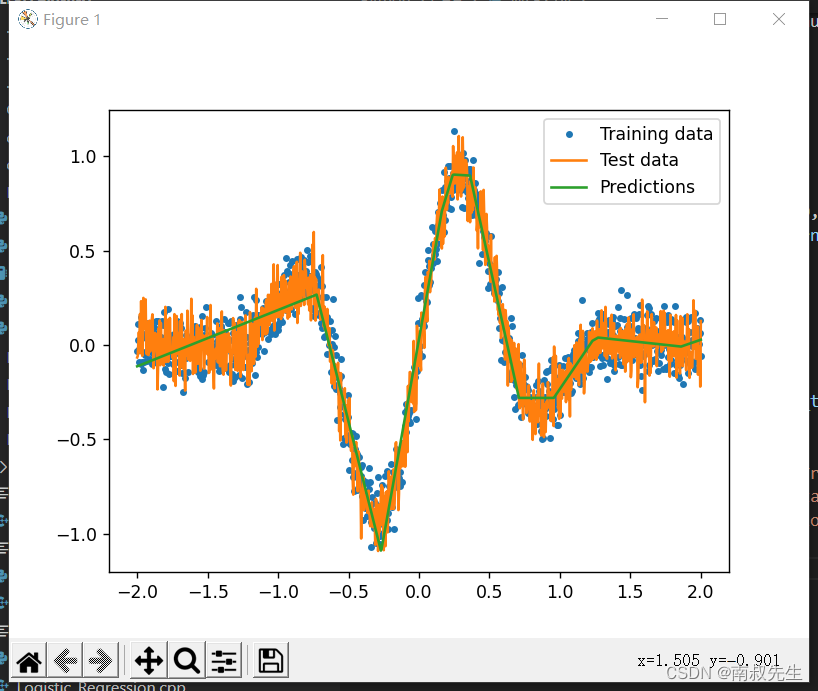
二、Python—直接定义
import numpy as np
import random
class MLP:
def __init__(self, input_size, hidden_size, output_size, learning_rate, regularization_rate, activation_function, dropout_rate):
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.learning_rate = learning_rate
self.regularization_rate = regularization_rate
self.activation_function = activation_function
self.dropout_rate = dropout_rate
self.input_weights = np.random.uniform(-0.5, 0.5, (hidden_size, input_size))
self.input_bias = np.random.uniform(-0.5, 0.5, hidden_size)
self.hidden_weights = np.random.uniform(-0.5, 0.5, (output_size, hidden_size))
self.hidden_bias = np.random.uniform(-0.5, 0.5, output_size)
def activation(self, x):
if self.activation_function == "relu":
return max(0.0, x)
elif self.activation_function == "sigmoid":
return 1 / (1 + np.exp(-x))
elif self.activation_function == "tanh":
return np.tanh(x)
else:
return x
def activation_derivative(self, x):
if self.activation_function == "relu":
if x > 0:
return 1
else:
return 0
elif self.activation_function == "sigmoid":
return np.exp(-x) / np.power(1 + np.exp(-x), 2)
elif self.activation_function == "tanh":
return 1 - np.power(np.tanh(x), 2)
else:
return 1
def predict(self, input):
hidden = np.zeros(self.hidden_size)
for i in range(self.hidden_size):
sum = 0
for j in range(self.input_size):
sum += self.input_weights[i][j] * input[j]
hidden[i] = self.activation(sum + self.input_bias[i])
output = np.zeros(self.output_size)
for i in range(self.output_size):
sum = 0
for j in range(self.hidden_size):
sum += self.hidden_weights[i][j] * hidden[j]
output[i] = self.activation(sum + self.hidden_bias[i])
return output
def train(self, inputs, targets, batch_size):
num_batches = len(inputs) // batch_size
for i in range(num_batches):
batch_inputs = inputs[i * batch_size:(i + 1) * batch_size]
batch_targets = targets[i * batch_size:(i + 1) * batch_size]
hidden = np.zeros((batch_size, self.hidden_size))
output = np.zeros((batch_size, self.output_size))
for j in range(batch_size):
for k in range(self.hidden_size):
sum = 0
for l in range(self.input_size):
sum += self.input_weights[k][l] * batch_inputs[j][l]
hidden[j][k] = self.activation(sum + self.input_bias[k])
for j in range(batch_size):
for k in range(self.output_size):
sum = 0
for l in range(self.hidden_size):
sum += self.hidden_weights[k][l] * hidden[j][l]
output[j][k] = self.activation(sum + self.hidden_bias[k])
output_error = np.zeros((batch_size, self.output_size))
hidden_error = np.zeros((batch_size, self.hidden_size))
for j in range(batch_size):
for k in range(self.output_size):
output_error[j][k] = (batch_targets[j][k] - output[j][k]) * self.activation_derivative(output[j][k])
for j in range(batch_size):
for k in range(self.hidden_size):
sum = 0
for l in range(self.output_size):
sum += output_error[j][l] * self.hidden_weights[l][k]
hidden_error[j][k] = sum * self.activation_derivative(hidden[j][k])
for j in range(self.output_size):
for k in range(self.hidden_size):
weight_gradient = 0
for l in range(batch_size):
weight_gradient += hidden[l][k] * output_error[l][j]
self.hidden_weights[j][k] += self.learning_rate * weight_gradient / batch_size - self.regularization_rate * self.hidden_weights[j][k]
