一、总结
1、最近邻搜索
(1)1NN
(2)KNN
TF-IDF,距离(欧氏距离,cosine),归一化,暴力搜索复杂度
(3)KD-trees

缺点:不易实现;高维特征难以实现
(4)LSH局部敏感哈希

扫描二维码关注公众号,回复:
1655677 查看本文章

2、k-means和MapReduce
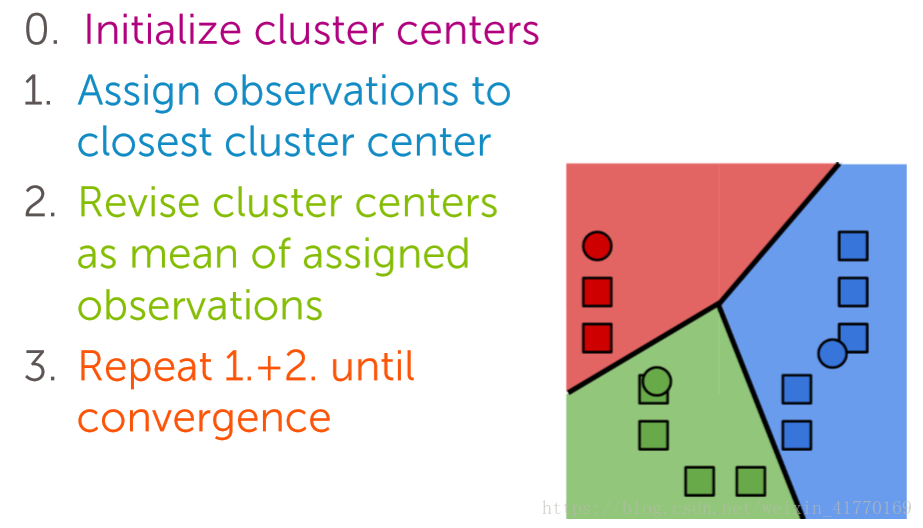

3、混合高斯模型和EM
k-means不能解决的:
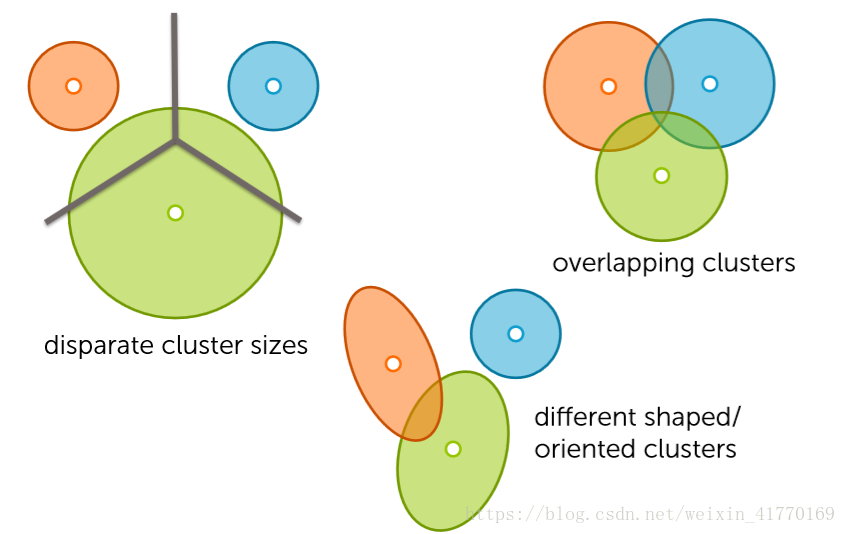
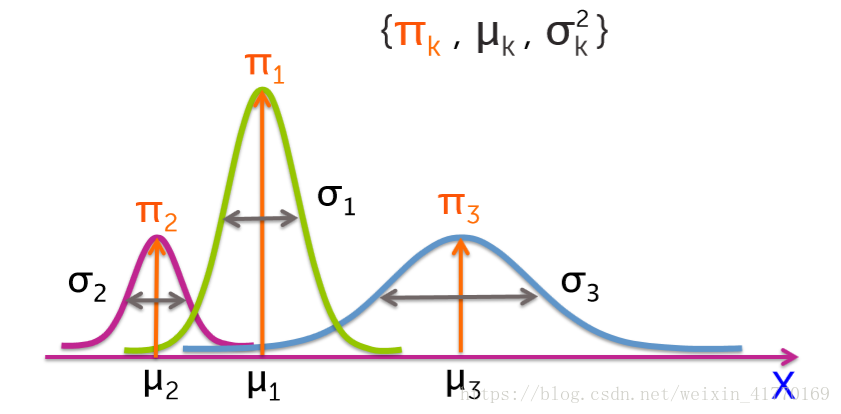