bias_gradient = 0
for k in range(batch_size):
bias_gradient += output_error[k][j]
self.hidden_bias[j] += self.learning_rate * bias_gradient / batch_size
for j in range(self.hidden_size):
for k in range(self.input_size):
if random.random() < self.dropout_rate:
self.input_weights[j][k] = 0
if random.random() < self.dropout_rate:
self.input_bias[j] = 0
for j in range(self.hidden_size):
for k in range(self.input_size):
weight_gradient = 0
for l in range(batch_size):
weight_gradient += batch_inputs[l][k] * hidden_error[l][j]
self.input_weights[j][k] += self.learning_rate * weight_gradient / batch_size - self.regularization_rate * self.input_weights[j][k]
bias_gradient = 0
for k in range(batch_size):
bias_gradient += hidden_error[k][j]
self.input_bias[j] += self.learning_rate * bias_gradient / batch_size
def evaluate(self, inputs, targets):
error = 0
for i in range(len(inputs)):
output = self.predict(inputs[i])
for j in range(self.output_size):
error += np.power(targets[i][j] - output[j], 2)
return error / len(inputs)
def generate_training_data():
inputs = []
targets = []
for x in np.arange(-1, 1.1, 0.1):
y = pow(x, 3) + 0.5 * x + 0.2
inputs.append([x])
targets.append([y])
return inputs, targets
if __name__ == "__main__":
input_size = 1
hidden_size = 10
output_size = 1
learning_rate = 0.01
regularization_rate = 0.0001
activation_function = "relu"
dropout_rate = 0.5
mlp = MLP(input_size, hidden_size, output_size, learning_rate, regularization_rate, activation_function, dropout_rate)
inputs, targets = generate_training_data()
batch_size = 10
epochs = 1000
for i in range(epochs):
mlp.train(inputs, targets, batch_size)
print("Error: ", mlp.evaluate(inputs, targets))
for x in np.arange(-1, 1.1, 0.1):
input = [x]
output = mlp.predict(input)
print("inputs: ", x, " targets: ", pow(x, 3) + 0.5 * x + 0.2, " output: ", output[0])
import matplotlib.pyplot as plt
x = np.arange(-1, 1.1, 0.1)
y_true = [pow(i, 3) + 0.5 * i + 0.2 for i in x]
y_pred = [mlp.predict([i])[0] for i in x]
plt.plot(x, y_true, label='True')
plt.plot(x, y_pred, label='Predicted')
plt.legend()
plt.show()
二、C++
#include <iostream>
#include <vector>
#include <cmath>
#include <random>
using namespace std;
class MLP
{
private:
int input_size; // 输入层大小
int hidden_size; // 隐藏层大小
int output_size; // 输出层大小
vector<vector<double>> input_weights; // 输入层到隐藏层的权重
vector<double> input_bias; // 输入层到隐藏层的偏置
vector<vector<double>> hidden_weights; // 隐藏层到输出层的权重
vector<double> hidden_bias; // 隐藏层到输出层的偏置
double learning_rate; // 学习率
double regularization_rate; // 正则化率
string activation_function; // 激活函数
double dropout_rate; // dropout率
public:
MLP(int input_size, int hidden_size, int output_size, double learning_rate, double regularization_rate, string activation_function, double dropout_rate)
{
this->input_size = input_size; // 初始化输入层大小
this->hidden_size = hidden_size; // 初始化隐藏层大小
this->output_size = output_size; // 初始化输出层大小
this->learning_rate = learning_rate; // 初始化学习率
this->regularization_rate = regularization_rate; // 初始化正则化率
this->activation_function = activation_function; // 初始化激活函数
this->dropout_rate = dropout_rate; // 初始化dropout率
// 初始化输入层到隐藏层的权重和偏置
input_weights.resize(hidden_size, vector<double>(input_size)); // 初始化输入层到隐藏层的权重
input_bias.resize(hidden_size); // 初始化输入层到隐藏层的偏置
random_device rd; // 随机数生成器
mt19937 gen(rd()); // 随机数生成器
uniform_real_distribution<> dis(-0.5, 0.5); // 均匀分布
for (int i = 0; i < hidden_size; i++)
{
for (int j = 0; j < input_size; j++)
{
input_weights[i][j] = dis(gen); // 随机初始化权重
}
input_bias[i] = dis(gen); // 随机初始化偏置
}
// 初始化隐藏层到输出层的权重和偏置
hidden_weights.resize(output_size, vector<double>(hidden_size)); // 初始化隐藏层到输出层的权重
hidden_bias.resize(output_size); // 初始化隐藏层到输出层的偏置
for (int i = 0; i < output_size; i++)
{
for (int j = 0; j < hidden_size; j++)
{
hidden_weights[i][j] = dis(gen); // 随机初始化权重
}
hidden_bias[i] = dis(gen); // 随机初始化偏置
}
}
double activation(double x) // 激活函数
{
if (activation_function == "relu")
{
return max(0.0, x);
}
else if (activation_function == "sigmoid")
{
return 1 / (1 + exp(-x));
}
else if (activation_function == "tanh")
{
return tanh(x);
}
else
{
return x;
}
}
double activation_derivative(double x) // 激活函数的导数
{
if (activation_function == "relu")
{
if (x > 0)
{
return 1;
}
else
{
return 0;
}
}
else if (activation_function == "sigmoid")
{
return exp(-x) / pow(1 + exp(-x), 2);
}
else if (activation_function == "tanh")
{
return 1 - pow(tanh(x), 2);
}
else
{
return 1;
}
}
vector<double> predict(vector<double> input) // 预测函数
{
// 计算隐藏层的值
vector<double> hidden(hidden_size);
for (int i = 0; i < hidden_size; i++)
{
double sum = 0;
for (int j = 0; j < input_size; j++)
{
sum += input_weights[i][j] * input[j];
}
hidden[i] = activation(sum + input_bias[i]); // 计算隐藏层的值
}
// 计算输出层的值
vector<double> output(output_size);
for (int i = 0; i < output_size; i++)
{
double sum = 0;
for (int j = 0; j < hidden_size; j++)
{
sum += hidden_weights[i][j] * hidden[j];
}
output[i] = activation(sum + hidden_bias[i]); // 计算输出层的值
}
return output;
}
void train(vector<vector<double>> inputs, vector<vector<double>> targets, int batch_size) // 训练函数
{
int num_batches = inputs.size() / batch_size;
for (int i = 0; i < num_batches; i++)
{
vector<vector<double>> batch_inputs(inputs.begin() + i * batch_size, inputs.begin() + (i + 1) * batch_size);
vector<vector<double>> batch_targets(targets.begin() + i * batch_size, targets.begin() + (i + 1) * batch_size);
// 前向传播
vector<vector<double>> hidden(batch_size, vector<double>(hidden_size));
vector<vector<double>> output(batch_size, vector<double>(output_size));
// 计算隐藏层的值
for (int j = 0; j < batch_size; j++)
{
for (int k = 0; k < hidden_size; k++)
{
double sum = 0;
for (int l = 0; l < input_size; l++)
{
sum += input_weights[k][l] * batch_inputs[j][l];
}
hidden[j][k] = activation(sum + input_bias[k]); // 计算隐藏层的值
}
}
// 计算输出层的值
for (int j = 0; j < batch_size; j++)
{
for (int k = 0; k < output_size; k++)
{
double sum = 0;
for (int l = 0; l < hidden_size; l++)
{
sum += hidden_weights[k][l] * hidden[j][l];
}
output[j][k] = activation(sum + hidden_bias[k]); // 计算输出层的值
}
}
// 反向传播
vector<vector<double>> output_error(batch_size, vector<double>(output_size));
vector<vector<double>> hidden_error(batch_size, vector<double>(hidden_size));
// 计算输出层的误差
for (int j = 0; j < batch_size; j++)
{
for (int k = 0; k < output_size; k++)
{