4、LDA

吉布斯采样
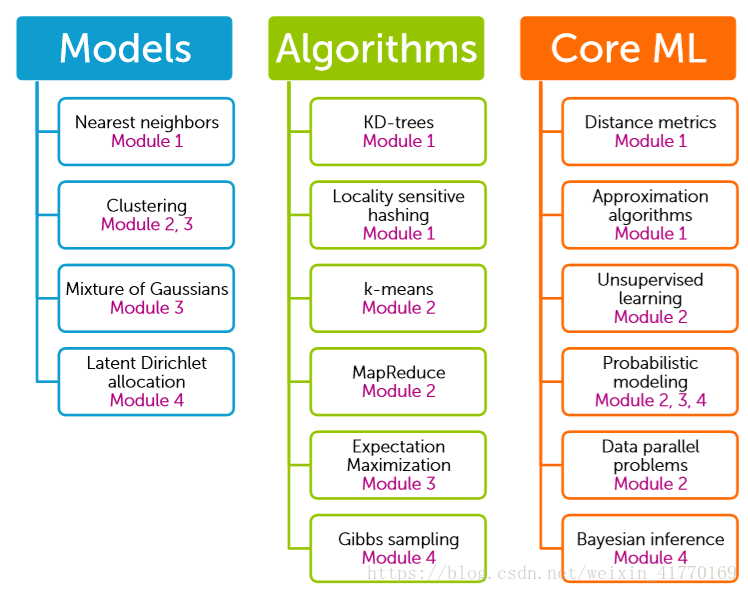
5、总结
二、分层聚类
优点:不需要选择k值;可视化聚类结构;可以使用任何距离矩阵,而k-means只能使用欧式距离

可以解决的形状更多:
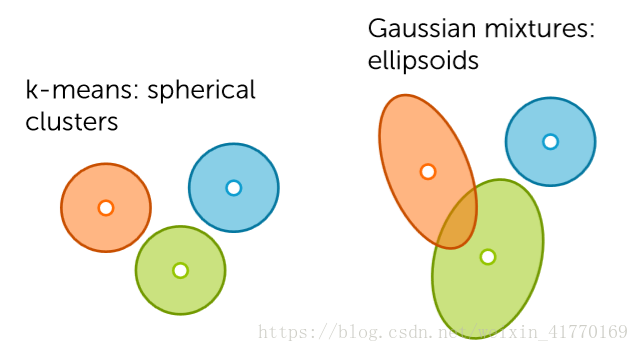
分层聚类可以解决如下:

两种主要算法:分裂cluster,成团
1、分裂:一开始认为是一整个cluster,然后逐渐分裂,直到N个点变成N个cluster
2、成团:一开始N个点认为是N个cluster,然后逐渐成团,最后变成1个cluster
1、分裂:递归k-means
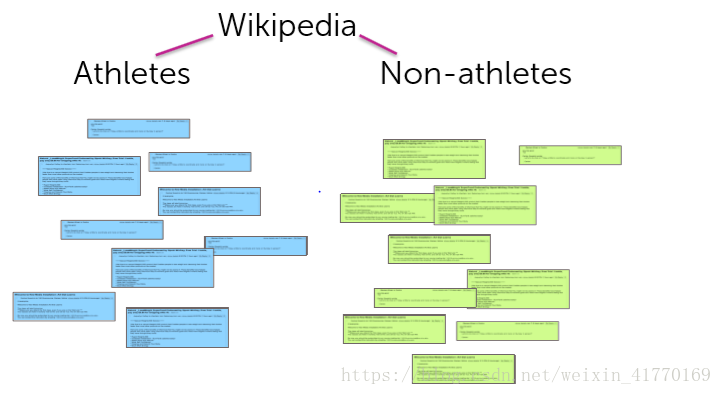
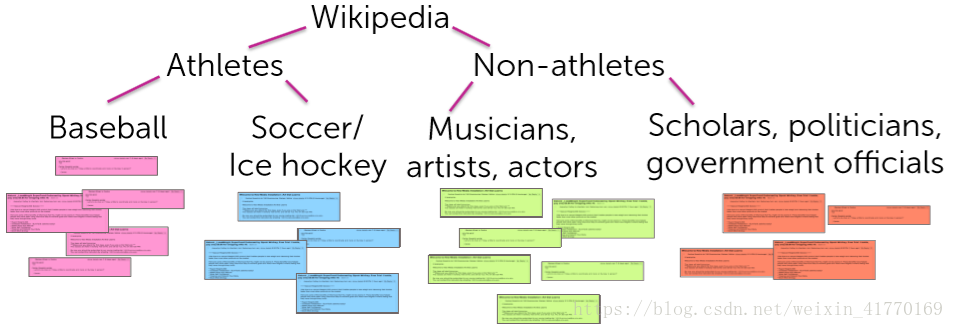
2、成团

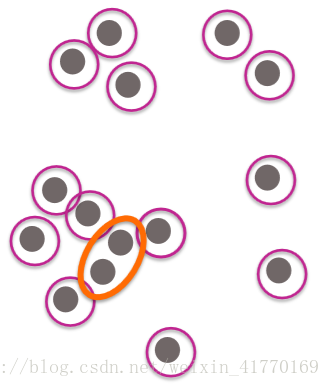
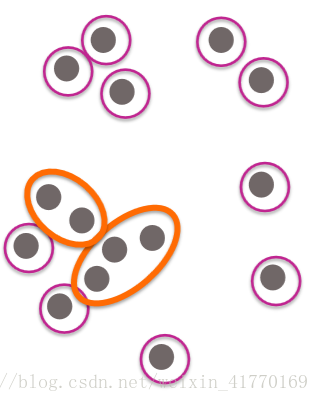



成团的系统结构图:


团的切割:

三、HMM:隐马尔可夫,也是一种聚类方法
之前的数据都是无序的。但是对于有序数据,比如:蜜蜂的飞行路径,舞步,消息散播路径。可以用HMM。