output_error[j][k] = (batch_targets[j][k] - output[j][k]) * activation_derivative(output[j][k]); // 计算输出层的误差
}
}
// 计算隐藏层的误差
for (int j = 0; j < batch_size; j++)
{
for (int k = 0; k < hidden_size; k++)
{
double sum = 0;
for (int l = 0; l < output_size; l++)
{
sum += output_error[j][l] * hidden_weights[l][k];
}
hidden_error[j][k] = sum * activation_derivative(hidden[j][k]); // 计算隐藏层的误差
}
}
// 更新隐藏层到输出层的权重和偏置
for (int j = 0; j < output_size; j++)
{
for (int k = 0; k < hidden_size; k++)
{
double weight_gradient = 0;
for (int l = 0; l < batch_size; l++)
{
weight_gradient += hidden[l][k] * output_error[l][j];
}
hidden_weights[j][k] += learning_rate * weight_gradient / batch_size - regularization_rate * hidden_weights[j][k]; // 更新隐藏层到输出层的权重
}
double bias_gradient = 0;
for (int k = 0; k < batch_size; k++)
{
bias_gradient += output_error[k][j];
}
hidden_bias[j] += learning_rate * bias_gradient / batch_size; // 更新隐藏层到输出层的偏置
}
// 添加dropout
for (int j = 0; j < hidden_size; j++)
{
for (int k = 0; k < input_size; k++)
{
if (rand() < dropout_rate * RAND_MAX)
{
input_weights[j][k] = 0;
}
}
if (rand() < dropout_rate * RAND_MAX)
{
input_bias[j] = 0;
}
}
// 更新输入层到隐藏层的权重和偏置
for (int j = 0; j < hidden_size; j++)
{
for (int k = 0; k < input_size; k++)
{
double weight_gradient = 0;
for (int l = 0; l < batch_size; l++)
{
weight_gradient += batch_inputs[l][k] * hidden_error[l][j];
}
input_weights[j][k] += learning_rate * weight_gradient / batch_size - regularization_rate * input_weights[j][k]; // 更新输入层到隐藏层的权重
}
double bias_gradient = 0;
for (int k = 0; k < batch_size; k++)
{
bias_gradient += hidden_error[k][j];
}
input_bias[j] += learning_rate * bias_gradient / batch_size; // 更新输入层到隐藏层的偏置
}
}
}
double evaluate(vector<vector<double>> inputs, vector<vector<double>> targets) // 评价函数
{
double error = 0;
for (int i = 0; i < inputs.size(); i++)
{
vector<double> output = predict(inputs[i]);
for (int j = 0; j < output_size; j++)
{
error += pow(targets[i][j] - output[j], 2);
}
}
return error / inputs.size();
}
};
void generate_training_data(vector<vector<double>> &inputs, vector<vector<double>> &targets)
{
for (double x = -1; x <= 1; x += 0.1)
{
double y = pow(x, 3) + 0.5 * x + 0.2;
inputs.push_back({x}); // 添加输入
targets.push_back({y}); // 添加目标
}
}
int main()
{
// 初始化MLP
int input_size = 1; // 输入层大小
int hidden_size = 10; // 隐藏层大小
int output_size = 1; // 输出层大小
double learning_rate = 0.01; // 学习率
double regularization_rate = 0.0001; // 正则化率
string activation_function = "relu"; // 激活函数
double dropout_rate = 0.5; // dropout率
MLP mlp(input_size, hidden_size, output_size, learning_rate, regularization_rate, activation_function, dropout_rate); // 创建MLP对象
// 生成数据
vector<vector<double>> inputs;
vector<vector<double>> targets;
generate_training_data(inputs, targets);
// 训练MLP
int batch_size = 10;
int epochs = 1000;
for (int i = 0; i < epochs; i++)
{
mlp.train(inputs, targets, batch_size); // 训练
cout << "Error: " << mlp.evaluate(inputs, targets) << endl; // 输出每次训练的误差
}
// 使用MLP进行预测
for (double x = -1; x <= 1; x += 0.1)
{
vector<double> input = {x};
vector<double> output = mlp.predict(input); // 预测
cout << "inputs: " << x << " targets: " << pow(x, 3) + 0.5 * x + 0.2 << " output: " << output[0] << endl; // 输出结果
}
return 0;
}